
评估清华大学研发的 LLM4VG 基准在视频时序定位方面的性能

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB转载
- 2024-01-04 22:38:141201浏览

12 月 29 日消息,大语言模型(LLM)的触角已经从单纯的自然语言处理,扩展到文本、音频、视频等多模态领域,而其中一项关键就是视频时序定位(Video Grounding,VG)。
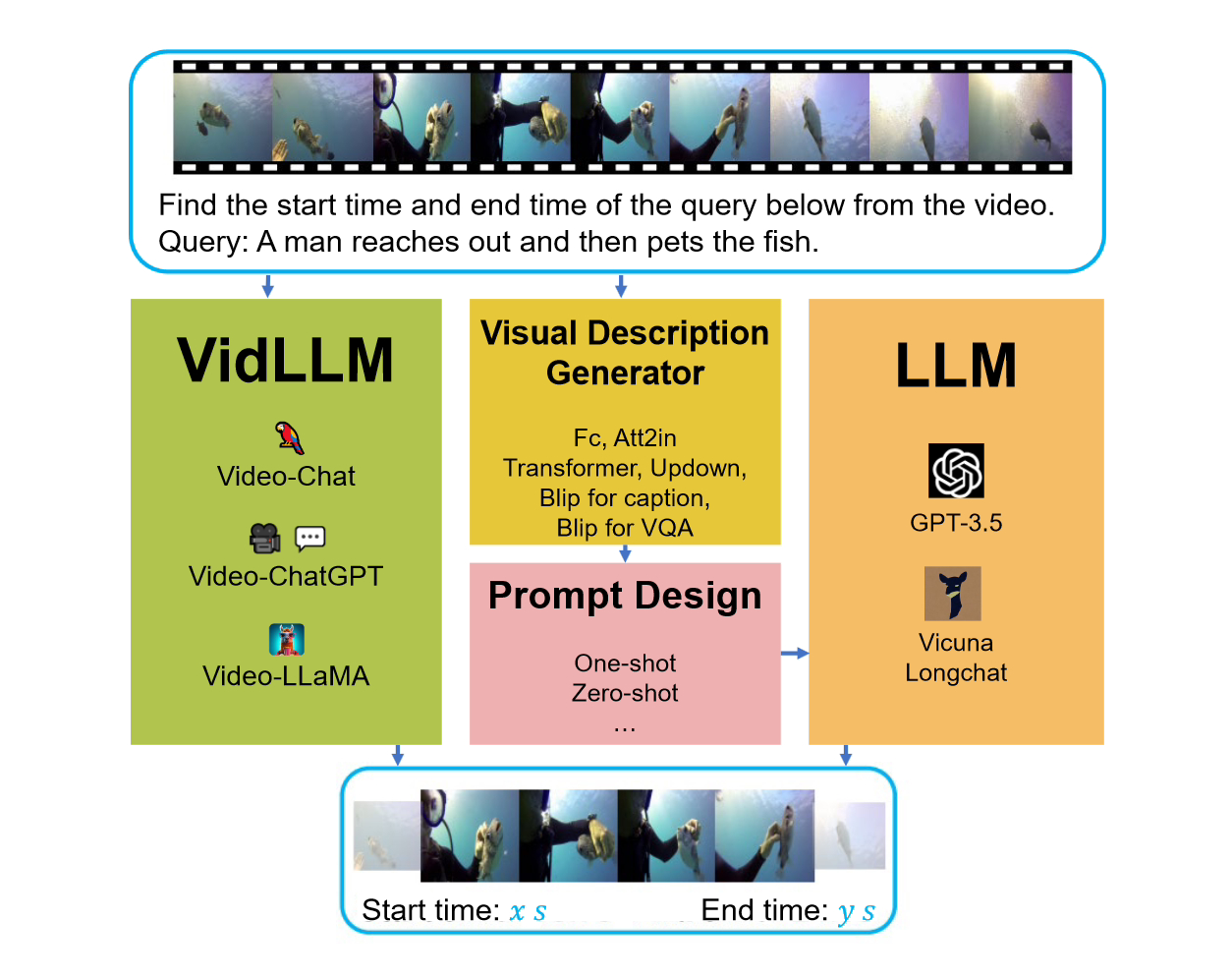
VG任务的目标是根据给定的查询,定位目标视频段的起始和结束时间。这个任务的核心挑战在于准确确定时间边界。
清华大学研究团队近日推出了“LLM4VG”基准,这是一个专门设计用于评估 LLM 在 VG 任务中的性能。
在考虑此基准的时候,有两种主要的策略被考虑了。第一种策略是直接在文本视频数据集(VidLLM)上训练视频语言模型(LLM)。这种方法是通过在大规模的视频数据集上进行训练,来学习视频和语言之间的关联,以提高模型的性能。 第二种策略是将传统的语言模型(LLM)与预训练的视觉模型结合起来。这种方法是基于预训练的视觉模型,将视频的视觉特

在一种策略中,VidLLM模型直接处理视频内容和VG任务指令,并根据其训练输出预测文本-视频之间的关系。
第二种策略则更加复杂,它涉及到LLM(Language and Vision Models)和视觉描述模型的运用。这些模型能够生成与VG(Video Game)任务指令相结合的视频内容的文本描述,而这些描述经过精心设计的提示来实现。
这些提示是经过精心设计的,它们的目的是将VG的指令和提供的视觉描述有效地结合起来,以帮助LLM处理和理解与任务相关的视频内容。
据观察,VidLLM 尽管直接在视频内容上进行训练,但在实现令人满意的 VG 性能方面仍然存在很大差距。这一发现强调了在训练中纳入更多与时间相关的视频任务以提高性能的必要性。

而第二种策略优于 VidLLM,为未来的研究指明了一个有希望的方向。该策略主要限制于视觉模型的局限性和提示词的设计,因此能够生成详细且准确的视频描述后,更精细的图形模型可以大幅提高 LLM 的 VG 性能。
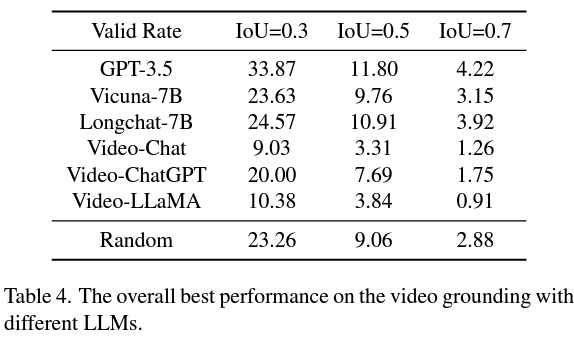
总之,该研究对 LLM 在 VG 任务中的应用进行了开创性的评估,强调了在模型训练和提示设计中需要更复杂的方法。
本站附上论文参考地址:https://www.php.cn/link/a7fd9fd835f54f0f28003c679fd44b39
以上是评估清华大学研发的 LLM4VG 基准在视频时序定位方面的性能的详细内容。更多信息请关注PHP中文网其他相关文章!