
探析OCR识别的原理和应用场景

- 王林转载
- 2024-01-14 22:36:051360浏览

Labs 导读
日常生活中,截图提取和拍照搜题都广泛应用了OCR(光学字符识别)技术,这是文字识别领域中非常重要的一项技术
Part 01、 什么是OCR
OCR(光学字符识别)是一种计算机文字识别的方法,利用光学和计算机技术将印刷或手写的文字影像转换成准确可读的文本格式,以供计算机识别和应用。OCR识别技术在现代生活的各个行业中得到越来越广泛的应用,它是实现快速将文字内容输入计算机的关键技术
Part 02、 OCR技术原理
OCR技术主要分为传统OCR和深度学习OCR两个流派。
在OCR技术发展早期,技术人员使用如二值化、连通域分析和投影分析等图像处理技术,结合统计机器学习(如Adaboost和SVM)来提取图像文本内容,我们将其统一归类为传统型OCR,其主要特征在于依赖繁杂的数据预处理操作来对图像进行矫正和降噪,面对复杂场景适应性的重要性不可忽视。在不断变化的环境中,适应性是一种关键的能力。一个拥有良好适应性的人能够适应新的情况和要求,快速地适应变化,并找到解决问题的方法。适应性也是一个人在个人和职业生活中成功的关键因素之一。因此,我们应该努力培养和提高自己的适应性,以应对不断变化的世界较差,准确率和响应速度也不尽如人意。
得益于AI技术不断发展,基于端到端深度学习OCR技术逐渐成熟,该方法优势在于无需明确地引入图像预处理阶段中的文字切割环节,而是将文字识别转化为序列学习问题,使文字分割融入深度学习中,对OCR技术完善和未来发展方向具有重要意义。
2.1 传统OCR识别流程
传统OCR技术处理流程图如下:

图像预处理:文本影像经过设备扫描之后进入预处理阶段,由于各种文本介质存在干扰因素,如纸张的光洁度和印刷质量,屏幕的光线明暗等都会造成文字畸变,因此需要对图像进行亮度调整、图像增强和噪声滤波等预处理手段。
文本区域定位:对于文本区域进行定位提取,方法主要包括连通域检测和MSER检测。
文本图像矫正:对于倾斜文本进行矫正,确保水平,矫正的办法主要包括水平矫正和透视矫正。
行列单字切分:传统的文本识别都是基于单字符的识别,分割方法主要利用连通域轮廓和垂直投影切割。
分类器字符识别:运用HOG、Sift等特征提取算法对字符进行向量信息提取,使用SVM算法、逻辑回归、支持向量机等进行训练。
后处理:由于分类器的分类不一定完全正确,或者在字符切割过程当中存在失误,所以需要基于统计语言模型(如隐马尔科夫链,HMM)或者人为提取规则设计语言规则模型对文本结果进行语义纠错。
2.2 深度学习OCR
 图片
图片
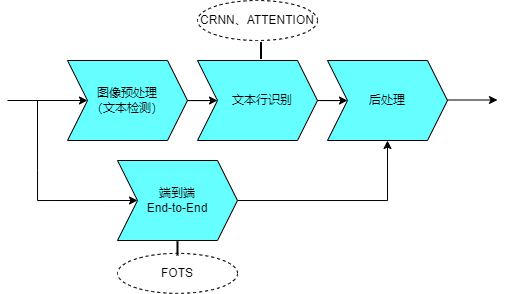
当前主流的深度学习OCR算法将文本检测和文本识别两个阶段分别建模。
文本检测可以分为基于回归和基于分割的方法。回归方法包括CTPN、Textbox和EAST等算法,可以检测图像中有方向的文字,但会受到文本区域不规则的影响。分割方法例如PSENet算法,可以处理各种形状和大小的文本,但较近的文本容易出现粘行问题。不同方法各有优劣之处
文本识别阶段主要使用CRNN、ATTENTION两大类技术,将文字识别转化为序列学习问题,两种技术在其特征学习阶段都采用了 CNN+RNN 的网络结构,不同之处在于最后的输出层(翻译层),即如何把网络学习到的序列特征信息转化为最终的识别结果。
另外,还有一种最新的端到端算法,它直接将文本检测和文本识别融合到单个网络模型中进行学习。例如,FOTS、Mask TextSpotter等算法。与独立的文本检测和文本识别方法相比,这种算法的识别速度更快,但相对精度较弱
2.3方案对比
传统型识别 |
人工智能的深度学习识别技术 |
|
|
底层 算法 |
文本检测、识别分为多个阶段和子过程,使用不同算法组合 |
这个模型的目标是融合检测和识别的过程,实现端到端 |
稳定性 |
多阶段整体稳定性较差 |
经过端到端的优化,系统的稳定性有了显着的提升 |
|
识别 精度 |
小样本传统场景在精度不高的情况下具有一定优势 |
精度较高,融合程度越深,精度逐渐降低 |
|
识别 速度 |
识别较慢 |
速度较快的识别 |
|
场景 适应性的重要性不可忽视。在不断变化的环境中,适应性是一种关键的能力。一个拥有良好适应性的人能够适应新的情况和要求,快速地适应变化,并找到解决问题的方法。适应性也是一个人在个人和职业生活中成功的关键因素之一。因此,我们应该努力培养和提高自己的适应性,以应对不断变化的世界 |
弱,适用标准印刷格式 |
强,兼容复杂场景,依赖模型训练 |
抗干扰性 |
弱,对于输入图像要求较高 |
强,依赖模型训练 |
Part 03、 OCR常用评估指标
召回率:指OCR系统正确识别出的字符数量与实际字符数量的比例,用于衡量系统是否漏识别了一些字符。该值越高,表明系统对字符的覆盖能力越好。
精确率:指OCR系统正确识别出的字符数量与系统总识别出的字符数量的比例,用于衡量系统的识别结果中有多少是真正正确的,该值越高,表明系统的识别结果更可靠。
F1值:综合了召回率和精确率的评价指标,F1 值介于 0 到 1 之间,该值越高,表示系统在准确率和召回率之间取得了更好的平衡。
平均编辑距离(Average Edit Distance)是用来评估OCR识别结果与真实文本之间差异程度的指标
Part 04、 应用和展望
OCR作为文字识别领域的主要分支之一,未来仍然有很广阔的研究方向和发展空间。在识别准确率方面,研究更智能的图像处理技术和更强大的深度学习模型仍然迫切;在多语种多字体的覆盖上要求识别更具有普适性,并增强复杂场景适配能力;在实时识别方面,寻找更多与虚拟现实技术和增强现实技术相结合的应用点,如AR翻译、文本数据的自动纠错和数据校正等。
以上是探析OCR识别的原理和应用场景的详细内容。更多信息请关注PHP中文网其他相关文章!