
对大规模机器学习中幻觉缓解技术的综合研究

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB转载
- 2024-01-05 16:54:111416浏览
大型语言模型(LLMs)是具有大量参数和数据的深度神经网络,能够在自然语言处理(NLP)领域实现多种任务,如文本理解和生成。近年来,随着计算能力和数据规模的提升,LLMs取得了令人瞩目的进展,如GPT-4、BART、T5等,展现了强大的泛化能力和创造力。
LLMs也存在严重的问题,在生成文本时容易产生与真实事实或用户输入不一致的内容,即幻觉(hallucination)。这种现象不仅会降低系统的性能,也会影响用户的期望和信任,甚至会造成一些安全和道德上的风险。因此,如何检测和缓解LLMs中的幻觉,已经成为了当前NLP领域的一个重要和紧迫的课题。
1月1日,来自于孟加拉国伊斯兰科技大学、美国南卡罗来纳大学人工智能研究所、美国斯坦福大学、美国亚马逊人工智能部门的几位科学家SM Towhidul Islam Tonmoy、SM Mehedi Zaman、Vinija Jain、Anku Rani、Vipula Rawte、Aman Chadha、Amitava Das发表了题为《A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models》的论文,旨在介绍和分类大型语言模型(LLMs)中的幻觉缓解技术。

他们首先介绍了幻觉的定义、原因和影响,以及评估方法。然后他们提出了一个详细的分类体系,将幻觉缓解技术分为四大类:基于数据集的,基于任务的,基于反馈的,和基于检索的。每一类中,他们又进一步细分了不同的子类,并举例说明了一些代表性的方法。
作者们还分析了这些技术的优缺点,挑战和局限性,以及未来的研究方向。他们指出,目前的技术仍然存在一些问题,如缺乏通用性,可解释性,可扩展性,和鲁棒性。他们建议,未来的研究应该关注以下几个方面:开发更有效的幻觉检测和量化方法,利用多模态信息和常识知识,设计更灵活和可定制的幻觉缓解框架,以及考虑人类的参与和反馈。
1.LLMs幻觉的分类体系
为了更好地理解和描述LLMs中的幻觉问题,他们提出了一个基于幻觉的来源、类型、程度和影响的分类体系,如图1所示。他们认为,这个体系能够覆盖LLMs中幻觉的各个方面,有助于分析幻觉的原因和特征,以及评估幻觉的严重性和危害性。
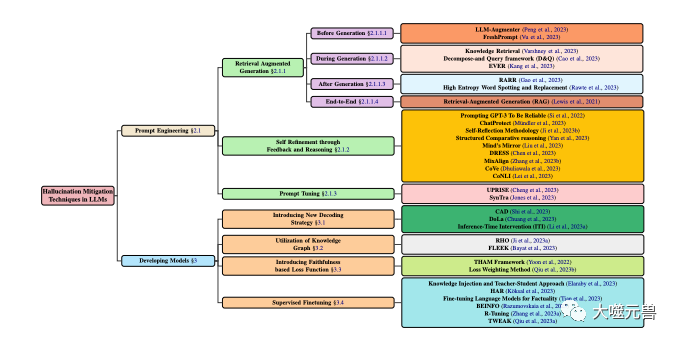 图1
图1
LLM中幻觉缓解技术的分类,侧重于涉及模型开发和提示技术的流行方法。模型开发分为各种方法,包括新的解码策略、基于知识图的优化、添加新的损失函数组件和监督微调。同时,提示工程可以包括基于检索增强的方法、基于反馈的策略或提示调整。
幻觉的来源
幻觉的来源是导致LLMs产生幻觉的根本原因,可以归结为以下三类:
参数知识(Parametric Knowledge):LLMs在预训练阶段从大规模的无标注文本中学习到的隐式知识,如语法、语义、常识等。这种知识通常存储在LLMs的参数中,可以通过激活函数和注意力机制来调用。参数知识是LLMs的基础,但也可能是幻觉的来源,因为它可能包含一些不准确、过时或有偏见的信息,或者与用户输入的信息存在冲突。
非参数知识(Non-parametric Knowledge):LLMs在微调或生成阶段从外部的有标注数据中获取的显式知识,如事实、证据、引用等。这种知识通常以结构化或非结构化的形式存在,可以通过检索或内存机制来访问。非参数知识是LLMs的补充,但也可能是幻觉的来源,因为它可能存在一些噪声、错误或不完整的数据,或者与LLMs的参数知识不一致。
生成策略(Generation Strategy):指LLMs在生成文本时采用的一些技术或方法,如解码算法、控制码、提示等。这些策略是LLMs的工具,但也可能是幻觉的来源,因为它们可能导致LLMs过度依赖或忽视某些知识,或者在生成过程中引入一些偏差或噪声。
幻觉的类型
幻觉的类型是指LLMs生成幻觉的具体表现形式,可以分为以下四类:
