
OpenAI加强安全团队,授予其权力以否决危险人工智能

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB转载
- 2023-12-19 17:30:411390浏览
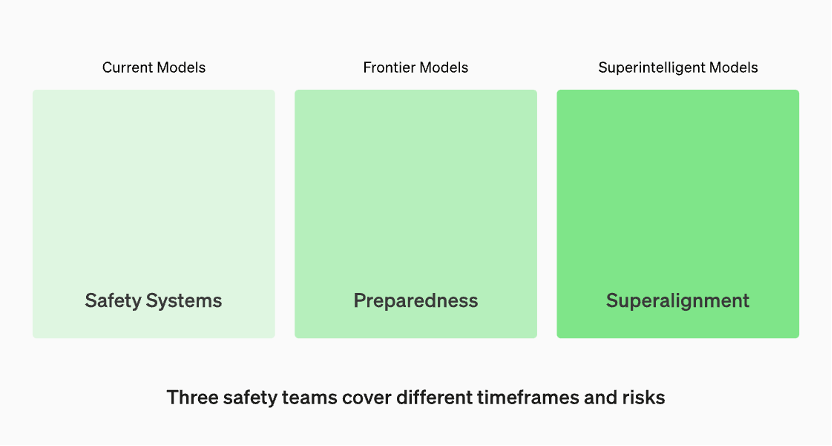
生产中的模型由“安全系统”团队管理。开发中的前沿模型有“准备”团队,该团队会在模型发布之前识别和量化风险。然后是“超级对齐”团队,他们正在研究“超级智能”模型的理论指南
将安全顾问小组重新组建,使其位于技术团队之上,以便向领导层提出建议,并给予董事会否决的权力
OpenAI宣布,为了抵御有害人工智能的威胁,他们正在加强内部的安全流程。他们将设立一个名为“安全顾问小组”的新部门,该部门将位于技术团队之上,向领导层提供建议,并被授予董事会否决权。这一决定于当地时间12月18日宣布
更新引起关注的原因主要是因为OpenAI首席执行官山姆·奥特曼被董事会解雇,而这似乎与大型模型的安全问题有关。在高层人事变动后,OpenAI董事会的两位“减速主义”成员伊尔亚·苏茨克维和海伦·托纳失去了董事会席位
在这篇文章中,OpenAI讨论了他们最新的“准备框架”,即OpenAI如何跟踪、评估、预测和防范日益强大的模型所带来的灾难性风险。灾难性风险的定义是什么?OpenAI解释道,“我们所说的灾难性风险是指可能导致数千亿美元经济损失,或者导致许多人严重伤害或死亡的风险,这也包括但不限于生存风险。”
有三组安全团队分别覆盖不同的时间框架和风险
根据OpenAI官网的资料,生产中的模型由“安全系统”团队负责管理。而在开发阶段,有一个名为“准备”的团队,他们会在模型发布之前识别和评估风险。此外,还有一个名为“超级对齐”(superalignment)的团队,他们正在研究“超级智能”(superintelligent)模型的理论指南
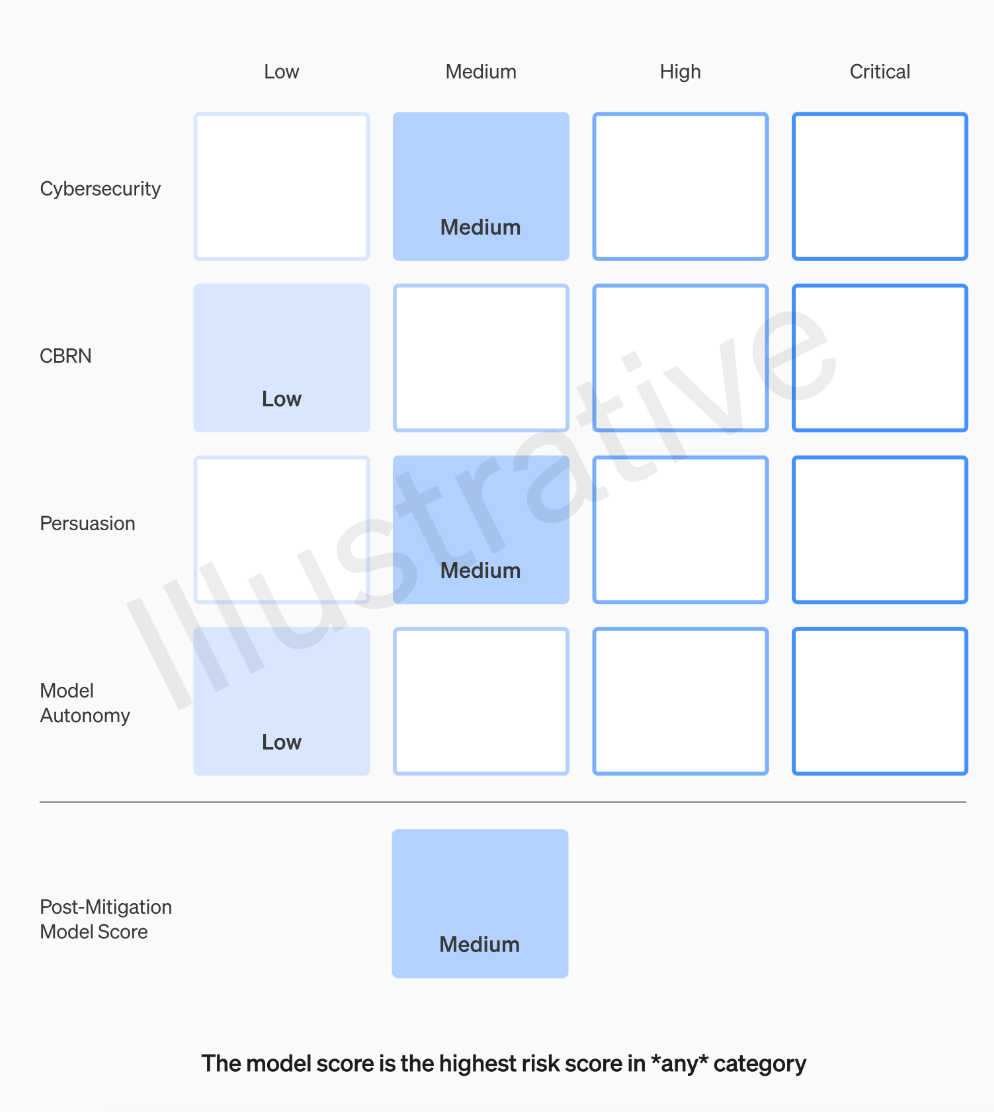
