
新标题:实时渲染进化!基于射线的三维重建创新方法

- 王林转载
- 2023-12-14 20:30:551096浏览
 图片
图片
论文链接:https://arxiv.org/pdf/2310.19629
代码链接:https://github.com/vLAR-group/RayDF
主页:需要进行改写的内容是:https://vlar-group.github.io/RayDF.html
重新撰写的内容: 实施方法:

RayDF的整体流程和组成部分如下所示(见图1)
一、Introduction
在机器视觉和机器人领域的许多前沿应用中,学习准确且高效的三维形状表达是非常重要的。然而,现有的基于三维坐标的隐式表达在表示三维形状或是渲染二维图像时,需要耗费昂贵的计算成本;相比之下,基于射线的方法能够高效地推断出三维形状。然而,已有的基于射线的方法没有考虑到多视角下的几何一致性,导致在未知视角下难以恢复出准确的几何形状
针对这些问题,本论文提出一个全新的维护了多视角几何一致性的基于射线的隐式表达方法RayDF。该方法基于简单的射线-表面距离场(ray-surface distance field),通过引入全新的双射线可见性分类器(dual-ray visibility classifier)和多视角一致性优化模块(multi-view consistency optimization module),学习得到满足多视角几何一致的射线-表面距离。实验结果表明,改方法在三个数据集上实现了优越的三维表面重建性能,并达到了比基于坐标的方法快1000倍的渲染速度(见Table 1)。

以下是主要的贡献:
- 采用射线-表面距离场来表示三维形状,这个表达比现有的基于坐标的表达更高效。
- 设计了全新的双射线可见性分类器,通过学习任意一对射线的空间关系,使得所学的射线-表面距离场能够在多视角下保持几何一致性。
- 在多个数据集上证明了该方法在三维形状重建上的准确性和高效性。
二、Method
2.1 Overview