语法幻觉(Grammatical Hallucination):指LLMs生成的文本在语法上存在错误或不规范,如拼写错误、标点错误、词序错误、时态错误、主谓不一致等。这种幻觉通常是由于LLMs对语言规则的不完全掌握或对噪声数据的过度拟合造成的。
语义幻觉(Semantic Hallucination):指LLMs生成的文本在语义上存在错误或不合理,如词义错误、指代错误、逻辑错误、歧义、矛盾等。这种幻觉通常是由于LLMs对语言意义的不充分理解或对复杂数据的不足处理造成的。
知识幻觉(Knowledge Hallucination):指LLMs生成的文本在知识上存在错误或不一致,如事实错误、证据错误、引用错误、与输入或上下文不匹配等。这种幻觉通常是由于LLMs对知识的不正确获取或不恰当使用造成的。
创造幻觉(Creative Hallucination):指LLMs生成的文本在创造上存在错误或不适当,如风格错误、情感错误、观点错误、与任务或目标不符合等。这种幻觉通常是由于LLMs对创造的不合理控制或不充分评估造成的。
幻觉的程度
幻觉的程度是指LLMs生成幻觉的数量和质量,可以分为以下三类:
轻微幻觉(Mild Hallucination):幻觉较少且较轻,不影响文本的整体可读性和可理解性,也不损害文本的主要信息和目的。例如,LLMs生成了一些语法上的小错误,或者一些语义上的不明确,或者一些知识上的细节错误,或者一些创造上的微妙差异。
中等幻觉(Moderate Hallucination):幻觉较多且较重,影响文本的部分可读性和可理解性,也损害文本的次要信息和目的。通常是LLMs生成了一些语法上的大错误,或者一些语义上的不合理。
严重幻觉(Severe Hallucination):幻觉非常多且非常重,影响文本的整体可读性和可理解性,也破坏文本的主要信息和目的。
幻觉的影响
幻觉的影响是指LLMs生成幻觉对用户和系统的潜在后果,可以分为以下三类:
无害幻觉(Harmless Hallucination):对用户和系统没有造成任何负面的影响,甚至可能有一些正面的影响,如增加趣味性、创造性、多样性等。例如,LLMs生成了一些与任务或目标无关的内容,或者一些与用户的偏好或期望相符的内容,或者一些与用户的情绪或态度相契合的内容,或者一些与用户的交流或互动有助的内容。
有害幻觉(Harmful Hallucination):对用户和系统造成了一些负面的影响,如降低效率、准确性、可信度、满意度等。例如,LLMs生成了一些与任务或目标不符合的内容,或者一些与用户的偏好或期望不一致的内容,或者一些与用户的情绪或态度不协调的内容,或者一些与用户的交流或互动有碍的内容。
危害幻觉(Hazardous Hallucination):对用户和系统造成了严重的负面的影响,如引发误解、冲突、争议、伤害等。例如,LLMs生成了一些与事实或证据相违背的内容,或者一些与道德或法律相冲突的内容,或者一些与人权或尊严相抵触的内容,或者一些与安全或健康相威胁的内容。
2.LLMs幻觉的原因分析
为了更好地解决LLMs中的幻觉问题,我们需要深入分析导致幻觉的原因。根据前文提出的幻觉的来源,作者将幻觉的原因分为以下三类:
参数知识的不足或过剩:LLMs在预训练阶段,通常使用大量的无标注文本来学习语言的规则和知识,从而形成参数知识。然而这种知识可能存在一些问题,如不完整、不准确、不更新、不一致、不相关等,导致LLMs在生成文本时,无法充分理解和利用输入的信息,或者无法正确区分和选择输出的信息,从而产生幻觉。另一方面参数知识也可能过于丰富或强大,使得LLMs在生成文本时,过度依赖或偏好自身的知识,而忽视或冲突输入的信息,从而产生幻觉。
非参数知识的缺失或错误:LLMs在微调或生成阶段,通常使用一些外部的有标注数据来获取或补充语言的知识,从而形成非参数知识。这种知识可能存在一些问题,如稀缺、噪声、错误、不完整、不一致、不相关等,导致LLMs在生成文本时,无法有效地检索和融合输入的信息,或者无法准确地验证和纠正输出的信息,从而产生幻觉。非参数知识也可能过于复杂或多样,使得LLMs在生成文本时,难以平衡和协调不同的信息来源,或者难以适应和满足不同的任务需求,从而产生幻觉。
