



为了应对多模态大语言模型中视觉信息提取不充分的问题,哈尔滨工业大学(深圳)的研究人员提出了双层知识增强的多模态大语言模型-九天(JiuTian-LION)。

需要重新写的内容是:论文链接:https://arxiv.org/abs/2311.11860
GitHub: https://github.com/rshaojimmy/JiuTian
项目主页: https://rshaojimmy.github.io/Projects/JiuTian-LION
与现有的工作相比,九天首次分析了图像级理解任务和区域级定位任务之间的内部冲突,提出了分段指令微调策略和混合适配器来实现两种任务的互相提升。
通过注入细粒度空间感知和高层语义视觉知识,九天实现了在包括图像描述、视觉问题、和视觉定位等17个视觉语言任务上显着的性能提升( 比如Visual Spatial Reasoning 上高达5%的性能提升),在其中13个评测任务上达到了国际领先水平,性能对比如图1所示。

图1:对比其他MLLMs,九天在大部分任务上都取得了最优的性能。
九天JiuTian-LION
通过赋予大型语言模型(LLMs)多模态感知能力,一些工作开始生成多模态大语言模型(MLLMs),并在许多视觉语言任务上取得了突破性进展。然而,现有的MLLMs主要采用图文对预训练得到的视觉编码器,如CLIP-ViT
这些视觉编码器的主要任务是学习图像层面的粗粒度图像文本模态对齐,但是它们缺乏全面的视觉感知和信息抽取能力,无法进行细粒度的视觉理解
在很大程度上,这种视觉信息提取不足和理解程度不够的问题会导致MLLMs存在视觉定位偏差、空间推理不足和物体幻觉等多个缺陷,如图2所示

请参考图2:九天(JiuTian-LION)是一种采用双层视觉知识增强的多模态大语言模型
九天相较于现有的多模态大语言模型(MLLMs),通过注入细粒度空间感知视觉知识和高层语义视觉证据,有效地提升了MLLMs的视觉理解能力,生成更准确的文本回应,减少了MLLMs的幻觉现象
双层视觉知识增强的多模态大语言模型-九天(JiuTian-LION)
为了解决MLLMs在视觉信息提取和理解方面存在的不足,研究人员提出了一种双层视觉知识增强的MLLMs方法,被称为九天(JiuTian-LION)。具体的方法框架如图3所示
该方法主要从两方面增强MLLMs,渐进式融合细粒度空间感知视觉知识(Progressive Incorporation of Fine-grained Spatial-aware Visual knowledge)和软提示下的高层语义视觉证据(Soft Prompting of High-level Semantic Visual Evidence)。
具体来说,研究人员提出了一种分段指令微调策略,以解决图像级理解任务和区域级定位任务之间的内部冲突。他们逐步将细粒度的空间感知知识注入到MLLMs中。同时,他们将图像标签作为高层语义视觉证据加入MLLMs,并使用软提示方法来减轻不正确标签可能带来的负面影响
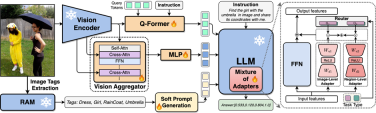
九天(JiuTian-LION)模型框架图如下所示:
该工作通过分段式训练策略先分别基于Q-Former 和 Vision Aggregator – MLP 两个分支学习图像级理解和区域级定位任务,然后在最后训练阶段利用具有路由机制的混合适配器来动态融合不同分支的知识提升模型在两种任务的表现。
该工作还通过RAM提取图像标签作为高层语义视觉证据,然后提出软提示方法来提高高层语义注入的效果
渐进式融合细粒度空间感知视觉知识
当直接将图像级理解任务(包括图像描述和视觉问答)与区域级定位任务(包括指示表达理解,指示表达生成等)进行单阶段混合训练时,MLLMs 会遭遇两种任务之间存在的内部冲突,从而不能在所有任务上取得较好的综合性能。
研究人员认为这种内部冲突主要由两个问题引起。第一个问题是缺少区域级的模态对齐预训练,当前具有区域级定位能力的 MLLMs 大多先使用大量相关数据进行预训练,不然很难在有限地训练资源下让基于图像级模态对齐的视觉特征适应区域级任务。
另一个问题是图像级理解任务和区域级定位任务之间的输入输出模式差异,后者需要模型额外理解关于物体坐标的特定短句(以 的形式)。为了解决以上问题,研究人员提出了分段式指令微调策略,以及具有路由机制的混合适配器。
的形式)。为了解决以上问题,研究人员提出了分段式指令微调策略,以及具有路由机制的混合适配器。
如图4所示,研究人员将单阶段指令微调过程拆分为三阶段:
使用ViT、Q-Former和图像级适配器学习全局视觉知识的图像级理解任务;使用Vision Aggregator、MLP和区域级适配器学习细粒度空间感知视觉知识的区域级定位任务;提出了具有路由机制的混合适配器,动态融合不同分支中学习到的不同粒度的视觉知识。表3显示了分段式指令微调策略相对于单阶段训练的性能优势