如图1所示,RayDF包含两个网络及一个优化模块。对于主网络ray-surface distance network,只需输入一条射线,即可得到射线起点到射线打到的几何表面点之间的距离值。其中,如图2所示,RayDF使用一个包围三维场景的球对输入的射线进行参数化,将参数化得到的四维球坐标(入射点和出射点)作为网络输入。对于辅助网络dual-ray visibility classifier,输入一对射线和一个几何表面点,预测两条射线之间的相互可见性。这个辅助网络在训练好之后,将在后续multi-view consistency optimization module中起到关键作用。
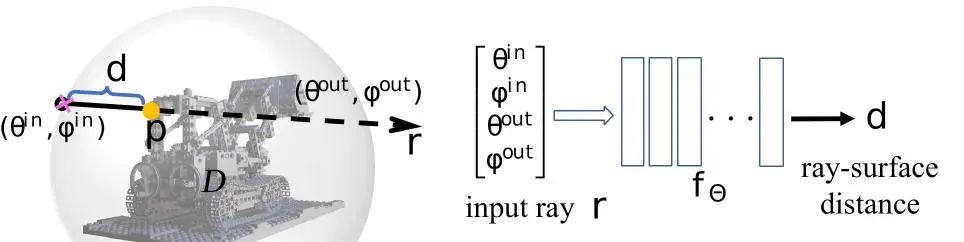
图 2 射线-表面距离场的射线参数化及网络结构
2.2 Dual-ray Visibility Classifier
该方法中的辅助网络是一个预测输入的两条射线是否能同时看到一个表面点的二元分类器。如图3所示,将输入的两条射线所得特征取平均值,以确保预测的结果不受两条射线的顺序所影响。同时,将表面点进行单独编码得到的特征拼接在射线特征之后,以增强射线特征,从而提升分类器的准确性。
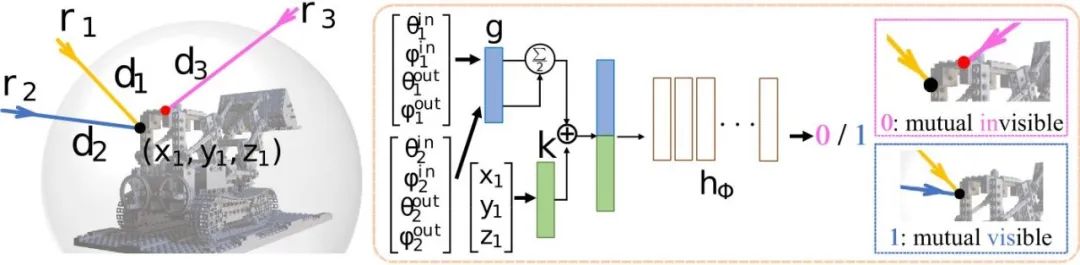
双射线可见性分类器的框架结构如图3所示
2.3 Multi-view Consistency Optimization
以设计的主网络ray-surface distance network和辅助网络dual-ray visibility classifier为铺垫,引入多视角一致性优化这一关键模块,对两个网络进行two-stage训练。
(1) 首先为辅助网络dual-ray visibility classifier构造用于训练的射线对。对于一张图片中的一条射线(对应图片中的一个像素),通过其ray-surface distance可知对应的空间表面点,将其投影到训练集中的剩余视角下,即得到另一个射线;而该射线有其对应的ray- surface distance,文章设置阈值10毫米来判断两条射线是否相互可见。
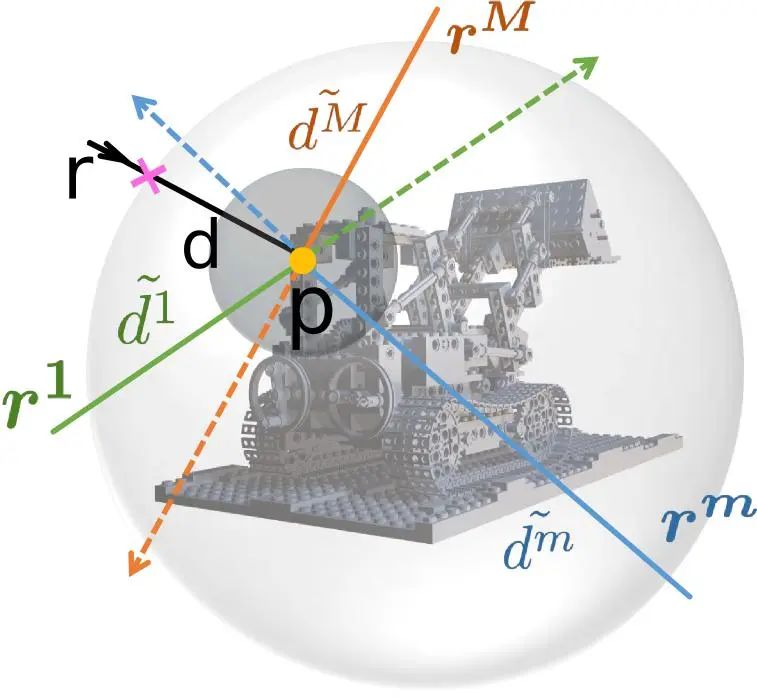