生成策略的不恰当或不充分:LLMs在生成文本时,通常使用一些技术或方法来控制或优化生成的过程和结果,从而形成生成策略。这些策略可能存在一些问题,如不恰当、不充分、不稳定、不可解释、不可信等,导致LLMs在生成文本时,无法有效地调节和指导生成的方向和质量,或者无法及时地发现和修正生成的错误,从而产生幻觉。生成策略也可能过于复杂或多变,使得LLMs在生成文本时,难以保持和保证生成的一致性和可靠性,或者难以评估和反馈生成的效果,从而产生幻觉。
3.LLMs幻觉的检测方法和评测标准
为了更好地解决LLMs中的幻觉问题,我们需要有效地检测和评估LLMs生成的幻觉。根据前文提出的幻觉的类型,作者将幻觉的检测方法分为以下四类:
语法幻觉的检测方法:利用一些语法检查工具或规则,来识别和纠正LLMs生成的文本中的语法错误或不规范。例如,可以使用一些拼写检查、标点检查、词序检查、时态检查、主谓一致检查等工具或规则,来检测和修正LLMs生成的文本中的语法幻觉。
语义幻觉的检测方法:利用一些语义分析工具或模型,来理解和评估LLMs生成的文本中的语义错误或不合理。例如,可以使用一些词义分析、指代消解、逻辑推理、歧义消除、矛盾检测等工具或模型,来检测和修正LLMs生成的文本中的语义幻觉。
知识幻觉的检测方法:利用一些知识检索或验证工具或模型,来获取和比较LLMs生成的文本中的知识错误或不一致。例如,可以使用一些知识图谱、搜索引擎、事实检查、证据检查、引用检查等工具或模型,来检测和修正LLMs生成的文本中的知识幻觉。
创造幻觉的检测方法:利用一些创造评估或反馈工具或模型,来检测和评价LLMs生成的文本中的创造错误或不适当。例如,可以使用一些风格分析、情感分析、创造评估、观点分析、目标分析等工具或模型,来检测和修正LLMs生成的文本中的创造幻觉。
根据前文提出的幻觉的程度和影响,我们可以将幻觉的评测标准分为以下四类:
语法正确性(Grammatical Correctness):指LLMs生成的文本在语法上是否符合语言的规则和习惯,如拼写、标点、词序、时态、主谓一致等。这个标准可以通过一些自动或人工的语法检查工具或方法来评估,如BLEU、ROUGE、BERTScore等。
语义合理性(Semantic Reasonableness):指LLMs生成的文本在语义上是否符合语言的意义和逻辑,如词义、指代、逻辑、歧义、矛盾等。这个标准可以通过一些自动或人工的语义分析工具或方法来评估,如METEOR、MoverScore、BERTScore等。
知识一致性(Knowledge Consistency):指LLMs生成的文本在知识上是否符合真实的事实或证据,或者与输入或上下文的信息是否一致,如事实、证据、引用、匹配等。这个标准可以通过一些自动或人工的知识检索或验证工具或方法来评估,如FEVER、FactCC、BARTScore等。
创造适当性(Creative Appropriateness):指LLMs生成的文本在创造上是否符合任务或目标的要求,或者与用户的偏好或期望是否相符,或者与用户的情绪或态度是否协调,或者与用户的交流或互动是否有助,如风格、情感、观点、目标等。这个标准可以通过一些自动或人工的创造评估或反馈工具或方法来评估,如BLEURT、BARTScore、SARI等。
4.LLMs幻觉的缓解方法
为了更好地解决LLMs中的幻觉问题,我们需要有效地缓解和减少LLMs生成的幻觉。根据不同的层次和角度,作者将幻觉的缓解方法分为以下几类:
后生成细化(Post-generation Refinement)
后生成细化是在LLMs生成文本后,对文本进行一些检查和修正,以消除或减少幻觉。这类方法的优点是不需要对LLMs进行重新训练或调整,可以直接应用于任何LLMs。这类方法的缺点是可能无法完全消除幻觉,或者可能引入新的幻觉,或者可能损失一些原始文本的信息或创造性。这类方法的代表有:
RARR(Refinement with Attribution and Retrieved References):(Chrysostomou和Aletras,2021)提出了一种基于归因和检索的细化方法,用于提高LLMs生成的文本的忠实度。使用一个归因模型来识别LLMs生成的文本中的每个词,是来自于输入的信息还是来自于LLMs的参数知识,或者还是来自于LLMs的生成策略。使用一个检索模型,来从外部的知识源中检索一些与输入的信息相关的参考文本。最后使用一个细化模型,来根据归因结果和检索结果,对LLMs生成的文本进行修正,以提高其与输入的信息的一致性和可信度。
