



近年来,在预训练的扩散模型[1, 2, 3]的发展推动下,自动将文本转化为3D内容取得了重要的进展。其中,DreamFusion[4]引入了一种有效的方法,该方法利用预训练的2D扩散模型[5]从文本中自动生成3D资产,而无需专门的3D资产数据集
DreamFusion 引入的一项关键创新是分数蒸馏采样 (SDS) 算法。该算法利用预训练的 2D 扩散模型对单个 3D 表示进行评估,例如 NeRF [6],从而对其进行优化,以确保来自任何摄像机视角的渲染图像与给定文本保持较高的一致性。受开创性 SDS 算法的启发,出现了几项工作 [7,8,9,10,11],通过应用预训练的 2D 扩散模型来推进 text-to-3D 生成任务。
虽然 text-to-3D 的生成通过利用预训练的 text-to-2D 的扩散模型已经取得了重大进展,但是 2D 图像和 3D 资产之间仍存在很大的领域差距。这种区别在图 1 中清楚地展示出来。
首先,text-to-2D 模型产生与相机无关的生成结果,专注于从特定角度生成高质量图像,而忽略其他角度。相比之下,3D 内容创建与相机参数 (如位置、拍摄角度和视场) 错综复杂地联系在一起。因此,text-to-3D 模型必须在所有可能的相机参数上生成高质量的结果。
此外,text-to-2D生成模型需要同时生成前景和背景元素,以保持图像的整体连贯性。与此相反,text-to-3D生成模型只需专注于创建前景对象。这个区别使得text-to-3D模型能够分配更多资源和注意力来准确表示和生成前景对象。因此,当直接使用预训练的2D扩散模型来进行3D资产创建时,text-to-2D和text-to-3D生成之间的领域差异成为明显的性能障碍

图 1 text-to-2D 生成模型 (左) 和 text-to-3D 生成模型 (右) 在同一文本提示下的输出,即 "A statue of Leonardo DiCaprio's head.”。
为了解决这个问题,论文提出了 X-Dreamer,这是一种用于高质量 text-to-3D 内容创建的新颖方法,可以有效地弥合 text-to-2D 和 text-to-3D 生成之间的领域差距。
X-Dreamer 的关键组成部分是两种创新设计: Camera-Guided Low-Rank Adaptation (CG-LoRA) 和 Attention-Mask Alignment (AMA) 损失。
首先,现有方法 [7,8,9,10] 通常采用 2D 预训练扩散模型 [5,12] 来进行 text-to-3D 生成,缺乏与相机参数的固有联系。为了解决此限制并确保 X-Dreamer 产生直接受相机参数影响的结果,论文引入了 CG-LoRA 来调整预训练的 2D 扩散模型。值得注意的是,在每次迭代期间 CG-LoRA 的参数都是基于相机信息动态生成的,从而在 text-to-3D 模型和相机参数之间建立鲁棒的关系。
其次,预训练的 text-to-2D 扩散模型将注意力分配给前景和背景生成,而 3D 资产的创建需要更加关注前景对象的准确生成。为了解决这一问题,论文提出了 AMA 损失,使用 3D 对象的二进制掩码来指导预训练的扩散模型的注意力图,从而优先考虑前景对象的创建。通过合并该模块,X-Dreamer 优先考虑前景对象的生成,从而显着提高了生成的 3D 内容的整体质量。

项目主页:
https://xmu-xiaoma666.github.io/Projects/X-Dreamer/
Github主页:https://github.com/xmu-xiaoma666/X-Dreamer
论文地址:https://arxiv.org/abs/2312.00085
X-Dreamer 对 text-to-3D 生成领域做出了如下贡献:
- 论文提出了一种新颖的方法,X-Dreamer,用于高质量的 text-to-3D 内容创建,有效地弥合了 text-to-2D 和 text-to-3D 生成之间的主要差距。
- 为了增强生成的结果与相机视角之间的对齐,论文提出了 CG-LoRA,利用相机信息来动态生成 2D 扩散模型的特定参数。
-
为了在 text-to-3D 模型中优先创建前景对象,论文引入了 AMA 损失,利用前景 3D 对象的二进制掩码来引导 2D 扩散模型的注意图。
方法
X-Dreamer包含两个主要阶段:几何学习和外观学习。对于几何学习,本研究使用DMTET作为3D表示,并利用3D椭球对其进行初始化。初始化时,损失函数采用均方误差(MSE)损失。接下来,使用分数蒸馏采样(SDS)损失和本研究提出的AMA损失来优化DMTET和CG-LoRA,以确保3D表示和输入的文本提示之间的对齐
对于外观学习,论文利用双向反射分布函数 (BRDF) 建模。具体来说,论文利用具有可训练参数的 MLP 来预测表面材料。类似于几何学习阶段,论文使用 SDS 损失和 AMA 损失来优化 MLP 和 CG-LoRA 的可训练参数,以实现 3D 表示和文本提示之间的对齐。图 2 展示了 X-Dreamer 的详细构成。

