
大模型应用探索——企业知识管家

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB转载
- 2024-01-08 08:49:431481浏览

一、传统知识管理的背景与挑战
1、企业知识管理的必要性
在现代企业中,知识管理是一个至关重要的环节。它可以帮助企业有效地组织和利用内部和外部的知识资源,从而提升企业的效率和竞争力。为了更好地进行知识管理,许多企业引入了知识管家的概念。知识管家是一种专门负责管理和传播企业知识的角色或系统。通过知识管家,企业可以更好地收集、整
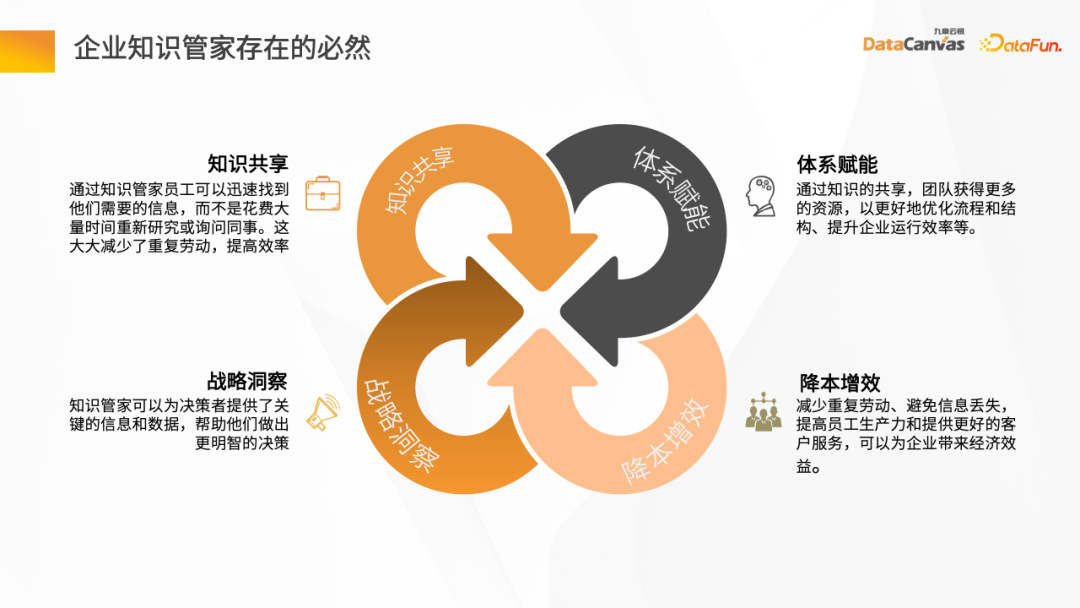
随着互联网应用的迅猛发展和知识爆炸式增长,企业面临着一个共享知识的挑战。如何实现企业内部知识的有效传递和共享已经成为一个重要问题。通过知识共享,企业不仅能够提高工作效率,还能够避免重复劳动。
另外一种方式是通过采用知识共享的模式,建立一个能够赋能企业的机制,从而更好地优化流程和结果,提高企业的运行效率。这种模式可以让企业内部的员工分享他们的知识和经验,使得团队中的每个人都能够从中受益。通过共享知识,企业可以避免重复劳动,减少错误和失误,并且能够更好地应对挑战和变化。这
此外,作为知识管家,它还能够为决策者提供关键的信息和数据,以帮助他们做出更加明智的决策。知识管家具备强大的信息检索和分析能力,能够从海量的数据中提取出有用的信息,并进行整合和分析。这些信息和数据可以包括市场趋势、竞争对手分析、消费者洞察、技术发展等方面的