High Entropy Word Spotting and Replacement(HEWSR):(Zhang等,2021)提出了一种基于熵的细化方法,用于减少LLMs生成的文本中的幻觉。首先使用一个熵计算模型,来识别LLMs生成的文本中的高熵词,即那些在生成时具有较高不确定性的词。然后使用一个替换模型,来从输入的信息或外部的知识源中选择一个更合适的词,来替换高熵词。最后使用一个平滑模型,来对替换后的文本进行一些调整,以保持其语法和语义的连贯性。
ChatProtect(Chat Protection with Self-Contradiction Detection):(Wang等,2021)提出了一种基于自我矛盾检测的细化方法,用于提高LLMs生成的聊天对话的安全性。首先使用一个矛盾检测模型,来识别LLMs生成的对话中的自我矛盾,即那些与之前的对话内容相冲突的内容。然后使用一个替换模型,来从一些预定义的安全回复中选择一个更合适的回复,来替换自我矛盾的回复。最后使用一个评估模型,来对替换后的对话进行一些评分,以衡量其安全性和流畅性。
反馈和推理的自我完善(Self-improvement with Feedback and Reasoning)
反馈和推理的自我完善是在LLMs生成文本的过程中,对文本进行一些评估和调整,以消除或减少幻觉。这类方法的优点是可以实时地监测和纠正幻觉,可以提高LLMs的自我学习和自我调节能力。这类方法的缺点是可能需要对LLMs进行一些额外的训练或调整,或者可能需要一些外部的信息或资源。这类方法的代表有:
Self-Reflection Methodology(SRM):(Iyer等,2021)提出了一种基于自我反馈的完善方法,用于提高LLMs生成的医学问答的可靠性。该方法首先使用一个生成模型,来根据输入的问题和背景,生成一个初始的答案。然后使用一个反馈模型,来根据输入的问题和背景,生成一个反馈问题,用于检测初始答案中的潜在的幻觉。接着使用一个回答模型,来根据反馈问题,生成一个回答,用于验证初始答案的正确性。最后使用一个修正模型,来根据回答的结果,对初始答案进行修正,以提高其可靠性和准确性。
Structured Comparative(SC)reasoning:(Yan等,2021)提出了一种基于结构化比较的推理方法,用于提高LLMs生成的文本偏好预测的一致性。该方法使用一个生成模型,来根据输入的文本对,生成一个结构化的比较,即在不同的方面下,对文本对进行比较和评价。使用一个推理模型,来根据结构化的比较,生成一个文本偏好的预测,即选择文本对中的哪一个更优。使用一个评估模型,来根据预测的结果,对生成的比较进行评估,以提高其一致性和可信度。
Think While Effectively Articulating Knowledge(TWEAK):(Qiu等,2021a)提出了一种基于假设验证的推理方法,用于提高LLMs生成的知识到文本的忠实度。该方法使用一个生成模型,来根据输入的知识,生成一个初始的文本。然后使用一个假设模型,来根据初始的文本,生成一些假设,即在不同的方面下,对文本的未来的文本进行预测。接着使用一个验证模型,来根据输入的知识,验证每个假设的正确性。最后使用一个调整模型,来根据验证的结果,对初始的文本进行调整,以提高其与输入的知识的一致性和可信度。
新的解码策略(New Decoding Strategy)
新的解码策略是在LLMs生成文本的过程中,对文本的概率分布进行一些改变或优化,以消除或减少幻觉。这类方法的优点是可以直接影响生成的结果,可以提高LLMs的灵活性和效率。这类方法的缺点是可能需要对LLMs进行一些额外的训练或调整,或者可能需要一些外部的信息或资源。这类方法的代表有:
Context-Aware Decoding(CAD):(Shi等,2021)提出了一种基于对比的解码策略,用于减少LLMs生成的文本中的知识冲突。该策略使用一个对比模型,来计算LLMs在使用和不使用输入的信息时,输出的概率分布的差异。然后使用一个放大模型,来放大这个差异,使得与输入的信息一致的输出的概率更高,而与输入的信息冲突的输出的概率更低。最后使用一个生成模型,来根据放大后的概率分布,生成文本,以提高其与输入的信息的一致性和可信度。