图 2 X-Dreamer 概览,包括几何学习和外观学习。
几何学习 (Geometry Learning)
在此模块中,X-Dreamer 利用 MLP 网络 将 DMTET 参数化为 3D 表示。为了增强几何建模的稳定性,本文使用 3D 椭球体作为 DMTET
将 DMTET 参数化为 3D 表示。为了增强几何建模的稳定性,本文使用 3D 椭球体作为 DMTET  的初始配置。对于属于四面体网格
的初始配置。对于属于四面体网格 的每个顶点
的每个顶点 ,本文训练
,本文训练 来预测两个重要的量:SDF 值
来预测两个重要的量:SDF 值 和变形偏移量
和变形偏移量 。为了将
。为了将 初始化为椭球体,本文采样了均匀分布在椭球体内的 N 个点,并计算相应的 SDF 值
初始化为椭球体,本文采样了均匀分布在椭球体内的 N 个点,并计算相应的 SDF 值 。随后,利用均方误差(MSE)损失来优化
。随后,利用均方误差(MSE)损失来优化 。该优化过程确保
。该优化过程确保 有效地初始化 DMTET,使其类似于 3D 椭球体。MSE 损失的公式如下:
有效地初始化 DMTET,使其类似于 3D 椭球体。MSE 损失的公式如下:

初始化几何图形后,将 DMTET 的几何图形与输入文本提示对齐。具体的操作方法是通过使用差分渲染技术,在给定随机采样的相机姿势 c 的情况下,从初始化的 DMTET 生成法线映射 n 和对象的掩码 m 。随后,将法线映射 n 输入到具有可训练 CG-LoRA 嵌入的冻结的 Stable Diffusion 模型(SD)中,并使用 SDS 损失更新
生成法线映射 n 和对象的掩码 m 。随后,将法线映射 n 输入到具有可训练 CG-LoRA 嵌入的冻结的 Stable Diffusion 模型(SD)中,并使用 SDS 损失更新 中的参数,定义如下:
中的参数,定义如下:

其中, 表示 SD 的参数,
表示 SD 的参数, 为在给定噪声水平 t 和文本嵌入 y 的情况下的 SD 的预测噪声。此外,
为在给定噪声水平 t 和文本嵌入 y 的情况下的 SD 的预测噪声。此外, ,其中
,其中 表示从正态分布采样的噪声。
表示从正态分布采样的噪声。 、
、 和
和 的实现基于 DreamFusion [4]。
的实现基于 DreamFusion [4]。
此外,为了将 SD 集中于生成前景对象,X-Dreamer 引入了额外的 AMA 损失,以将对象掩码 与 SD 的注意力图对齐,如下所示:

其中 表示注意力层的数量,
表示注意力层的数量, 是第 i 个注意力层的注意力图。函数
是第 i 个注意力层的注意力图。函数 用于调整渲染出来的 3D 对象掩码的大小,确保它的尺寸与注意力图的尺寸对齐。
用于调整渲染出来的 3D 对象掩码的大小,确保它的尺寸与注意力图的尺寸对齐。
外观学习 (Appearance Learning)
在获得 3D 对象的几何结构后,本文的目标是使用基于物理的渲染(PBR)材料模型来计算 3D 对象的外观。材料模型包括扩散项 ,粗糙度和金属项
,粗糙度和金属项 ,以及法线变化项
,以及法线变化项 。对于几何体表面上的任一点
。对于几何体表面上的任一点
,利用由 参数化的多层感知机(MLP)来获得三个材料项,具体可以表示如下:
参数化的多层感知机(MLP)来获得三个材料项,具体可以表示如下:

其中, 表示利用哈希网格技术进行位置编码。之后,可以使用如下公式计算渲染图像的每个像素:
表示利用哈希网格技术进行位置编码。之后,可以使用如下公式计算渲染图像的每个像素:

其中, 表示从方向
表示从方向 渲染 3D 物体表面的点
渲染 3D 物体表面的点 的像素值。
的像素值。 表示由满足条件
表示由满足条件 的入射方向集合
的入射方向集合 定义的半球,其中
定义的半球,其中 表示入射方向,
表示入射方向, 表示点
表示点 处的表面法线。
处的表面法线。 对应于来自现成环境图的入射光,
对应于来自现成环境图的入射光, 是与材料特性(即
是与材料特性(即 )相关的双向反射分布函数 (BRDF)。通过聚合所有渲染的像素颜色,可以获得渲染图像
)相关的双向反射分布函数 (BRDF)。通过聚合所有渲染的像素颜色,可以获得渲染图像 。与几何学习阶段类似,将渲染图像
。与几何学习阶段类似,将渲染图像 输入 SD,利用 SDS 损失和 AMA 损失优化
输入 SD,利用 SDS 损失和 AMA 损失优化 。
。
摄像头引导的低秩适应(CG-LoRA)
为了解决生成文本到2D和3D之间存在的领域差距所导致的次优3D结果生成问题,X-Dreamer提出了基于相机引导的低秩适应方法
如图 3 所示,利用摄像机参数和方向感知文本来指导 CG-LoRA 中参数的生成,使 X-Dreamer 能够有效地感知摄像机的位置和方向信息。

图 3 摄像机引导的 CG-LoRA 示意。
具体的,给定文本提示 和相机参数
和相机参数 ,首先使用预训练的文本 CLIP 编码器
,首先使用预训练的文本 CLIP 编码器 和可训练的 MLP
和可训练的 MLP ,将这些输入投影到特征空间中:
,将这些输入投影到特征空间中:

其中, 和
和 分别是是文本特征和相机特征。之后,使用两个低秩矩阵将
分别是是文本特征和相机特征。之后,使用两个低秩矩阵将 和
和 投影到 CG-LoRA 中的可训练降维矩阵中:
投影到 CG-LoRA 中的可训练降维矩阵中:

其中, 和
和 是 CG-LoRA 的两个降维矩阵。函数
是 CG-LoRA 的两个降维矩阵。函数
用于将张量的形状从变换 为
为 。
。
 和
和 是两个低秩矩阵。因此,可以将它们分解为两个矩阵的乘积,以减少实现中的可训练参数,即
是两个低秩矩阵。因此,可以将它们分解为两个矩阵的乘积,以减少实现中的可训练参数,即 ;
; ,其中
,其中 ,
, ,
, ,
, ,
, 是一个很小的数字(如:4)。根据 LoRA 的构成,将维度扩展矩阵
是一个很小的数字(如:4)。根据 LoRA 的构成,将维度扩展矩阵 初始化为零,以确保模型开始使用 SD 的预训练参数进行训练。因此,CG-LoRA 的前馈过程公式如下:
初始化为零,以确保模型开始使用 SD 的预训练参数进行训练。因此,CG-LoRA 的前馈过程公式如下:

其中,  表示预训练的 SD 模型的冻结参数,
表示预训练的 SD 模型的冻结参数, 是级联运算。在本方法的实现中,将 CG-LoRA 集成到 SD 中注意力模块的线性嵌入层中,以有效地捕捉方向和相机信息。
是级联运算。在本方法的实现中,将 CG-LoRA 集成到 SD 中注意力模块的线性嵌入层中,以有效地捕捉方向和相机信息。
需要重新表达的内容是:注意力蒙版对齐损失(AMA损失)
SD 被预训练以生成 2D 图像,同时考虑了前景和背景元素。然而,text-to-3D 的生成需要更加重视前景对象的生成。鉴于这一要求,X-Dreamer 提出了 Attention-Mask Alignment Loss(AMA 损失),以将 SD 的注意力图与 3D 对象的渲染的掩码图像对齐。具体的,对于预训练的 SD 中的每个注意力层,本方法使用查询图像特征 和关键 CLS 标记特征
和关键 CLS 标记特征 来计算注意力图。计算公式如下:
来计算注意力图。计算公式如下:

其中, 表示多头注意力机制中的头的数量,
表示多头注意力机制中的头的数量, 表示注意力图,之后,通过对所有注意力头中注意力图
表示注意力图,之后,通过对所有注意力头中注意力图 的注意力值进行平均来计算整体注意力图
的注意力值进行平均来计算整体注意力图 的值。
的值。
由于使用 softmax 函数对注意力图值进行归一化,因此当图像特征分辨率较高时,注意力图中的激活值可能变得非常小。但是,考虑到渲染的 3D 对象掩码中的每个元素都是 0 或 1 的二进制值,因此将注意力图与渲染的 3D 对象的掩码直接对齐不是最佳的。为了解决这个问题,论文提出了一种归一化技术,该技术将注意力图中的值映射到(0,1)之间。此归一化过程的公式如下:

其中, 代表一个小的常数值 (例如
代表一个小的常数值 (例如 ),来防止分母中出现 0。最后,使用 AMA 损失将所有注意力层的注意力图与 3D 对象的渲染的掩码对齐。
),来防止分母中出现 0。最后,使用 AMA 损失将所有注意力层的注意力图与 3D 对象的渲染的掩码对齐。
实验结果
论文使用四个 Nvidia RTX 3090 GPU 和 PyTorch 库进行实验。为了计算 SDS 损失,利用了通过 Hugging Face Diffusers 实现的 Stable Diffusion 模型。对于 DMTET 和 material 编码器,将它们分别实现为两层 MLP 和单层 MLP,隐藏层维度为 32。
从椭球体开始进行 text-to-3D 的生成
论文展示了 X-Dreamer 利用椭球作为初始几何形状的 text-to-3D 的生成结果,如图 4 所示。结果证明 X-Dreamer 具有生成高质量和照片般逼真的 3D 对象的能力,生成的 3D 对象与输入的文本提示准确对应。

图 4 以椭球体为起点进行了 text-to-3D 的生成
从粗粒度网格开始进行 text-to-3D 的生成
虽然可以从互联网上下载大量粗粒度网格,但由于缺乏几何细节,直接使用这些网格创建 3D 内容往往会导致性能较差。然而,与 3D 椭球体相比,这些网格可以为 X-Dreamer 提供更好的 3D 形状先验信息。
因此,也可以使用粗粒度引导网格来初始化 DMTET,而不是使用椭球。如图 5 所示,X-Dreamer 可以基于给定的文本生成具有精确几何细节的 3D 资产,即使所提供的粗粒度网格缺乏细节。

图 5 从粗粒度网格开始进行 text-to-3D 的生成。
需要重写的内容是:Qualitative Comparison.
为了评估X-Dreamer的有效性,本论文将其与四种先进方法进行比较:DreamFusion [4],Magic3D [8],Fantasia3D [7]和ProlificDreamer [11],如图6所示
当与基于 SDS 的方法进行比较时 [4,7,8],X-Dreamer 在生成高质量和逼真的 3D 资产方面优于他们。此外,与基于 VSD 的方法 [11] 相比,X-Dreamer 产生的 3D 内容具有相当甚至更好的视觉效果,同时需要的优化时间明显减少。具体来说,X-Dreamer 的几何形状和外观学习过程只需要大约 27 分钟,而 ProlificDreamer 则超过 8 小时。

图 6 与现有技术 (SOTA) 方法的比较。
需要重新写的内容是:消融实验
- 模块消融
为了深入了解CG-LoRA 和AMA 损失的能力,论文进行了消融研究,其中每个模块单独加入以评估其影响。如图 7 所示,消融结果表明,当 CG-LoRA 被排除在 X-Dreamer 之外时,生成的 3D 对象的几何形状和外观质量显着下降。
此外,X-Dreamer 缺失 AMA 损失也对生成的 3D 资产的几何形状和外观保真度产生有害影响。这些需要重新写的内容是:消融实验为 CG-LoRA 和 AMA 损失在增强生成的 3D 对象的几何形状、外观和整体质量方面的单独贡献提供了有价值的研究。

图 7 X-Dreamer 的消融研究。
- 有无 AMA 损失的注意力图比较
引入 AMA 损失的目的在于将去噪过程中的注意力集中于前景对象。实现这一目标的方法是通过将 SD 的注意力图与 3D 对象的渲染掩码对齐。为了评估AMA 损失在实现该目标方面的有效性,本文在几何学习和外观学习阶段分别比较了有和没有AMA 损失的SD 的注意力图
根据图8所示,可以观察到,添加AMA损失不仅能改善生成的3D资产的几何形状和外观,还能使SD的注意力特别集中在前景对象区域上。可视化结果证实了AMA损失在引导SD注意力方面的有效性,从而提高了几何和外观学习阶段的质量和前景对象的聚焦

需要重新写作的内容是:图8展示了注意力图、渲染掩码和渲染图像的可视化结果,其中包括和不包括AMA损失
这项研究引入了一个名为X-Dreamer的开创性框架,旨在通过解决文本到二维和文本到三维生成之间的领域差距来增强文本到三维的生成。为了实现这一目标,论文首先提出了CG-LoRA,该模块将三维相关信息(包括方向感知文本和相机参数)合并到预训练的稳定扩散(SD)模型中。通过这样做,本文能够有效地捕捉与三维领域相关的信息。此外,本文设计了AMA损失,以将SD生成的注意力图与三维对象的渲染掩码对齐。 AMA损失的主要目标是引导文本到三维模型的焦点朝着前景对象的生成方向发展。通过广泛的实验,本文全面评估了提出方法的有效性,并证明了X-Dreamer能够根据给定的文本提示生成高质量和真实的三维内容
以上是突破次元壁,X-Dreamer带来高质量的文本到3D生成,融合2D和3D生成领域的详细内容。更多信息请关注PHP中文网其他相关文章!

