


近日,arxiv 上发布了一篇论文,对 Transformer 的数学原理进行全新解读,内容很长,知识很多,十二分建议阅读原文。

 在时间间隔 (0,T) 上会按照给定的时变速度场
在时间间隔 (0,T) 上会按照给定的时变速度场  进行演化。因此,DNN 可以看作是从一个
进行演化。因此,DNN 可以看作是从一个  到另一个
到另一个 的流映射(Flow Map)
的流映射(Flow Map) 。即使在经典 DNN 架构限制下的速度场
。即使在经典 DNN 架构限制下的速度场 中,流映射之间也具有很强的相似性。
中,流映射之间也具有很强的相似性。 上的流映射,即 d 维概率测度空间(the space of probability measures)间的映射。为了实现这种在度量空间间进行转换的流映射,Transformers 需要建立了一个平均场相互作用的粒子系统(mean-field interacting particle system.)。
上的流映射,即 d 维概率测度空间(the space of probability measures)间的映射。为了实现这种在度量空间间进行转换的流映射,Transformers 需要建立了一个平均场相互作用的粒子系统(mean-field interacting particle system.)。


 的空间内部,而自注意力机制则是通过经验度量实现粒子之间的非线性耦合。反过来,经验度量根据连续性偏微分方程进行演化。本文还为自注意引入了一个更简单好用的替代模型,一个能量函数的 Wasserstein 梯度流,而能量函数在球面上点的最优配置已经有成熟的研究方法。
的空间内部,而自注意力机制则是通过经验度量实现粒子之间的非线性耦合。反过来,经验度量根据连续性偏微分方程进行演化。本文还为自注意引入了一个更简单好用的替代模型,一个能量函数的 Wasserstein 梯度流,而能量函数在球面上点的最优配置已经有成熟的研究方法。 时聚成一个点。研究者对粒子集群收缩率的精确描述对这一结果进行了补充说明。具体来说,研究者绘制了所有粒子间距离的直方图,以及所有粒子快要完成聚类的时间点(见原文第 4 节)。研究者还在不假设维数 d 较大的情况下就得到了聚类结果(见原文第 5 节)。