OpenAI团队将对每个模型根据四个风险类别进行评级,这四个类别分别是网络安全、说服能力(如虚假信息)、模型自主性(即自主行为能力)以及CBRN(化学、生物、放射性和核威胁,例如创造新病原体的能力)
OpenAI在假设中考虑了各种缓解措施:例如,该模型对于描述制作凝固汽油或管式炸弹的过程保持着合理的保留态度。在考虑已知的缓解措施后,如果一个模型仍然被评估为具有“高”风险,它将无法被部署,如果一个模型存在任何“关键”风险,将不会进一步开发
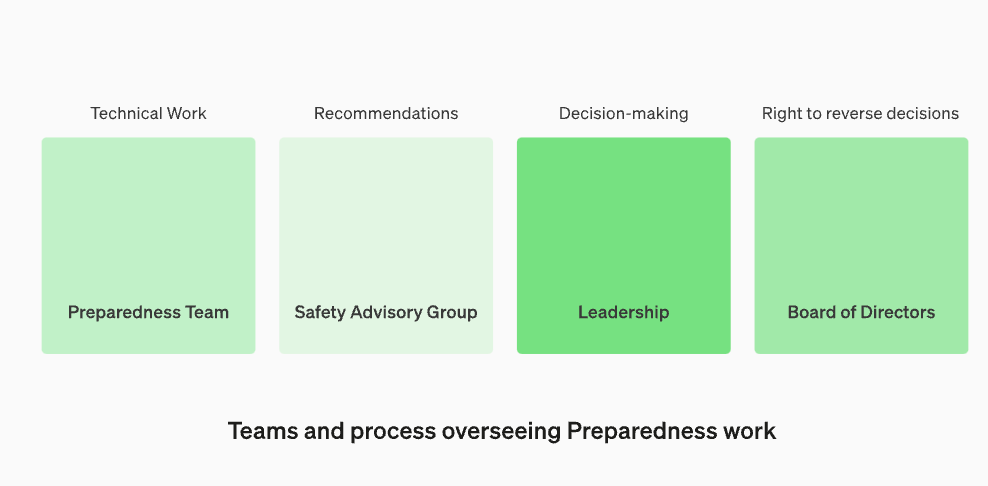
并非所有制作模型的人都是评估模型和提出建议的最佳人选。出于这个原因,OpenAI正在建立一个名为“跨职能安全咨询小组”的团队,该团队将从技术层面审查研究人员的报告,并从更高的角度提出建议,希望能够发现一些“未知的未知”
这个过程要求将这些建议同时发送给董事会和领导层,领导层将决定是否继续或停止运行,但董事会有权撤销这些决定。这样可以避免高风险产品或流程在董事会不知情的情况下获得批准
然而,外界仍然担心的是,如果专家小组提出建议,首席执行官根据这些信息做出决策,OpenAI的董事会是否真的有权利进行反驳并采取行动?如果他们这样做了,公众会听到相关声音吗?目前,除了OpenAI承诺征求独立第三方审计之外,他们的透明度问题实际上并没有得到真正的解决
OpenAI的“准备框架”包含以下五个关键要素:
1. 评估和打分
我们将对我们的模型进行评估,并持续更新我们的“记分卡”。我们将评估所有最新的模型,包括在训练期间将有效计算量增加两倍。我们将推动模型的极限。这些发现将有助于我们评估最新模型的风险,并衡量任何拟议的缓解措施的有效性。我们的目标是探测特定边缘的不安全因素,以有效地减轻风险。为了跟踪我们模型的安全水平,我们将制作风险“记分卡”和详细报告
要评估所有前沿模型,需要使用“记分卡”
设定风险阈值的目的是为了在进行决策和管理风险时能够有一个明确的界限。风险阈值是指在特定情况下,组织或个人愿意承受的最大风险水平。通过设定风险阈值,可以帮助组织或个人识别出何时需要采取行动来减轻风险或避免风险。风险阈值的设定应基于风险评估的结果、相关法规和政策以及组织或个人的风险承受能力。在设定风险阈值时,需要考虑到不同风险类型的特点和影响程度,以确保风险管理措施的有效性和适用性。最后,设定的风险阈值应定期进行评估和调整,以保持与组织或个人的风险管理目标相一致