另外,一个非常关键的因素是减少企业员工的工作负担,防止信息的丢失,并且提高员工的工作效率和客户服务水平,从而实现降低成本、提高效率的目标。
2、企业知识管理挑战
在没有大模型之前,构建知识管家的逻辑是相当复杂的。通常情况下,我们会使用知识库的概念,借助企业知识图谱或者企业内部的数据来构建知识库。然而,在这个构建的过程中会面临许多挑战。 首先,知识库的构建需要大量的人力和时间投入。收集、整理和归纳企业内部的知识和信息是一项繁琐而耗时的工作。需要专业的团队来处理和管理这些数据,并确保其
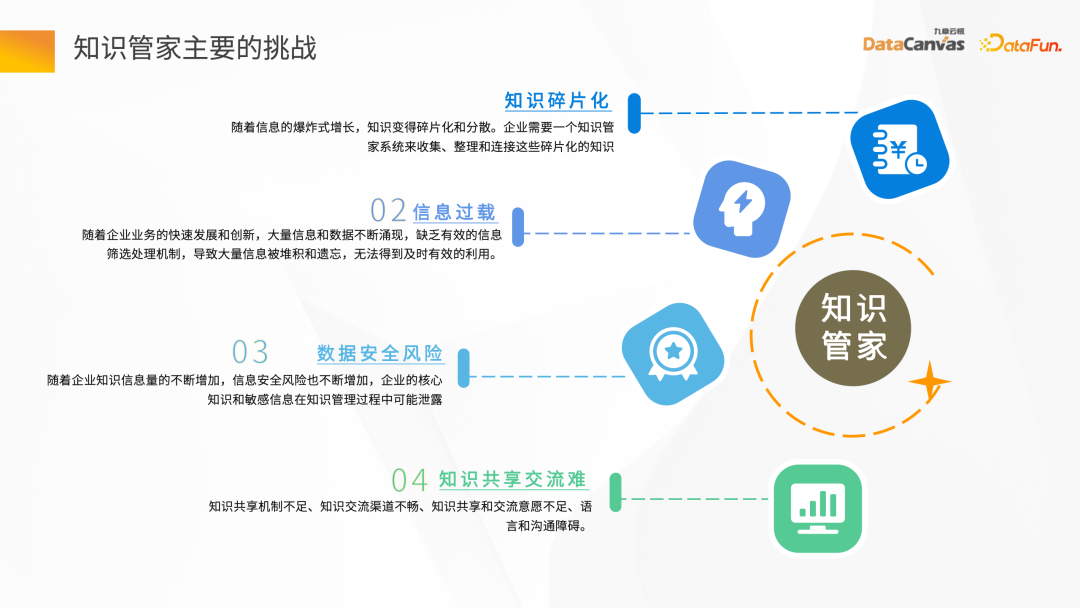
- 知识碎片化
知识碎片化主要体现在两个方面,一个方面是企业的数据非常分散,如 OA 系统的数据有不同部门的、不同团队的。另一方面,这些数据基本上都是以非结构化形式去提供的,比如 Word、PDF、图片、视频等。在知识管家建设的过程中,如何把这些知识碎片化的信息快速集中,是面临的第一个挑战。
- 信息过载
在企业业务快速发展中,面临大量信息和数据不断涌现的情况下,如何在海量数据中建立筛选机制,保证信息的准确、及时,也是一大挑战。
- 数据安全风险
企业一般不会把自己的私有数据共享给其他的机构或组织,一般都会比较重视企业私域数据的数据安全,因此也需要处理数据安全风险。
- 知识共享交流难
不同的公司有不同的组织结构,有些偏技术,有些偏业务,也有技术和业务混合型的,在业务和技术沟通的过程中,沟通不顺畅是每个企业在知识共享中都会面临的一个问题。
