



开源MoE模型,终于迎来首位国产选手!
它的表现完全不输给密集的Llama 2-7B模型,计算量却仅有40%。
这个模型堪称19边形战士,特别是在数学和代码能力上对Llama形成了碾压。
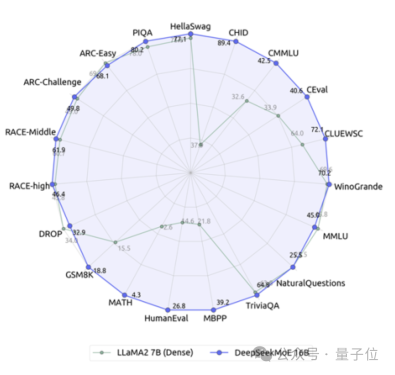
它就是深度求索团队最新开源的160亿参数专家模型DeepSeek MoE。
除了性能上表现优异,DeepSeek MoE主打的就是节约计算量。
在这张表现-激活参数量图中,它“一枝独秀”地占据了左上角的大片空白区。

发布仅一天,DeepSeek团队在X上的推文就有大量转发关注。
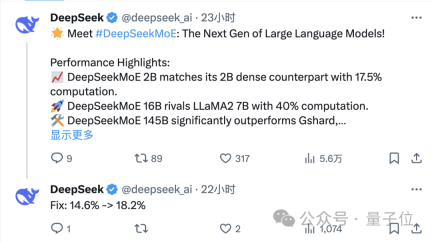
JP摩根的机器学习工程师Maxime Labonne测试后也表示,DeepSeek MoE的chat版本表现要略胜于微软的“小模型”Phi-2。
同时,DeepSeek MoE还在GitHub上获得了300+星标,并登上了Hugging Face文本生成类模型排行榜的首页。
那么,DeepSeek MoE的具体表现究竟怎么样呢?
计算量减少60%
DeepSeek MoE目前推出的版本参数量为160亿,实际激活参数量大约是28亿。
与自家的7B密集模型相比,二者在19个数据集上的表现各有胜负,但整体比较接近。
而与同为密集模型的Llama 2-7B相比,DeepSeek MoE在数学、代码等方面还体现出来明显的优势。
但两种密集模型的计算量都超过了180TFLOPs每4k token,DeepSeek MoE却只有74.4TFLOPs,只有两者的40%。

在20亿参数量时进行的性能测试显示,DeepSeek MoE同样能以更少的计算量,达到与1.5倍参数量、同为MoE模型的GShard 2.8B相当甚至更好的效果。
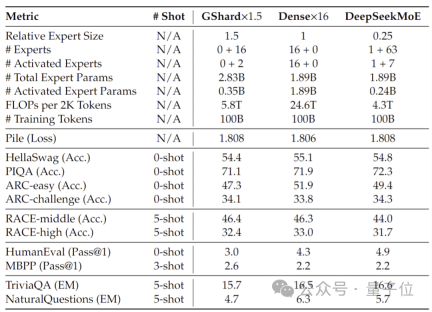
此外深度求索团队还基于SFT微调除了DeepSeek MoE的Chat版本,表现同样接近自家密集版本和Llama 2-7B。
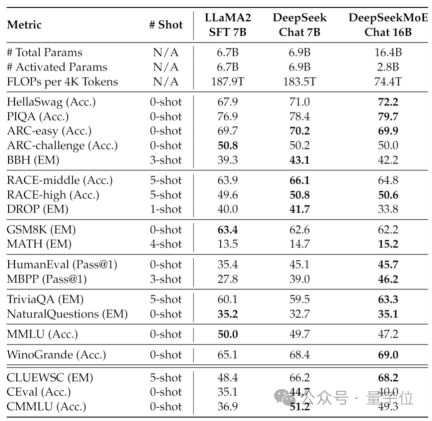
此外,深度求索团队还透露,DeepSeek MoE模型还有145B版本正在研发。
阶段性的初步试验显示,145B的DeepSeek MoE对GShard 137B具有极大的领先优势,同时能够以28.5%的计算量达到与密集版DeepSeek 67B模型相当的性能。
研发完毕后,团队也将对145B版本进行开源。
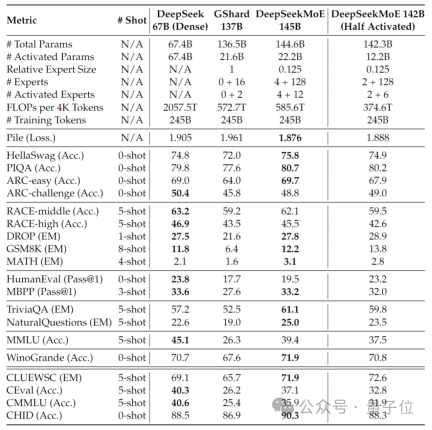
而在这些模型表现的背后,是DeepSeek全新的自研MoE架构。
自研MoE新架构
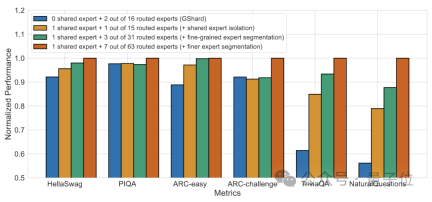
首先是相比于传统的MoE架构,DeepSeek拥有更细粒度专家划分。
在总参数量一定的情况下,传统模型分出N个专家,而DeepSeek可能分出2N个。
同时,每次执行任务时选择的专家数量也是传统模型的2倍,所以总体使用的参数量也不变,但选择的自由度增加了。
这种分割策略允许更灵活和适应性的激活专家组合,从而提高了模型在不同任务上的准确性和知识获取的针对性。