时聚成一个点。研究者对粒子集群收缩率的精确描述对这一结果进行了补充说明。具体来说,研究者绘制了所有粒子间距离的直方图,以及所有粒子快要完成聚类的时间点(见原文第 4 节)。研究者还在不假设维数 d 较大的情况下就得到了聚类结果(见原文第 5 节)。以上是揭秘的全新版本:你从未见过的Transformer数学原理的详细内容。更多信息请关注PHP中文网其他相关文章!

 五个时间序列预测的深度学习模型对比总结May 05, 2023 pm 05:16 PM
五个时间序列预测的深度学习模型对比总结May 05, 2023 pm 05:16 PMMakridakisM-Competitions系列(分别称为M4和M5)分别在2018年和2020年举办(M6也在今年举办了)。对于那些不了解的人来说,m系列得比赛可以被认为是时间序列生态系统的一种现有状态的总结,为当前得预测的理论和实践提供了经验和客观的证据。2018年M4的结果表明,纯粹的“ML”方法在很大程度上胜过传统的统计方法,这在当时是出乎意料的。在两年后的M5[1]中,最的高分是仅具有“ML”方法。并且所有前50名基本上都是基于ML的(大部分是树型模型)。这场比赛看到了LightG
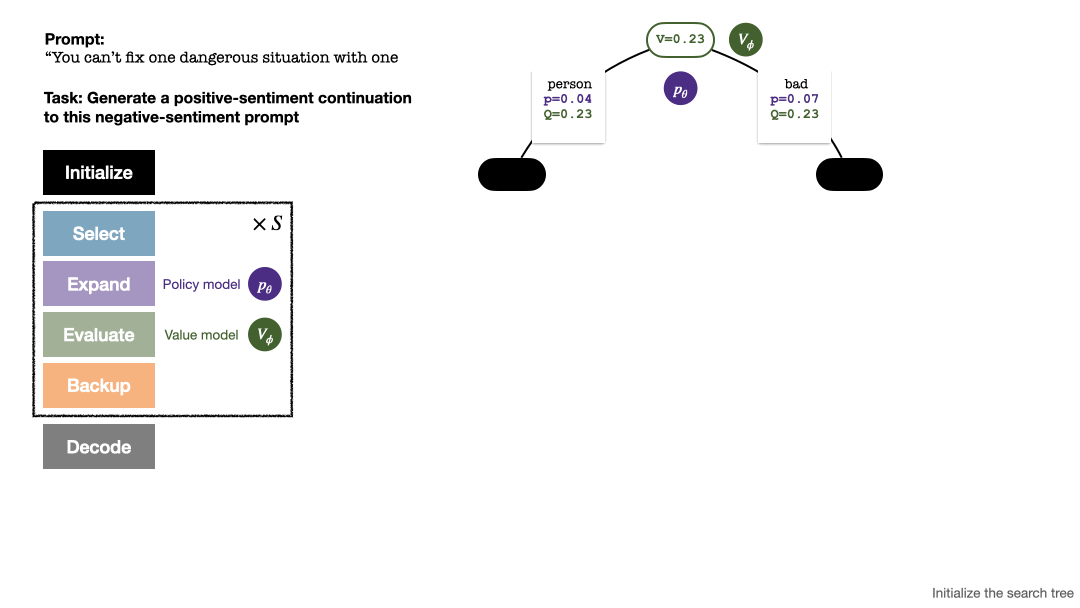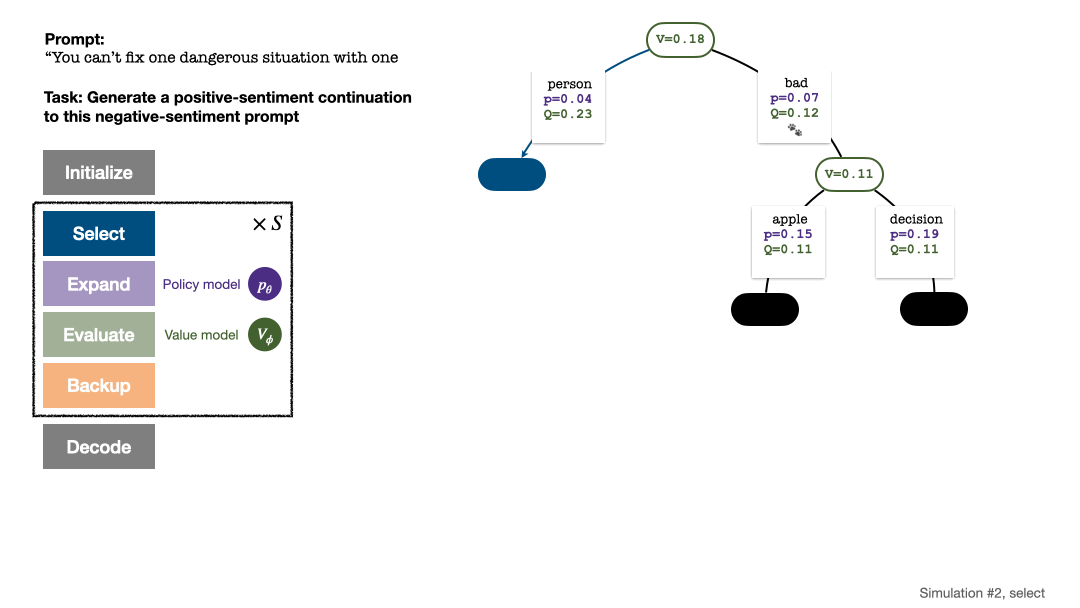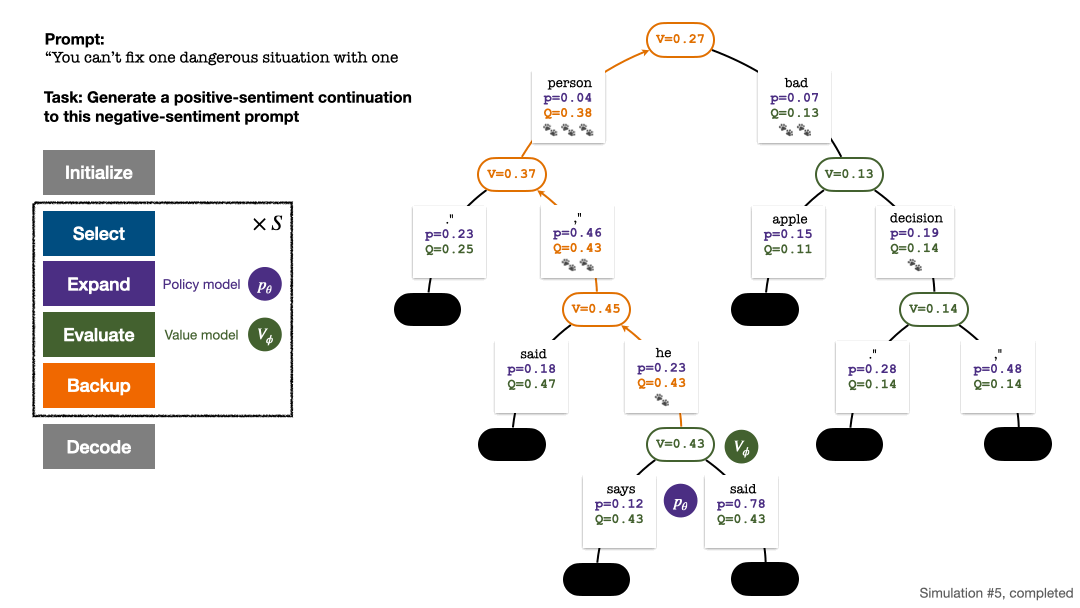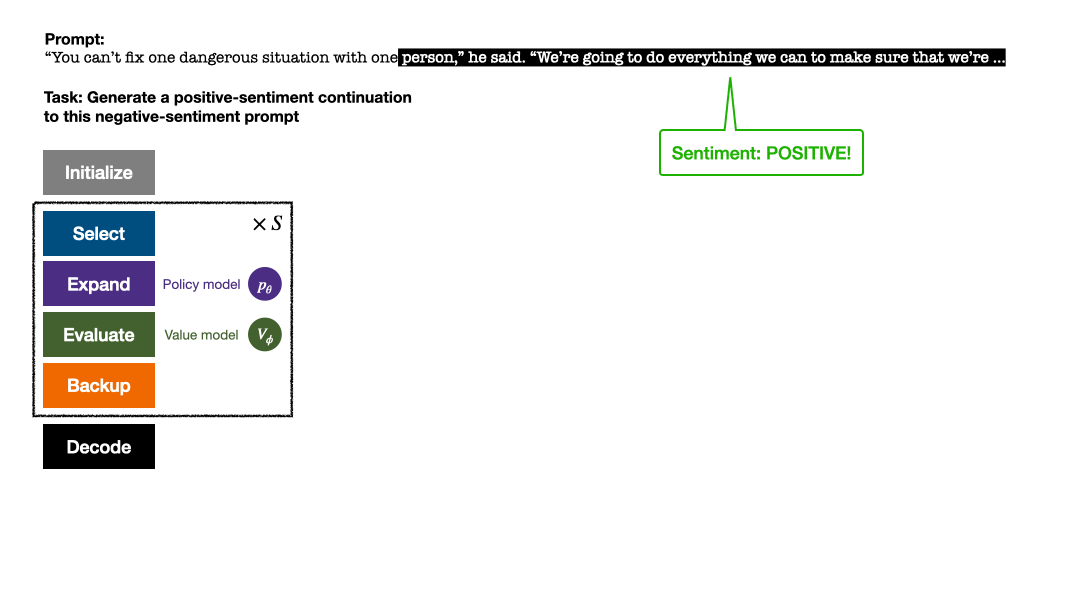 RLHF与AlphaGo核心技术强强联合,UW/Meta让文本生成能力再上新台阶Oct 27, 2023 pm 03:13 PM