二、知识管家解决方案
1、企业知识管家是什么
企业知识管家,类似一个人的大脑,去辅助整个知识的存储,并理解和创造知识。
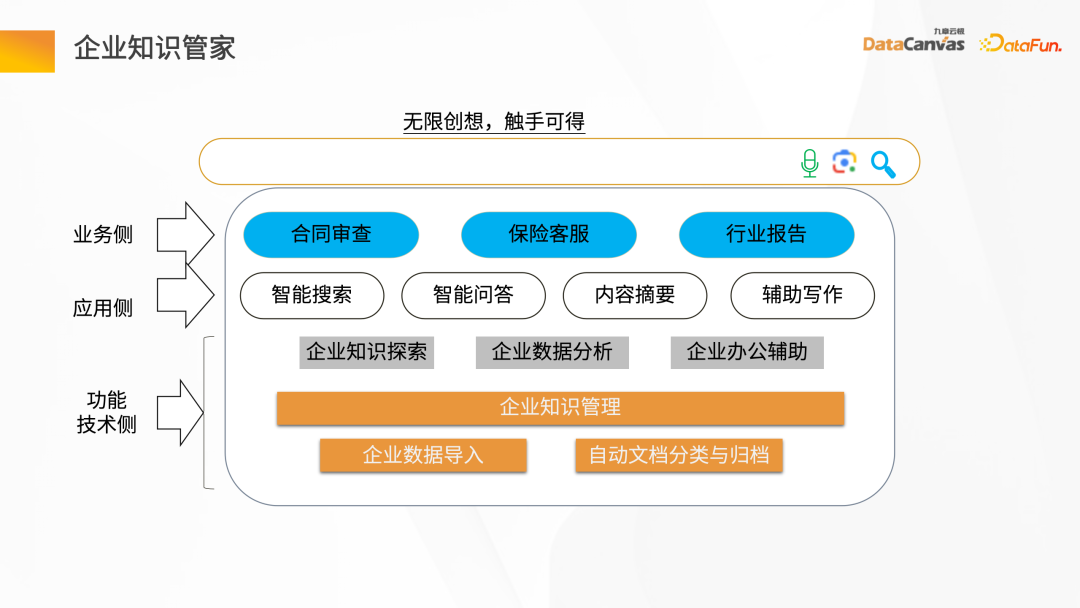
企业知识管家总体分为三个层次:第一层是功能技术侧的需求,主要负责企业知识的管理,包括企业数据的导入、文档的自动分类与归档,以及其它一些基础功能的需求;中间层是应用侧的需求,包括提供一些智能问答、智能搜索、摘要生成、辅助写作等功能;上层是业务侧的需求,包括合同的审查、保险的客服、行业报告的生成。
知识管家对外呈现的接口总体有三种模式:第一种接口类似文本框的方式,提供知识探索和分析;另一种是借助于 API 的 Token,把不同应用场景里涉及的智能 Agent 发布成 API Token 的方式去和企业的业务系统整合;第三种方式是智能 Agent,通过对话模式去做知识的探索和分析。
2、企业知识管家解决方案
企业知识管家主要负责企业专属的知识管理和创造,包括以下一些业务场景:

- 智能问答
结合企业自己的私域数据,经过向量化后,存储在向量数据库中,借助问答对模式去做智能问答的场景,通过这些场景可以衍生出来很多更具化的业务需求。
- 自助文档分析
通过文档去做一些探索和分析,比如对论文进行探索,可以提问这篇论文讲的内容,还可以进行文档的自主分析,提供整个文档的分段预览、上下文检索、摘要总结等能力。
- 自定义角色场景