除了专家划分上的差异,DeepSeek还创新性地引入了“共享专家”的设置。
这些共享专家对所有输入的token激活,不受路由模块影响,目的是捕获和整合在不同上下文中都需要的共同知识。
通过将这些共享知识压缩到共享专家中,可以减少其他专家之间的参数冗余,从而提高模型的参数效率。
共享专家的设置有助于其他专家更加专注于其独特的知识领域,从而提高整体的专家专业化水平。
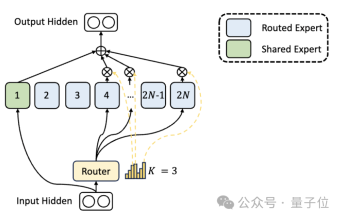
消融实验结果表明,这两个方案都为DeepSeek MoE的“降本增效”起到了重要作用。
论文地址:https://arxiv.org/abs/2401.06066。
参考链接:https://mp.weixin.qq.com/s/T9-EGxYuHcGQgXArLXGbgg。
以上是引入国产开源MoE大模型,其性能媲美Llama 2-7B,同时计算量减少了60%的详细内容。更多信息请关注PHP中文网其他相关文章!

 2023年机器学习的十大概念和技术Apr 04, 2023 pm 12:30 PM
2023年机器学习的十大概念和技术Apr 04, 2023 pm 12:30 PM机器学习是一个不断发展的学科,一直在创造新的想法和技术。本文罗列了2023年机器学习的十大概念和技术。 本文罗列了2023年机器学习的十大概念和技术。2023年机器学习的十大概念和技术是一个教计算机从数据中学习的过程,无需明确的编程。机器学习是一个不断发展的学科,一直在创造新的想法和技术。为了保持领先,数据科学家应该关注其中一些网站,以跟上最新的发展。这将有助于了解机器学习中的技术如何在实践中使用,并为自己的业务或工作领域中的可能应用提供想法。2023年机器学习的十大概念和技术:1. 深度神经网
 人工智能自动获取知识和技能,实现自我完善的过程是什么Aug 24, 2022 am 11:57 AM
人工智能自动获取知识和技能,实现自我完善的过程是什么Aug 24, 2022 am 11:57 AM实现自我完善的过程是“机器学习”。机器学习是人工智能核心,是使计算机具有智能的根本途径;它使计算机能模拟人的学习行为,自动地通过学习来获取知识和技能,不断改善性能,实现自我完善。机器学习主要研究三方面问题:1、学习机理,人类获取知识、技能和抽象概念的天赋能力;2、学习方法,对生物学习机理进行简化的基础上,用计算的方法进行再现;3、学习系统,能够在一定程度上实现机器学习的系统。
 超参数优化比较之网格搜索、随机搜索和贝叶斯优化Apr 04, 2023 pm 12:05 PM
超参数优化比较之网格搜索、随机搜索和贝叶斯优化Apr 04, 2023 pm 12:05 PM本文将详细介绍用来提高机器学习效果的最常见的超参数优化方法。 译者 | 朱先忠审校 | 孙淑娟简介通常,在尝试改进机器学习模型时,人们首先想到的解决方案是添加更多的训练数据。额外的数据通常是有帮助(在某些情况下除外)的,但生成高质量的数据可能非常昂贵。通过使用现有数据获得最佳模型性能,超参数优化可以节省我们的时间和资源。顾名思义,超参数优化是为机器学习模型确定最佳超参数组合以满足优化函数(即,给定研究中的数据集,最大化模型的性能)的过程。换句话说,每个模型都会提供多个有关选项的调整“按钮
 得益于OpenAI技术,微软必应的搜索流量超过谷歌Mar 31, 2023 pm 10:38 PM