(2) 第二阶段是训练主网络ray-surface distance network使其预测的距离场满足多视角一致性。如图4所示,对于一条主射线及其表面点,以该表面点为球心均匀采样,得到若干条multi-view ray。将主射线与这些multi-view ray一一配对,通过训练好的dual-ray visibility classifier即可得到其相互可见性。再通过ray-surface distance network预测这些射线的ray-surface distance;若主射线与某一条采样射线是相互可见的,那么两条射线的ray-surface distances计算得到的表面点应是同一个点;依此设计了对应的损失函数,并对主网络进行训练,最终可以使ray-surface distance field满足多视角一致性。
2.4 Surface Normal Derivation and Outlier Points Removal
由于在场景表面边缘处的深度值往往存在突变(存在不连续性),而神经网络又是连续函数,上述ray-surface distance field在表面边缘处容易预测出不够准确的距离值,从而导致边缘处的几何表面存在噪声。好在,设计的ray-surface distance field有一个很好的特性,如图5所示,每个估计的三维表面点的法向量都可以通过网络的自动微分以闭合形式轻松求出。因此,可以在网络推理阶段计算表面点的法向量欧氏距离,若该距离值大于阈值,则该表面点被视作离群点并剔除,从而得到干净的三维重建表面。
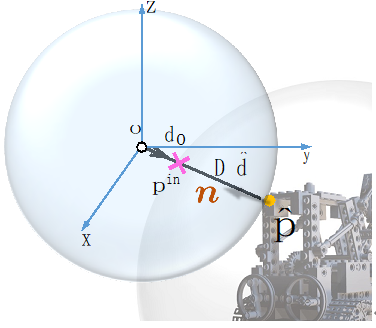
图 5 Surface normal计算
三、Experiments
为了验证所提出方法的有效性,我们在三个数据集上进行了实验。这三个数据集分别是object-level的合成数据集Blender [1]、scene-level合成数据集DM-SR [2]以及scene-level真实数据集ScanNet [3]。我们选择了七个baselines进行性能对比。其中,OF [4]/DeepSDF [5]/NDF [6]/NeuS [7]是基于坐标的level-set方法,DS-NeRF [8]是有depth监督的NeRF-based方法,LFN [9]和PRIF [10]是基于射线的两个baselines