结合企业内部不同角色的私域数据,再加上提示词的模式,提供一些自定义场景的设计,如文档的辅助写作、智能会议纪要等。
- 合同审核
采用人机对话的模式,对企业的各种合同做一些关键条款信息的审查,查看对应信息是否准确。
企业知识管家产品的主要功能包括:
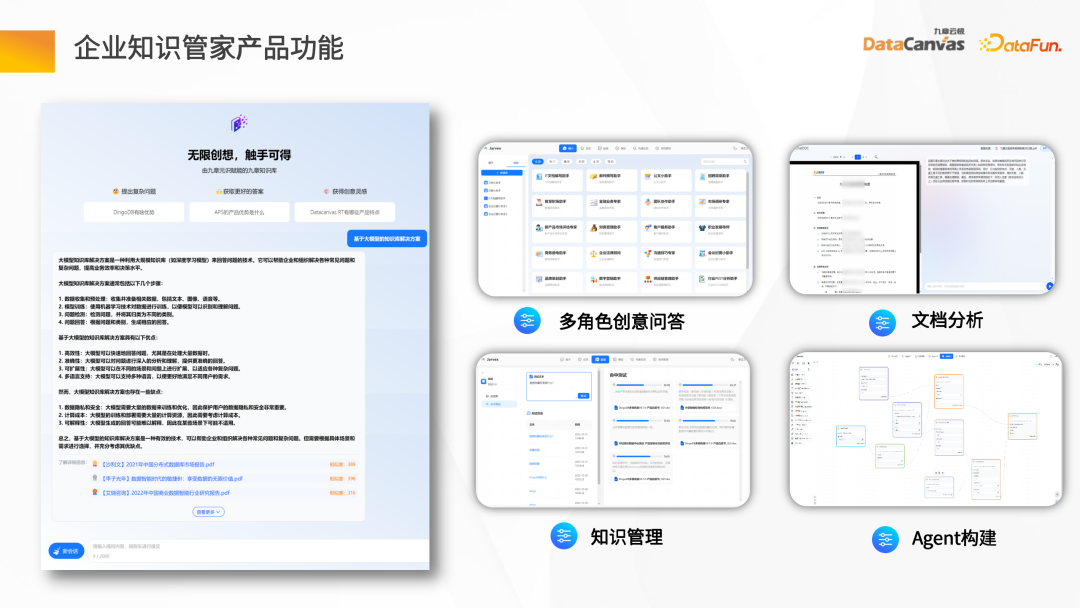
- 智能问答:结合具体问题,通过检索上下文得到一个有源可依的答案。
- 多角色创意问答:通过提示词与企业的私域数据来构建智能应用场景。
- 文档分析:导入整个文档,进行总结或探索分析。
- 知识管理:企业数据通过知识管家,进行全自动的管理,整个过程采用非常简洁的模式。
- Agent 构建:开发平台,即大模型 IDE 功能。
知识管家的功能架构:
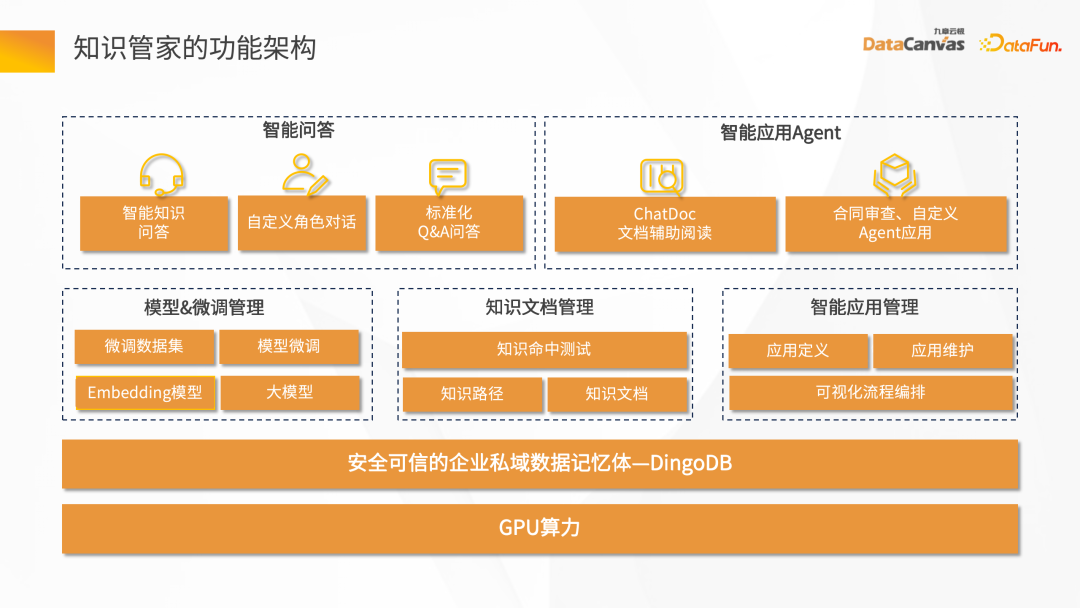
最下面是 GPU 算力,包含两类,一类是推理的算力,另一类是微调的算力。中间这一层是安全可信的企业私域数据记忆体——DingoDB多模向量数据库。
再上一层整个技术层的功能点,包括模型微调的管理、知识文档管理、智能应用管理。
最上面是偏业务场景类的需求,智能问答里可以自定义角色的一些对话、标准的 QA 问答,还有智能应用的 Agent,基于文档的辅助阅读、合同的审查、保险的个人助手。
三、知识管家核心技术探索
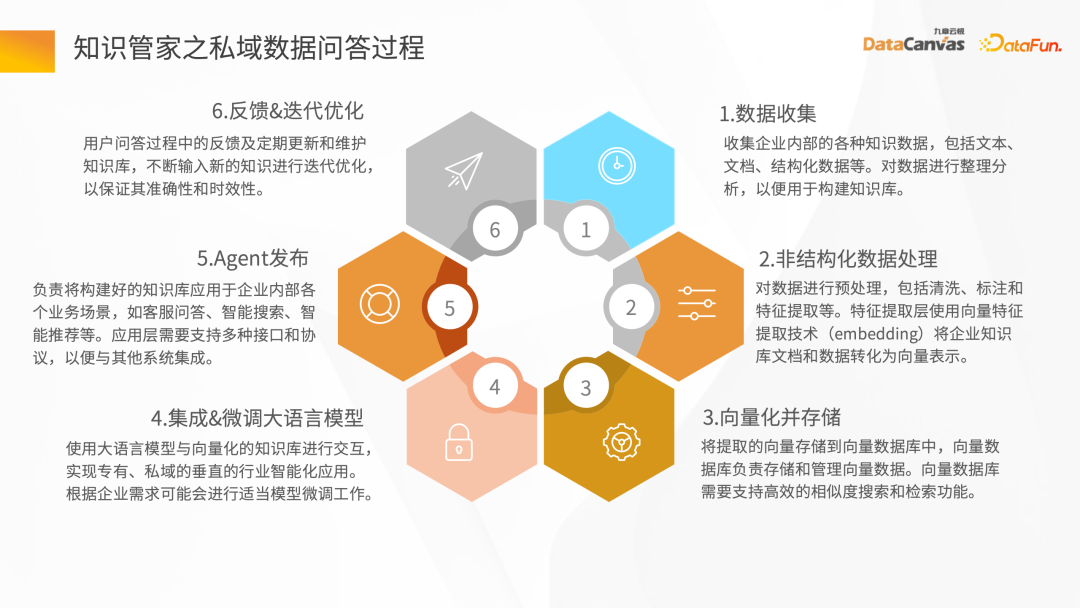
1、知识管家构建过程
接下来通过智能问答场景来介绍整个知识管家的构建流程。