RLHF与AlphaGo核心技术强强联合,UW/Meta让文本生成能力再上新台阶Oct 27, 2023 pm 03:13 PM在一项最新的研究中,来自UW和Meta的研究者提出了一种新的解码算法,将AlphaGo采用的蒙特卡洛树搜索算法(Monte-CarloTreeSearch,MCTS)应用到经过近端策略优化(ProximalPolicyOptimization,PPO)训练的RLHF语言模型上,大幅提高了模型生成文本的质量。PPO-MCTS算法通过探索与评估若干条候选序列,搜索到更优的解码策略。通过PPO-MCTS生成的文本能更好满足任务要求。论文链接:https://arxiv.org/pdf/2309.150
 MIT团队运用机器学习闭环自主分子发现平台,成功发现、合成和描述了303种新分子Jan 04, 2024 pm 05:38 PM
MIT团队运用机器学习闭环自主分子发现平台,成功发现、合成和描述了303种新分子Jan 04, 2024 pm 05:38 PM编辑|X传统意义上,发现所需特性的分子过程一直是由手动实验、化学家的直觉以及对机制和第一原理的理解推动的。随着化学家越来越多地使用自动化设备和预测合成算法,自主研究设备越来越接近实现。近日,来自MIT的研究人员开发了由集成机器学习工具驱动的闭环自主分子发现平台,以加速具有所需特性的分子的设计。无需手动实验即可探索化学空间并利用已知的化学结构。在两个案例研究中,该平台尝试了3000多个反应,其中1000多个产生了预测的反应产物,提出、合成并表征了303种未报道的染料样分子。该研究以《Autonom
 AI助力脑机接口研究,纽约大学突破性神经语音解码技术,登Nature子刊Apr 17, 2024 am 08:40 AM
AI助力脑机接口研究,纽约大学突破性神经语音解码技术,登Nature子刊Apr 17, 2024 am 08:40 AM作者|陈旭鹏编辑|ScienceAI由于神经系统的缺陷导致的失语会导致严重的生活障碍,它可能会限制人们的职业和社交生活。近年来,深度学习和脑机接口(BCI)技术的飞速发展为开发能够帮助失语者沟通的神经语音假肢提供了可行性。然而,神经信号的语音解码面临挑战。近日,约旦大学VideoLab和FlinkerLab的研究者开发了一个新型的可微分语音合成器,可以利用一个轻型的卷积神经网络将语音编码为一系列可解释的语音参数(例如音高、响度、共振峰频率等),并通过可微分神经网络将这些参数合成为语音。这个合成器