得益于OpenAI技术,微软必应的搜索流量超过谷歌Mar 31, 2023 pm 10:38 PM截至3月20日的数据显示,自微软2月7日推出其人工智能版本以来,必应搜索引擎的页面访问量增加了15.8%,而Alphabet旗下的谷歌搜索引擎则下降了近1%。 3月23日消息,外媒报道称,分析公司Similarweb的数据显示,在整合了OpenAI的技术后,微软旗下的必应在页面访问量方面实现了更多的增长。截至3月20日的数据显示,自微软2月7日推出其人工智能版本以来,必应搜索引擎的页面访问量增加了15.8%,而Alphabet旗下的谷歌搜索引擎则下降了近1%。这些数据是微软在与谷歌争夺生
 荣耀的人工智能助手叫什么名字Sep 06, 2022 pm 03:31 PM
荣耀的人工智能助手叫什么名字Sep 06, 2022 pm 03:31 PM荣耀的人工智能助手叫“YOYO”,也即悠悠;YOYO除了能够实现语音操控等基本功能之外,还拥有智慧视觉、智慧识屏、情景智能、智慧搜索等功能,可以在系统设置页面中的智慧助手里进行相关的设置。
 人工智能在教育领域的应用主要有哪些Dec 14, 2020 pm 05:08 PM
人工智能在教育领域的应用主要有哪些Dec 14, 2020 pm 05:08 PM人工智能在教育领域的应用主要有个性化学习、虚拟导师、教育机器人和场景式教育。人工智能在教育领域的应用目前还处于早期探索阶段,但是潜力却是巨大的。
 30行Python代码就可以调用ChatGPT API总结论文的主要内容Apr 04, 2023 pm 12:05 PM
30行Python代码就可以调用ChatGPT API总结论文的主要内容Apr 04, 2023 pm 12:05 PM阅读论文可以说是我们的日常工作之一,论文的数量太多,我们如何快速阅读归纳呢?自从ChatGPT出现以后,有很多阅读论文的服务可以使用。其实使用ChatGPT API非常简单,我们只用30行python代码就可以在本地搭建一个自己的应用。 阅读论文可以说是我们的日常工作之一,论文的数量太多,我们如何快速阅读归纳呢?自从ChatGPT出现以后,有很多阅读论文的服务可以使用。其实使用ChatGPT API非常简单,我们只用30行python代码就可以在本地搭建一个自己的应用。使用 Python 和 C
 人工智能在生活中的应用有哪些Jul 20, 2022 pm 04:47 PM
人工智能在生活中的应用有哪些Jul 20, 2022 pm 04:47 PM人工智能在生活中的应用有:1、虚拟个人助理,使用者可通过声控、文字输入的方式,来完成一些日常生活的小事;2、语音评测,利用云计算技术,将自动口语评测服务放在云端,并开放API接口供客户远程使用;3、无人汽车,主要依靠车内的以计算机系统为主的智能驾驶仪来实现无人驾驶的目标;4、天气预测,通过手机GPRS系统,定位到用户所处的位置,在利用算法,对覆盖全国的雷达图进行数据分析并预测。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

SublimeText3汉化版
中文版,非常好用

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

Dreamweaver CS6
视觉化网页开发工具

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