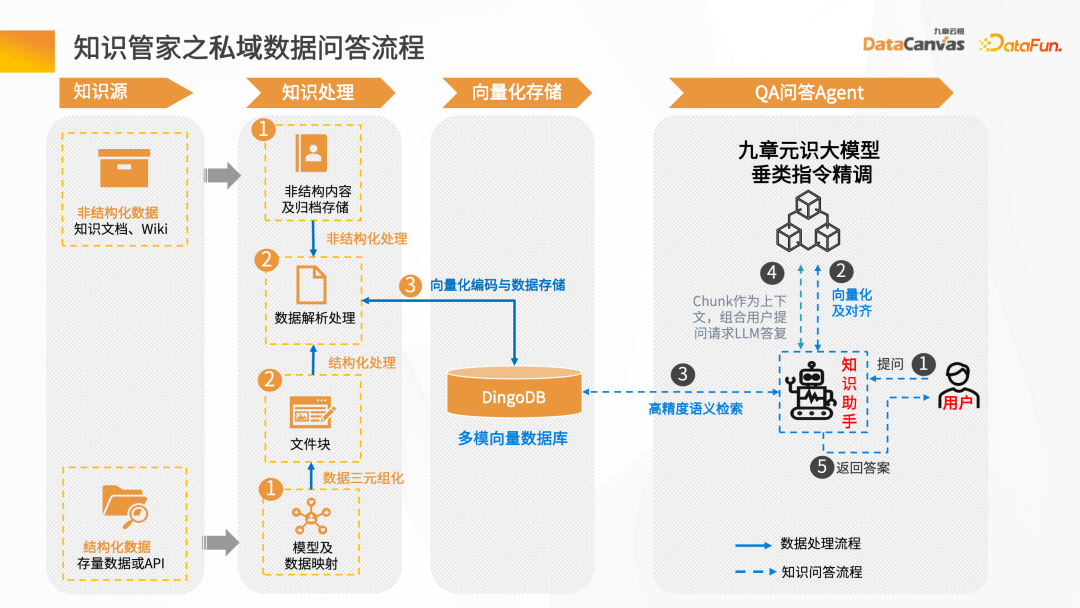
首先需要有数据源,可能会有结构和非结构化数据,通常来说,知识库的构建以非结构化数据为主,如 Word、PDF、Excel,还有企业系统、Jira、知识管理平台等。
这些数据经过知识处理环节,转换成向量存到数据库中。需要先把文档加载进去,然后给予文档的 Layout 信息或结构信息,做文档向量解析生成文件块,然后基于文件块调用对应的 Embedding 模型转换成向量,对向量进行存储。
智能问答交互的过程:在用户提出问题后,首先借助智能助手把问题向量化,再去数据库做语义的检索,得到关联这个语义相近的文章上下文,通过上下文结合提示词,经过大模型的推理,最终得到答案的返回。
整体过程是一个不断迭代和反馈优化的过程,只有这样才能得到基于企业私域数据上的专属智能专家角色。
2、知识管家构建核心技术探索
- 非结构化数据处理
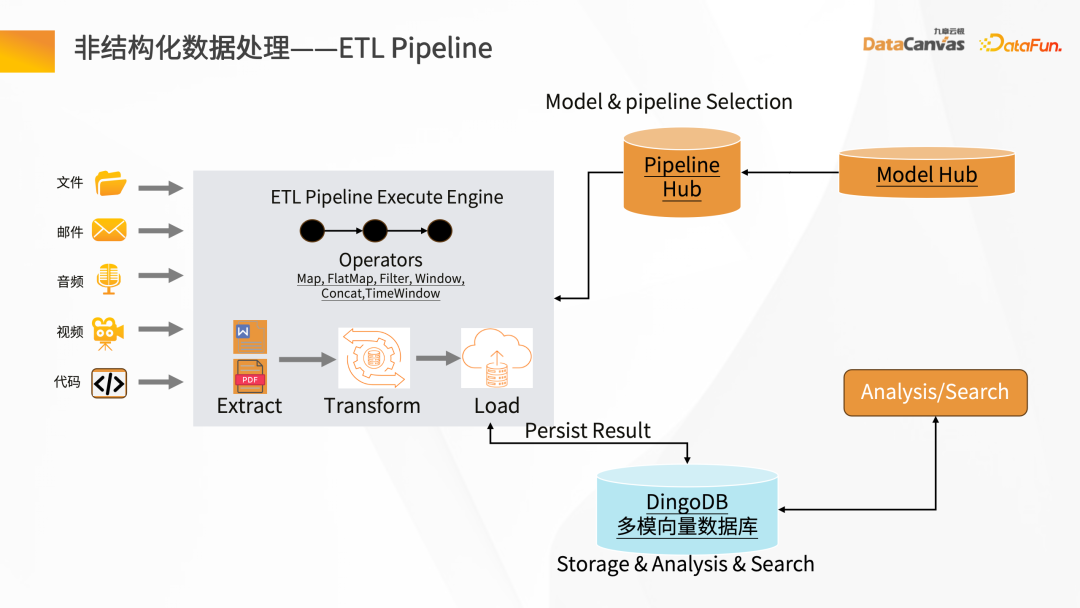
非结构化数据 ETL 处理过程,需要借助一些工具。知识管家从技术模式上提供了一些特殊的算子,这些算子可以清洗整个 Map、Filter、基于 Window的变化,通过整个 ETL 的 Pipeline 可以数据进行转换。
通过各种文件的解析器(如 PDF 的解析器)进行解析,然后经过中间层对应的不同应用场景 Hub 的 Operator,可以快速构建 Pipeline 的 Hub,再经过数据的清洗和转换后进行 Embedding 化,最后存到向量数据库中。