由于RayDF方法的易于直接增加一个radiance分支来学习纹理,因此可以与支持预测radiance field的基准模型进行比较。因此,本论文的对比实验分为两组,第一组(Group 1)仅预测距离(几何),第二组(Group 2)同时预测距离和辐射度(几何和纹理)
3.1 Evaluation on Blender Dataset
从Table 2和图6可以看出,在Group 1和2中,RayDF在表面重建上取得了更优的结果,尤其是在最重要的 ADE 指标上明显优于基于坐标和射线的baselines。同时在radiance field rendering上,RayDF也取得了与DS-NeRF相当的性能,并优于LFN和PRIF。
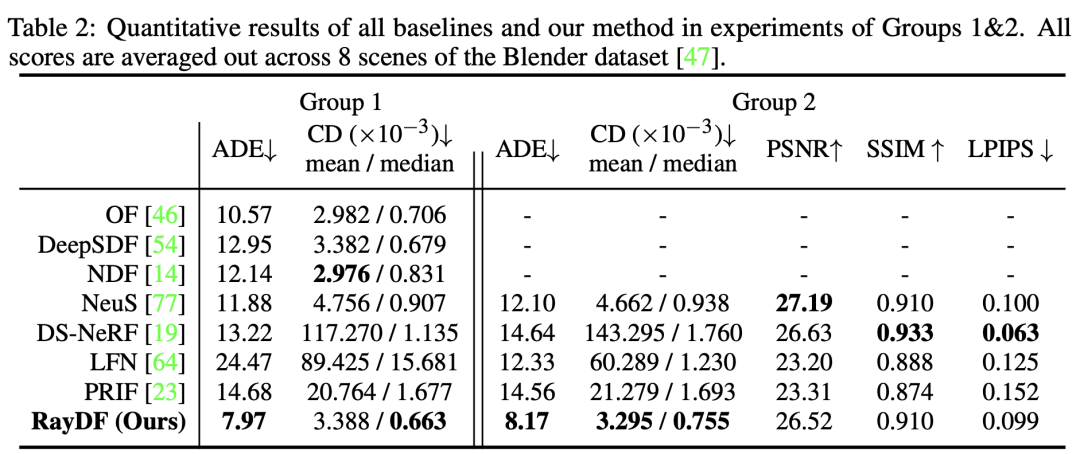
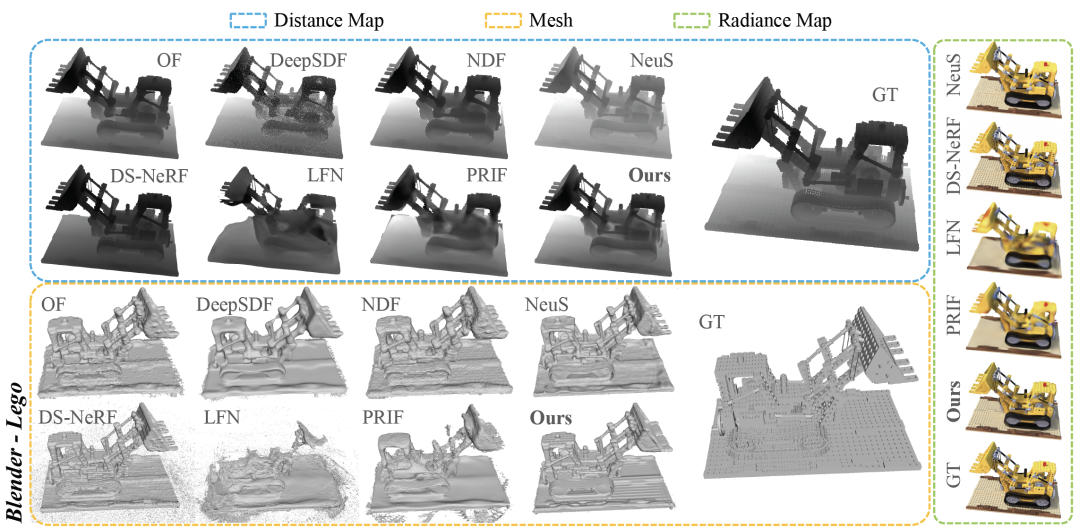
图 6 Blender数据集可视化对比
3.2 Evaluation on DM-SR Dataset
从Table 3可以看出,在最关键的 ADE 指标上,RayDF超越了所有baselines。同时,在Group 2的实验中,RayDF能够在获得高质量的新视图合成的同时,保证恢复出准确的表面形状(见图7)。
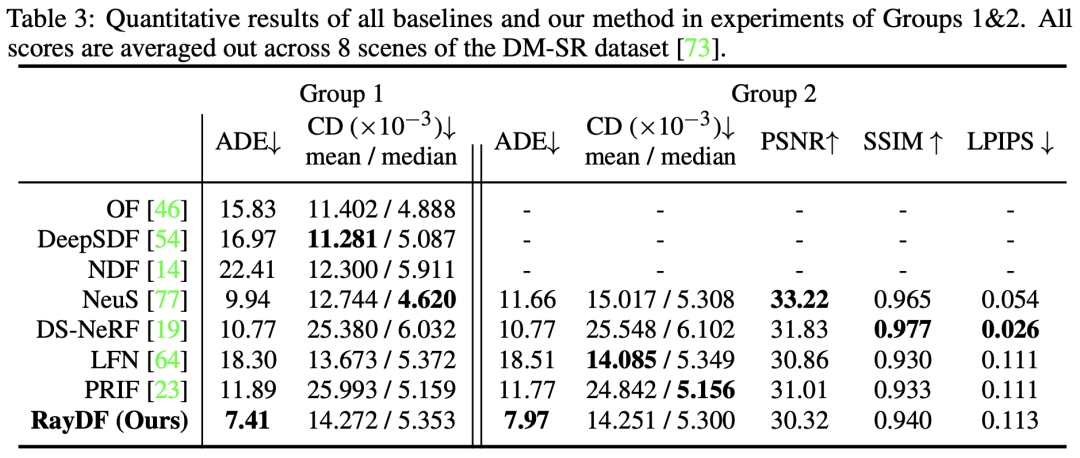
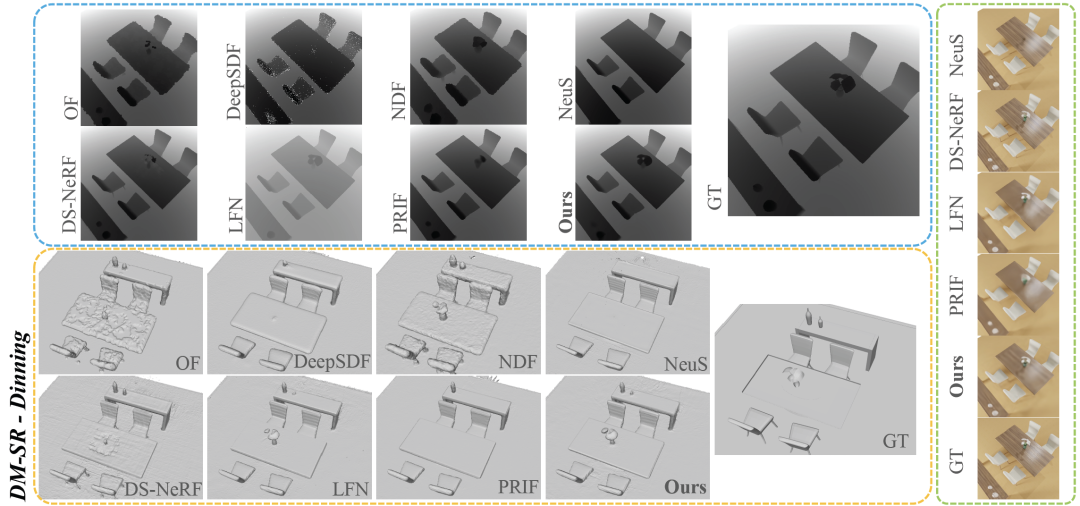
图 7 DM-SR数据集可视化对比
3.3 Evaluation on ScanNet Dataset
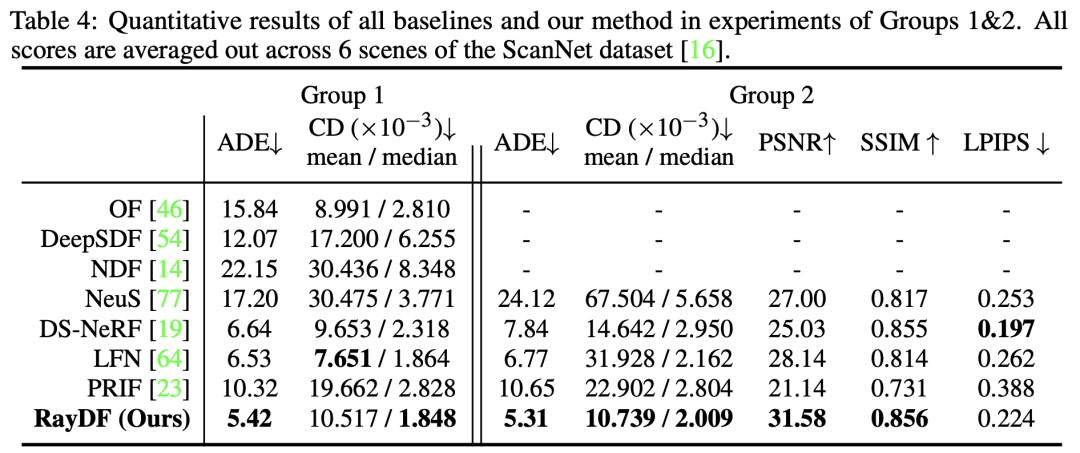
表4比较了RayDF和baselines在具有挑战性的真实世界场景中的性能。在第一组和第二组中,RayDF在几乎所有评估指标上都明显优于baselines,展现出在恢复复杂的真实世界三维场景方面的明显优势