我们将设定触发安全措施的风险阈值。我们根据以下初步追踪类别设定了风险级别的阈值:网络安全、CBRN(化学、生物、放射性、核威胁)、说服和模型自主。我们指定了四个安全风险级别,只有缓解后得分为“中”或以下的模型才能被部署;只有缓解后得分为“高”或以下的模型才能进一步开发。对于具有高风险或严重风险(缓解前)的模型,我们还将实施额外的安全措施

危险水平
重新设定监督技术工作和安全决策运营结构
我们将设立一个专门的团队来监督技术工作和安全决策的运营结构。准备团队将推动技术工作,以检查前沿模型的能力极限,并进行评估和综合报告。这项技术工作对于OpenAI安全模型的开发和部署决策至关重要。我们正在创建一个跨职能的安全咨询小组,以审查所有报告,并同时发送给领导层和董事会。尽管领导层是决策者,但董事会拥有推翻决定的权力
监督技术工作和安全决策运营结构的新变化
增强安全性和加强对外部问责制
我们将制定协议以提高安全性和外部责任。我们将定期进行安全演习,以压力测试我们的业务和自身文化。一些安全问题可能会迅速出现,因此我们有能力标记紧急问题以进行快速响应。我们认为,从OpenAI外部人员那里获得反馈并由合格的独立第三方进行审核是很有帮助的。我们将继续让其他人组成红队并评估我们的模型,并计划与外部共享更新
减少其他已知和未知的安全风险:
我们将协助减少其他已知和未知的安全风险。我们将与外部各方以及内部的安全系统等团队密切合作,以跟踪现实世界中的滥用情况。我们还将与“超级对齐”合作,跟踪紧急的错位风险。我们还开创了新的研究,以衡量风险随着模型规模扩展而演变的情况,并帮助提前预测风险,这类似于我们早期在规模法则方面取得的成功。最后,我们将进行连续的流程,以尝试解决任何新出现的“未知的未知”
以上是OpenAI加强安全团队,授予其权力以否决危险人工智能的详细内容。更多信息请关注PHP中文网其他相关文章!