- 精度与完整性数据保证-无损数据解析
要得到一个好的模型调试效果,要保证精确和完整的数据,具备良好的数据处理的质量。
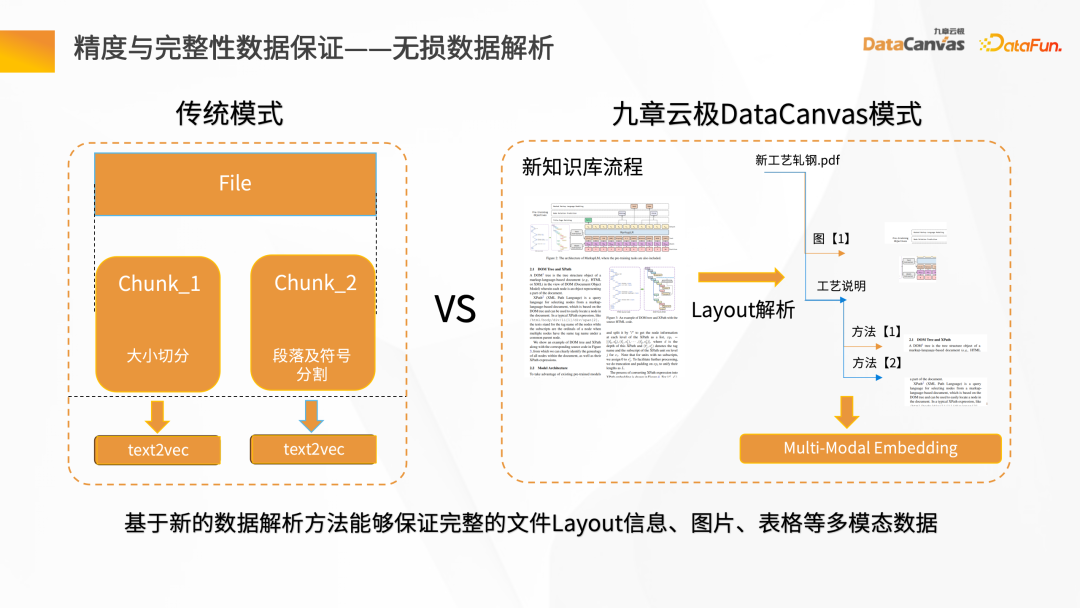
构建一个传统的数据检索非常简单,但实际的知识比较复杂,除了文字本身的信息外,还有图片、表格数据、段落信息等。对此,九章云极DataCanvas提供了 Layout 的解析模式,可以实现 Layout 信息、表格、图片等多模态数据的全量存储,全面提升了数据解析过程的质量。
- 强相关性检索-Reranking 二次筛选
在文档经过向量化,存到 DingoDB多模向量数据库后,通过 Query 进行检索,在检索结果中会包含检索内容本身的结果,也会包含相关性的结果,这时候需要在检索召回的 Chunk 做 Reranking 的二次筛选。
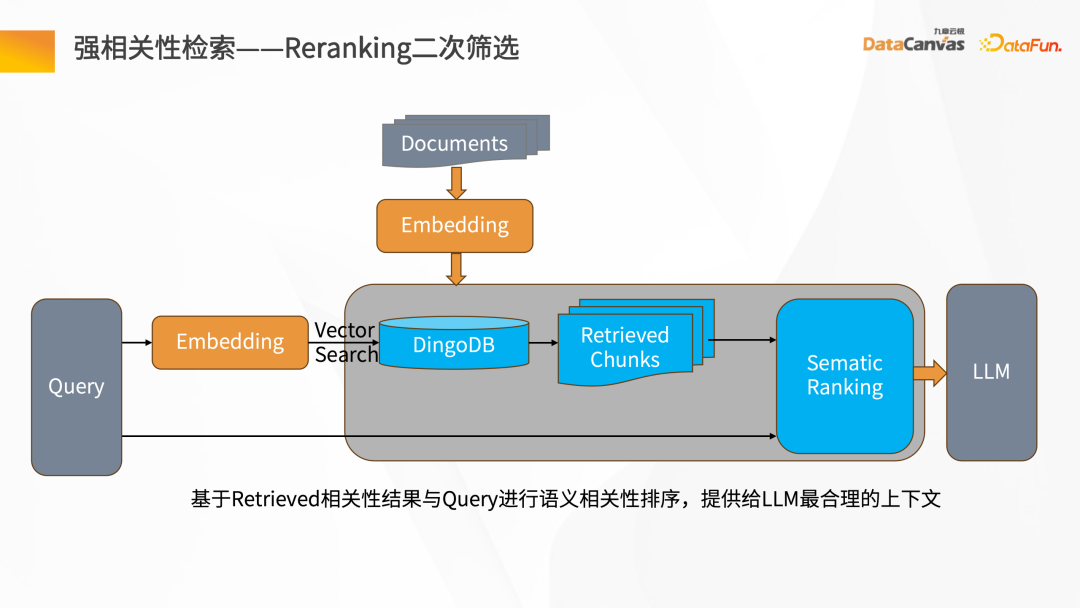
在 Reranking 二次筛选时,要将 Retrieval 的 Chunk 和对应的 Query 做相关性语义分析,包括找到语义最为接近的匹配,然后把二次筛选后的检索 Chunk 重新推给大语言模型。
- 安全可信的答案生成-多指令微调
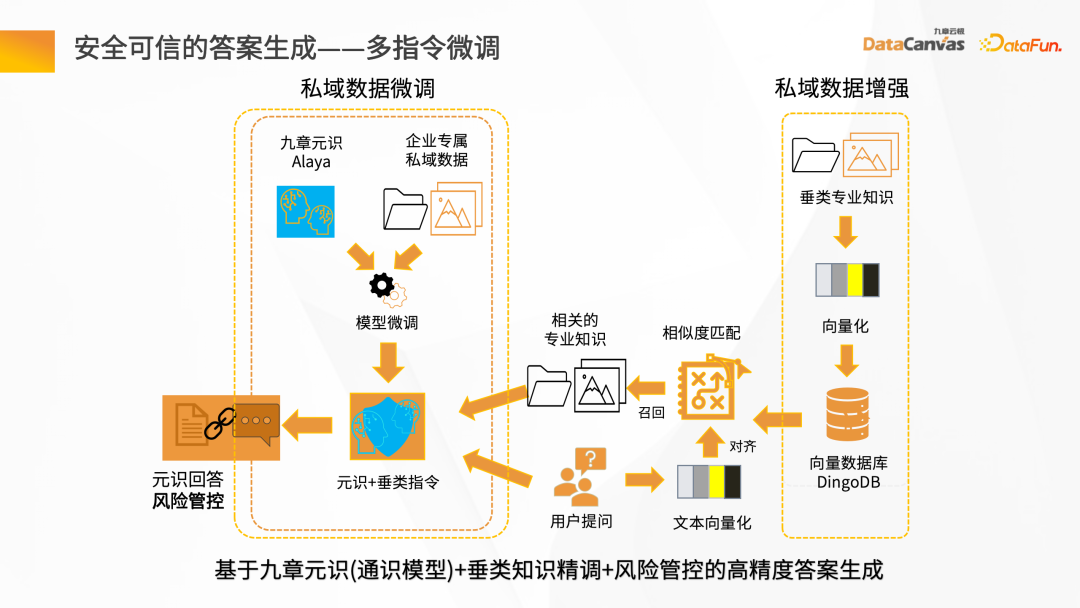
为了保证答案生成过程的安全可信,九章云极DataCanvas基于通用的大语音模型,对召回的数据做提示词的限定,并结合企业的私域数据对大模型进行垂类知识的微调,再加上风向管控机制,从而保证答案生成的高精度。