Decoding by Contrasting Layers(DoLa):(Chuang等,2021)提出了一种基于层对比的解码策略,用于减少LLMs生成的文本中的知识幻觉。首先使用一个层选择模型,来选择LLMs中的某些层,作为知识层,即那些包含较多事实知识的层。然后使用一个层对比模型,来计算知识层和其他层在词汇空间中的对数差异。最后使用一个生成模型,来根据层对比后的概率分布,生成文本,以提高其与事实知识的一致性和可信度。
知识图谱的利用(Knowledge Graph Utilization)
知识图谱的利用是在LLMs生成文本的过程中,利用一些结构化的知识图谱,来提供或补充一些与输入的信息相关的知识,以消除或减少幻觉。这类方法的优点是可以有效地获取和融合外部的知识,可以提高LLMs的知识覆盖和知识一致性。这类方法的缺点是可能需要对LLMs进行一些额外的训练或调整,或者可能需要一些高质量的知识图谱。这类方法的代表有:
RHO(Representation of linked entities and relation predicates from a Knowledge Graph):(Ji等,2021a)提出了一种基于知识图谱的表示方法,用于提高LLMs生成的对话回复的忠实度。首先使用一个知识检索模型,来从一个知识图谱中检索一些与输入的对话相关的子图,即包含一些实体和关系的图。然后使用一个知识编码模型,来对子图中的实体和关系进行编码,得到它们的向量表示。接着使用一个知识融合模型,来将知识的向量表示融合到对话的向量表示中,得到一个增强的对话表示。最后使用一个知识生成模型,来根据增强的对话表示,生成一个忠实的对话回复。
FLEEK(FactuaL Error detection and correction with Evidence Retrieved from external Knowledge):(Bayat等,2021)提出了一种基于知识图谱的验证和修正方法,用于提高LLMs生成的文本的事实性。该方法首先使用一个事实识别模型,来识别LLMs生成的文本中的潜在的可验证的事实,即那些可以在知识图谱中找到证据的事实。然后使用一个问题生成模型,来为每个事实生成一个问题,用于查询知识图谱。接着使用一个知识检索模型,来从知识图谱中检索一些与问题相关的证据。最后使用一个事实验证和修正模型,来根据证据,验证和修正LLMs生成的文本中的事实,以提高其事实性和准确性。
基于忠实度的损失函数(Faithfulness-based Loss Function)
基于忠实度的损失函数是在LLMs训练或微调的过程中,使用一些衡量生成文本与输入信息或真实标签之间一致性的指标,作为损失函数的一部分,以消除或减少幻觉。这类方法的优点是可以直接影响LLMs的参数优化,可以提高LLMs的忠实度和准确度。这类方法的缺点是可能需要对LLMs进行一些额外的训练或调整,或者可能需要一些高质量的标注数据。这类方法的代表有:
Text Hallucination Mitigating(THAM)Framework:(Yoon等,2022)提出了一种基于信息论的损失函数,用于减少LLMs生成的视频对话中的幻觉。首先使用一个对话语言模型,来计算对话的概率分布。然后使用一个幻觉语言模型,来计算幻觉的概率分布,即那些从输入的视频中无法获取的信息的概率分布。接着使用一个互信息模型,来计算对话和幻觉的互信息,即对话中包含幻觉的程度互信息。最后使用一个交叉熵模型,来计算对话和真实标签的交叉熵,即对话的准确性。该损失函数的目标是最小化互信息和交叉熵的和,从而减少对话中的幻觉和错误。