以下是图8 ScanNet数据集可视化对比的重写内容: 在图8中,我们展示了ScanNet数据集的可视化对比结果
3.4 Ablation Study
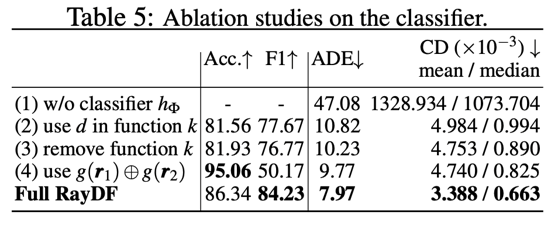
在Blender数据集上进行了消融实验,论文中的Table 5展示了对于关键的双光线可见性分类器的消融实验结果
- 如Table 5 (1)所示,如果没有dual-ray visibility classifier的帮助,ray-surface distance field则会无法对新视角下的射线预测出合理的距离值(见图9)。
- 在classifier的输入中,选择了输入表面点坐标来作为辅助,如Table 5 (2)和(3)所示,若选择输入表面点距离值作为辅助或是不提供辅助信息,分类器会获得较低的准确率和F1分数,导致为ray-surface distance network提供的可见性信息不够准确,进而预测出错误的距离值。
- 如Table 5 (4)所示,以非对称的方式输入一对射线,所训练得到的分类器准确率较高,但F1分数较低。这表明,这种分类器的鲁棒性明显低于用对称输入射线训练的分类器。
其他的切除操作可以在论文和论文附录中查看

需要重新写的内容是: 图9展示了使用分类器和不使用分类器的可视化对比
四、Conclusion
在使用基于射线的多视角一致性框架进行研究时,论文得出了一个结论,即可以通过这种方法高效、准确地学习三维形状表示。论文中使用了简单的射线-表面距离场来表示三维形状的几何图形,并利用新颖的双射线可见性分类器进一步实现了多视角几何一致性。通过在多个数据集上的实验证明,RayDF方法具有极高的渲染效率和出色的性能。欢迎对RayDF框架进行进一步扩展。您可以在主页上查看更多的可视化结果
需要进行改写的内容是:https://vlar-group.github.io/RayDF.html

需要进行重新写作的内容是:原文链接:https://mp.weixin.qq.com/s/dsrSHKT4NfgdDPYcKOhcOA
以上是新标题:实时渲染进化!基于射线的三维重建创新方法的详细内容。更多信息请关注PHP中文网其他相关文章!