- 存储与检索能力- DingoDB多模向量数据库
DingoDB可以提供多样化的 API 支持通过 SQL 和 Python 工具包去做数据查询,也提供一体化的方式,实现结构化和非结构化的联合查询。针对实时性的场景,DingoDB提供了实时写入即可查询的能力,可以边导入数据边进行实时检索。
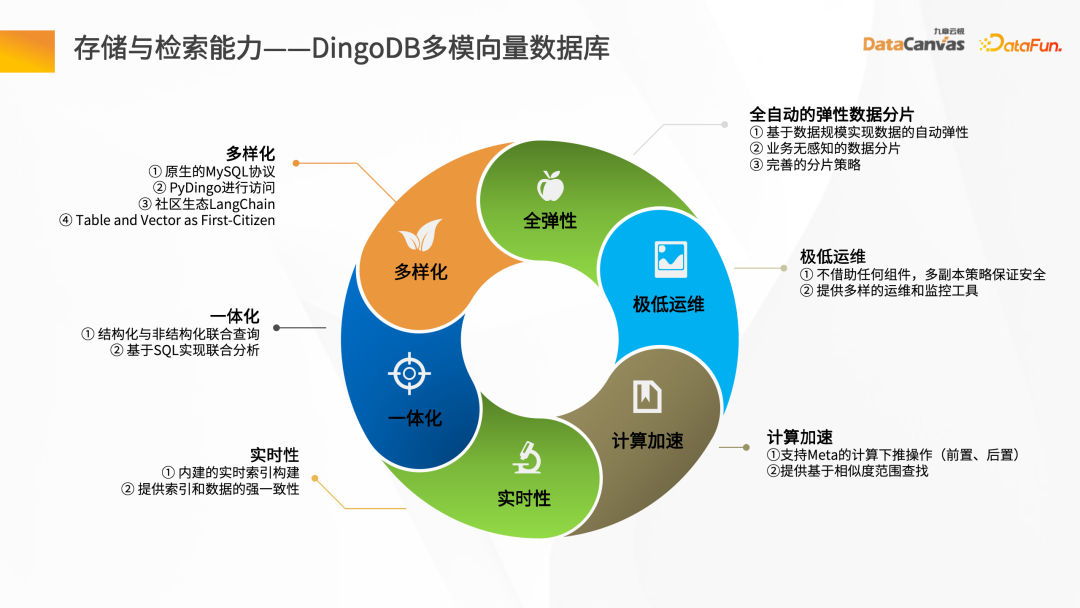
DingoDB还提供了计算加速的能力,支持 Meta 的前置、后置的过滤筛选,以及基于相似度的范围查找。DingoDB还提供了多副本的工具,可以做部分的迁移和数据的迁移,同时提供多样化的运维和监控工具,降低了运维成本。DingoDB还能提供自动弹性分片的能力,可以把数据动态地平衡到不同机器上,实现各个节点的负载均衡。
- 安全可信的专属 LLM-微调 Pipeline
在企业私域数据上,针对通用的场景需要进行微调,以构建某个场景里企业专属的大语言模型。知识管家里总结了整个微调过程中的痛点,在产品里提供工具化的方式,上传文档就可以得到所有问题的数据。有了数据后,直接在界面上通过配置参数就可以进行微调,同时产品也提供了一些微调数据指标,可以对微调的结果进行评价。

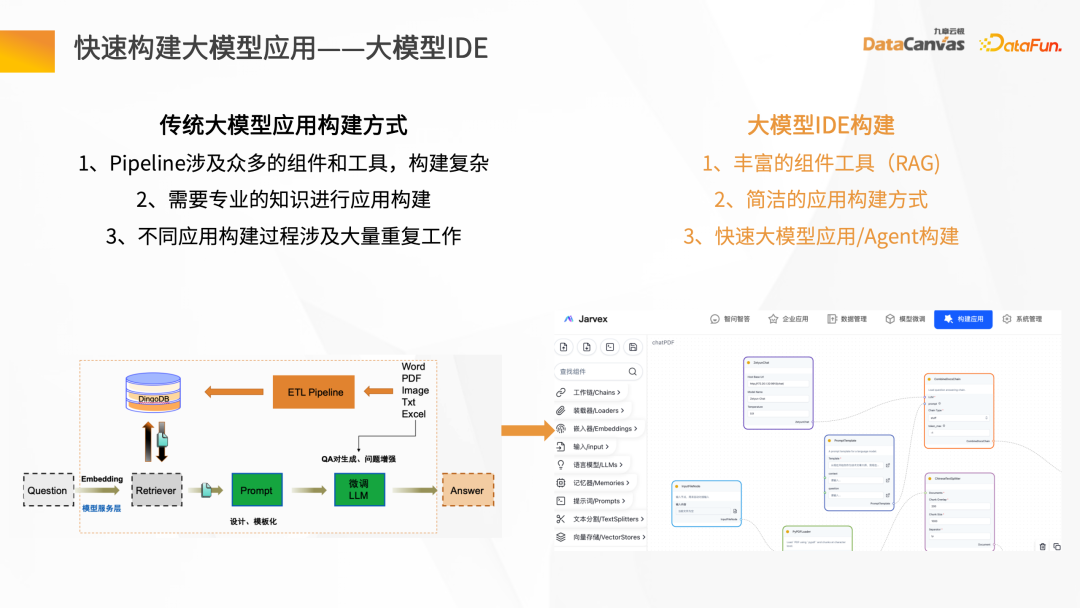
- 快速构建大模型应用-大模型 IDE