Factual Error Correction with Evidence Retrieved from external Knowledge(FECK):(Ji等,2021b)提出了一种基于知识证据的损失函数,用于提高LLMs生成的文本的事实性。首先使用一个知识检索模型,来从一个知识图谱中检索一些与输入的文本相关的子图,即包含一些实体和关系的图。然后使用一个知识编码模型,来对子图中的实体和关系进行编码,得到它们的向量表示。接着使用一个知识对齐模型,来对齐LLMs生成的文本中的实体和关系,与知识图谱中的实体和关系,得到它们的匹配程度。最后,该损失函数使用一个知识损失模型,来计算LLMs生成的文本中的实体和关系,与知识图谱中的实体和关系,之间的距离,即事实的偏差。该损失函数的目标是最小化知识损失,从而提高LLMs生成的文本的事实性和准确性。
提示微调(Prompt Tuning)
提示微调是在LLMs生成文本的过程中,使用一些特定的文本或符号,作为输入的一部分,来控制或引导LLMs的生成行为,以消除或减少幻觉。这类方法的优点是可以有效地调节和指导LLMs的参数知识,可以提高LLMs的适应性和灵活性。这类方法的缺点是可能需要对LLMs进行一些额外的训练或调整,或者可能需要一些高质量的提示。这类方法的代表有:
UPRISE(Universal Prompt-based Refinement for Improving Semantic Equivalence):(Chen等,2021)提出了一种基于通用提示的微调方法,用于提高LLMs生成的文本的语义等价性。首先使用一个提示生成模型,来根据输入的文本,生成一个通用的提示,即一些用于引导LLMs生成语义等价的文本的文本或符号。然后使用一个提示微调模型,来根据输入的文本和提示,微调LLMs的参数,使其更倾向于生成与输入的文本语义等价的文本。最后,该方法使用一个提示生成模型,来根据微调后的LLMs的参数,生成一个语义等价的文本。
SynTra(Synthetic Task for Hallucination Mitigation in Abstractive Summarization):(Wang等,2021)提出了一种基于合成任务的微调方法,用于减少LLMs生成的摘要中的幻觉。首先使用一个合成任务生成模型,来根据输入的文本,生成一个合成的任务,即一个用于检测摘要中的幻觉的问题。然后使用一个合成任务微调模型,来根据输入的文本和任务,微调LLMs的参数,使其更倾向于生成与输入的文本一致的摘要。最后使用一个合成任务生成模型,来根据微调后的LLMs的参数,生成一个一致的摘要。
5.LLMs幻觉的挑战和局限性
尽管LLMs中的幻觉缓解技术已经取得了一些进展,但仍然存在一些挑战和局限性,需要进一步的研究和探索。以下是一些主要的挑战和局限性:
幻觉的定义和度量:没有一个统一和明确的定义和度量,不同的研究可能使用不同的标准和指标,来判断和评估LLMs生成的文本中的幻觉。这导致了一些不一致和不可比较的结果,也影响了LLMs中幻觉问题的理解和解决。因此,需要建立一个通用和可靠的幻觉的定义和度量,以便于对LLMs中的幻觉进行有效的检测和评估。
幻觉的数据和资源:缺乏一些高质量和大规模的数据和资源,来支持LLMs中幻觉的研究和开发。例如,缺乏一些包含幻觉标注的数据集,来训练和测试LLMs中幻觉的检测和缓解方法;缺乏一些包含真实事实和证据的知识源,来提供和验证LLMs生成的文本中的知识;缺乏一些包含用户反馈和评价的平台,来收集和分析LLMs生成的文本中的幻觉的影响。因此,需要构建一些高质量和大规模的数据和资源,以便于对LLMs中的幻觉进行有效的研究和开发。
幻觉的原因和机制:没有一个深入和全面的原因和机制的分析,来揭示和解释LLMs为什么会产生幻觉,以及幻觉是如何在LLMs中形成和传播的。例如,不清楚LLMs中的参数知识、非参数知识和生成策略是如何相互影响和作用的,以及它们是如何导致不同类型、程度和影响的幻觉的。因此,需要进行一些深入和全面的原因和机制的分析,以便于对LLMs中的幻觉进行有效的预防和控制。
幻觉的解决和优化:没有一个完善和通用的解决和优化的方案,来消除或减少LLMs生成的文本中的幻觉,以及提高LLMs生成的文本的质量和效果。例如,不清楚如何在不损失LLMs的泛化能力和创造力的前提下,提高LLMs的忠实度和准确度。因此,需要设计一些完善和通用的解决和优化的方案,以便于提高LLMs生成的文本的质量和效果。
以上是对大规模机器学习中幻觉缓解技术的综合研究的详细内容。更多信息请关注PHP中文网其他相关文章!