 Code Llama代码能力飙升,微调版HumanEval得分超越GPT-4,一天发布Aug 26, 2023 pm 09:01 PM
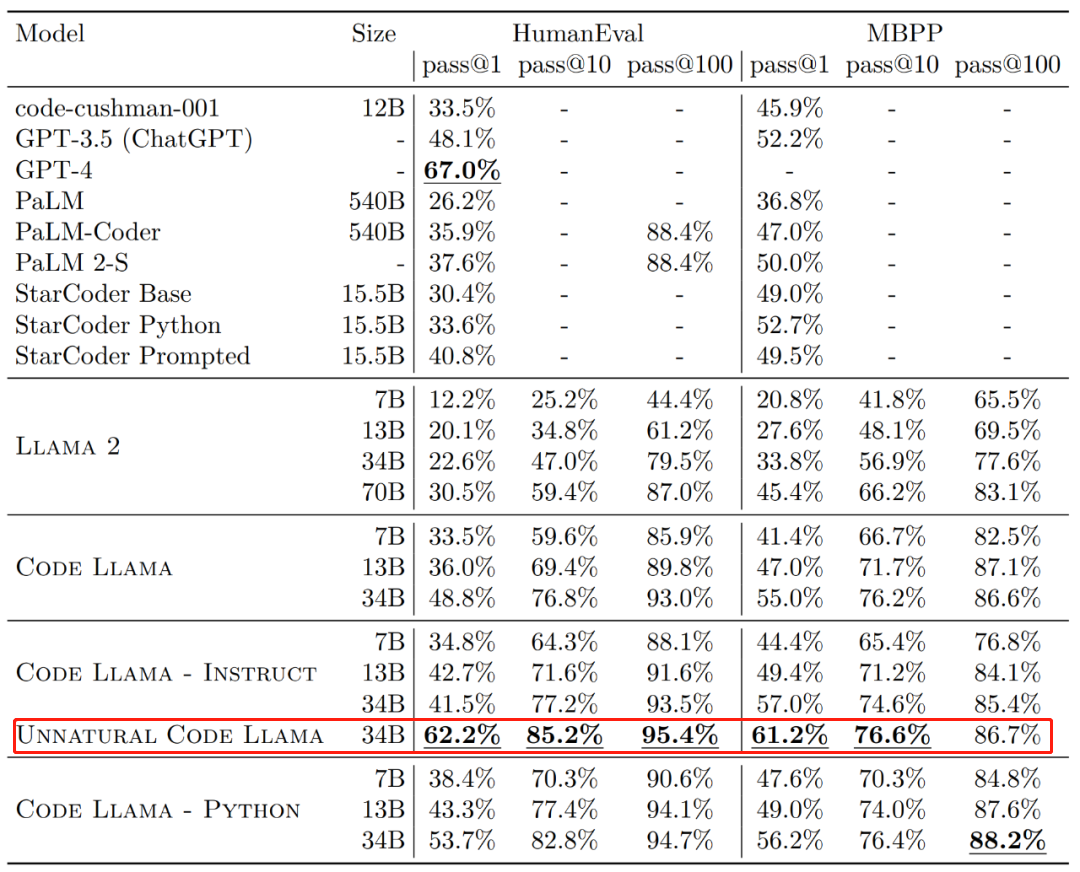
Code Llama代码能力飙升,微调版HumanEval得分超越GPT-4,一天发布Aug 26, 2023 pm 09:01 PM昨天,Meta开源专攻代码生成的基础模型CodeLlama,可免费用于研究以及商用目的。CodeLlama系列模型有三个参数版本,参数量分别为7B、13B和34B。并且支持多种编程语言,包括Python、C++、Java、PHP、Typescript(Javascript)、C#和Bash。Meta提供的CodeLlama版本包括:代码Llama,基础代码模型;代码羊-Python,Python微调版本;代码Llama-Instruct,自然语言指令微调版就其效果来说,CodeLlama的不同版
 准确率 >98%,基于电子密度的 GPT 用于化学研究,登 Nature 子刊Mar 27, 2024 pm 02:16 PM
准确率 >98%,基于电子密度的 GPT 用于化学研究,登 Nature 子刊Mar 27, 2024 pm 02:16 PM编辑|紫罗可合成分子的化学空间是非常广阔的。有效地探索这个领域需要依赖计算筛选技术,比如深度学习,以便快速地发现各种有趣的化合物。将分子结构转换为数字表示形式,并开发相应算法生成新的分子结构是进行化学发现的关键。最近,英国格拉斯哥大学的研究团队提出了一种基于电子密度训练的机器学习模型,用于生成主客体binders。这种模型能够以简化分子线性输入规范(SMILES)格式读取数据,准确率高达98%,从而实现对分子在二维空间的全面描述。通过变分自编码器生成主客体系统的电子密度和静电势的三维表示,然后通