传统大模型应用往往构建复杂,知识管家基于九章云极DataCanvas自己的 FS 能力,构建了自己的大模型 IDE,能够提供丰富的组件和工具,通过简洁的应用构建方式,把构建的模版发布成智能应用的 Agent。
四、总结与展望
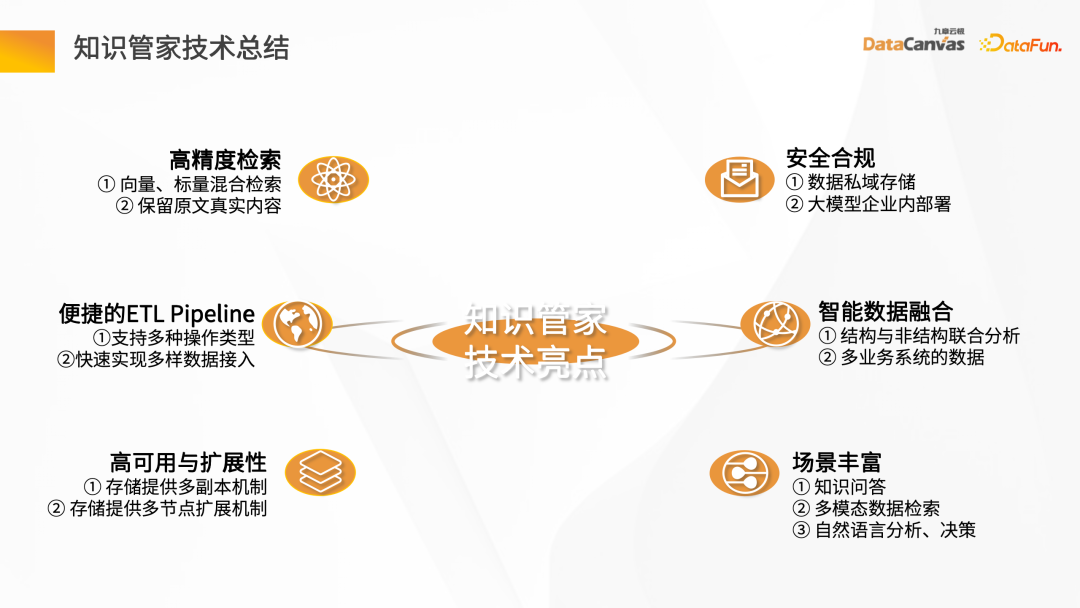
1、知识管家方案总结
知识管家的技术亮点主要有以下六大方面:高精度检索、便捷的 ETL Pipeline、高可用与扩展性、安全合规、智能数据融合以及丰富的场景。
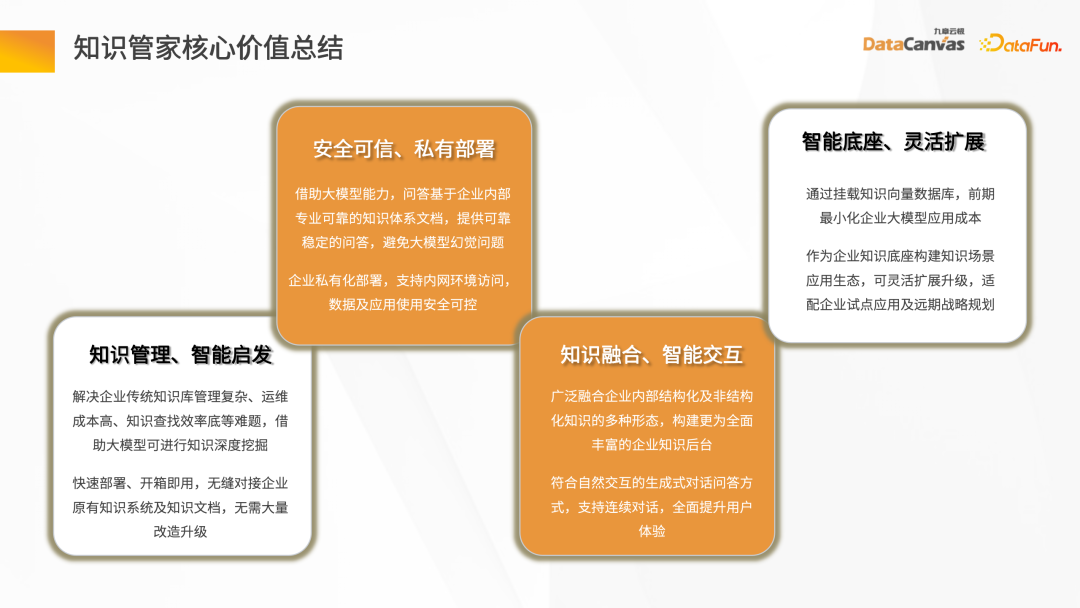
知识管家的核心价值包括:提供了知识管理和智能启发的基础能力,并且提供了一种安全可信的应用私有化部署方式,包含企业的所有数据,可实现知识的融合和智能交互。作为智能底座,提供灵活扩展的能力,可以在知识管家上基于大模型做新的 Agent 开发。
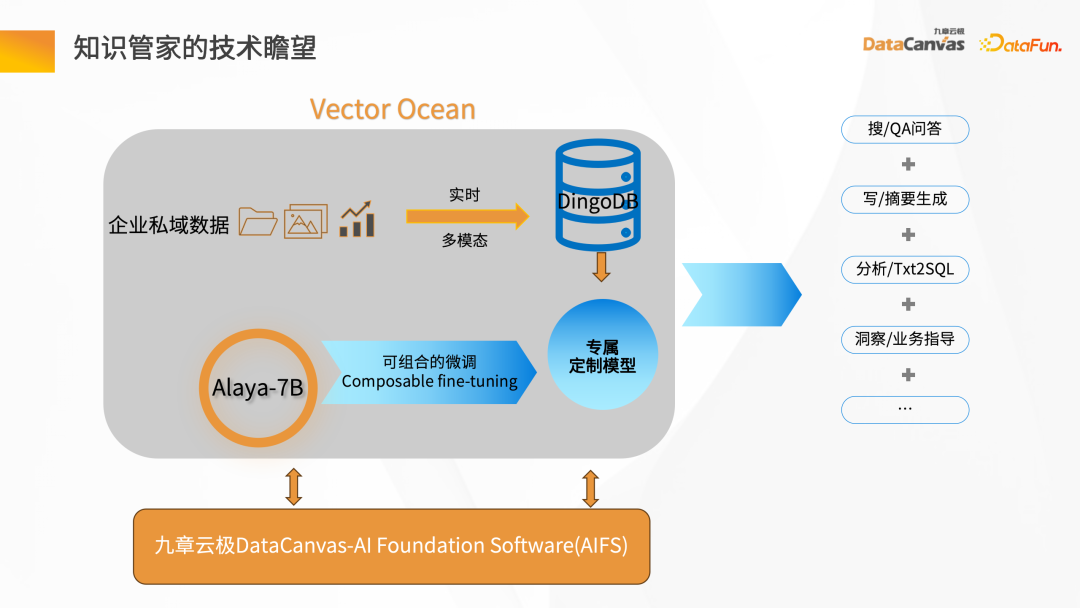
2、未来展望
知识管家是基于九章云极 DataCanvas的AIFS,提供从裸金属到上面的 GPU 算力以及模型的调度,并实现模型微调的一整套 Pipeline 模式。它借助通识的大语言模型,加上企业的私域数据,进行组合微调,形成企业自己专属的大语言模型。基于大语言模型的扩展能力,结合 DingoDB多模向量数据库,可以实现企业里面的搜索问答、摘要生成等应用,进行企业的知识管理。
以上是大模型应用探索——企业知识管家的详细内容。更多信息请关注PHP中文网其他相关文章!