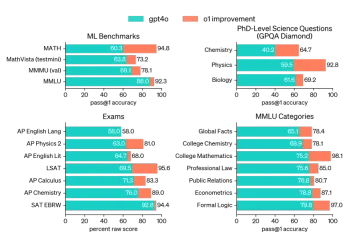 AV字节:Openai' apple apple and visual ai等 - 分析vidhyaApr 12, 2025 am 09:38 AM
AV字节:Openai' apple apple and visual ai等 - 分析vidhyaApr 12, 2025 am 09:38 AM介绍 本周,人工智能(AI)世界上充满了重大更新。从OpenAI的O1模型展示高级推理到苹果的开创性视觉智能技术,Tech
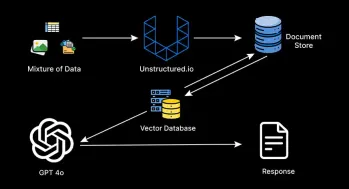
 如何监视生产级代理抹布管道?Apr 12, 2025 am 09:34 AM
如何监视生产级代理抹布管道?Apr 12, 2025 am 09:34 AM介绍 2022年,Chatgpt的推出彻底改变了技术和非技术行业,从而使个人和组织具有生成性AI的能力。在2023年,努力集中在利用大语言模式
 如何使用Star模式优化数据仓库?Apr 12, 2025 am 09:33 AM
如何使用Star模式优化数据仓库?Apr 12, 2025 am 09:33 AMStar模式是用于数据仓库和商业智能的高效数据库设计。它将数据组织到链接到周围尺寸表的中心事实表中。这种类似恒星的结构简化了复杂Q
 代理抹布系统如何改变技术?Apr 12, 2025 am 09:21 AM
代理抹布系统如何改变技术?Apr 12, 2025 am 09:21 AM介绍 人工智能进入了一个新时代。模型将基于预定义的规则输出信息的日子已经一去不复返了。当今AI中的尖端方法围绕抹布(检索-Aigmente)
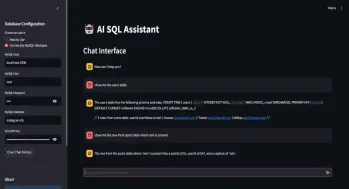 SQL自动生成查询助手Apr 12, 2025 am 09:13 AM
SQL自动生成查询助手Apr 12, 2025 am 09:13 AM您是否希望您可以简单地与数据库交谈,用简单的语言提出问题,并在不编写复杂的SQL查询或通过电子表格进行分类的情况下获得即时答案?使用Langchain的SQL工具包,Groq A
 阅读AI索引2025:AI是您的朋友,敌人还是副驾驶?Apr 11, 2025 pm 12:13 PM
阅读AI索引2025:AI是您的朋友,敌人还是副驾驶?Apr 11, 2025 pm 12:13 PM斯坦福大学以人为本人工智能研究所发布的《2025年人工智能指数报告》对正在进行的人工智能革命进行了很好的概述。让我们用四个简单的概念来解读它:认知(了解正在发生的事情)、欣赏(看到好处)、接纳(面对挑战)和责任(弄清我们的责任)。 认知:人工智能无处不在,并且发展迅速 我们需要敏锐地意识到人工智能发展和传播的速度有多快。人工智能系统正在不断改进,在数学和复杂思维测试中取得了优异的成绩,而就在一年前,它们还在这些测试中惨败。想象一下,人工智能解决复杂的编码问题或研究生水平的科学问题——自2023年
 开始使用Meta Llama 3.2 -Analytics VidhyaApr 11, 2025 pm 12:04 PM
开始使用Meta Llama 3.2 -Analytics VidhyaApr 11, 2025 pm 12:04 PMMeta的Llama 3.2:多模式和移动AI的飞跃 Meta最近公布了Llama 3.2,这是AI的重大进步,具有强大的视觉功能和针对移动设备优化的轻量级文本模型。 以成功为基础


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

Atom编辑器mac版下载
最流行的的开源编辑器

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