 手机摄影技术让以假乱真的好莱坞级电影特效视频走红Sep 07, 2023 am 09:41 AM
手机摄影技术让以假乱真的好莱坞级电影特效视频走红Sep 07, 2023 am 09:41 AM一个普通人用一台手机就能制作电影特效的时代已经来了。最近,一个名叫Simulon的3D技术公司发布了一系列特效视频,视频中的3D机器人与环境无缝融合,而且光影效果非常自然。呈现这些效果的APP也叫Simulon,它能让使用者通过手机摄像头的实时拍摄,直接渲染出CGI(计算机生成图像)特效,就跟打开美颜相机拍摄一样。在具体操作中,你要先上传一个3D模型(比如图中的机器人)。Simulon会将这个模型放置到你拍摄的现实世界中,并使用准确的照明、阴影和反射效果来渲染它们。整个过程不需要相机解算、HDR
 谷歌用大型模型训练机器狗理解模糊指令,激动不已准备去野餐Jan 16, 2024 am 11:24 AM
谷歌用大型模型训练机器狗理解模糊指令,激动不已准备去野餐Jan 16, 2024 am 11:24 AM人类和四足机器人之间简单有效的交互是创造能干的智能助理机器人的途径,其昭示着这样一个未来:技术以超乎我们想象的方式改善我们的生活。对于这样的人类-机器人交互系统,关键是让四足机器人有能力响应自然语言指令。近来大型语言模型(LLM)发展迅速,已经展现出了执行高层规划的潜力。然而,对LLM来说,理解低层指令依然很难,比如关节角度目标或电机扭矩,尤其是对于本身就不稳定、必需高频控制信号的足式机器人。因此,大多数现有工作都会假设已为LLM提供了决定机器人行为的高层API,而这就从根本上限制了系统的表现能


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

Dreamweaver Mac版
视觉化网页开发工具

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