图4:分段式指令微调策略

对于注入软提示下的高层语义视觉证据,需要进行重写处理
研究人员提出使用图像标签作为高层语义视觉证据的有效补充,以进一步增强MLLMs的全局视觉感知理解能力
具体来说,首先通过 RAM 提取图像的标签,然后利用特定的指令模版“According to
配合模版中特定短语“use or partially use”,软提示向量可以指导模型减轻不正确标签带来的潜在负面影响。
实验结果
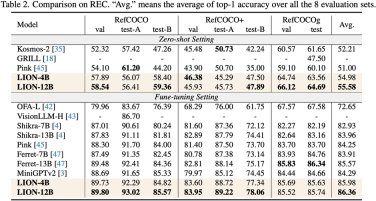
研究人员在包括图像描述(image captioning)、视觉问答(VQA)、和指示表达理解(REC)等17个任务基准集上进行了评测。
实验结果表明,九天在13个评测集上达到了国际领先水平。特别的,相比较 InstructBLIP 和 Shikra,九天分别在图像级理解任务和区域级定位任务上取得了全面且一致的性能提升,在 Visual Spatial Reasoning (VSR) 任务上可达到最高5%的提升幅度。

从图5可以看出,在不同的视觉语言多模态任务中,九天和其他MLLMs的能力存在差异,表明九天在细粒度视觉理解和视觉空间推理能力方面表现更优秀,并且能够输出具有更少幻觉的文本回应

重写的内容是:第五张图展示了对九天大模型、InstructBLIP和Shikra的能力差异进行的定性分析
图6通过样本分析,表明了九天模型在图像级和区域级视觉语言任务上都具有优秀的理解和识别能力。

第六张图:通过更多例子的分析,从图像和区域级视觉理解的角度展示了九天大模型的能力
总结
(1)该工作提出了一个新的多模态大语言模型-九天:通过双层视觉知识增强的多模态大语言模型。
(2)该工作在包括图像描述、视觉问答和指示表达理解等17个视觉语言任务基准集上进行评测,其中13个评测集达到了当前最好的性能。
(3)这项工作提出了一种分段式指令微调策略,以解决图像级理解和区域级定位任务之间的内部冲突,并实现了两种任务之间的相互提升
(4)该工作成功将图像级理解和区域级定位任务进行整合,多层次全面理解视觉场景,未来可以将这种全面的视觉理解能力应用到具身智能场景,帮助机器人更好、更全面地识别和理解当前环境,做出有效决策。
以上是横扫13个视觉语言任务!哈工深发布多模态大模型「九天」,性能直升5%的详细内容。更多信息请关注PHP中文网其他相关文章!

 ai合并图层的快捷键是什么Jan 07, 2021 am 10:59 AM
ai合并图层的快捷键是什么Jan 07, 2021 am 10:59 AMai合并图层的快捷键是“Ctrl+Shift+E”,它的作用是把目前所有处在显示状态的图层合并,在隐藏状态的图层则不作变动。也可以选中要合并的图层,在菜单栏中依次点击“窗口”-“路径查找器”,点击“合并”按钮。
 ai橡皮擦擦不掉东西怎么办Jan 13, 2021 am 10:23 AM
ai橡皮擦擦不掉东西怎么办Jan 13, 2021 am 10:23 AMai橡皮擦擦不掉东西是因为AI是矢量图软件,用橡皮擦不能擦位图的,其解决办法就是用蒙板工具以及钢笔勾好路径再建立蒙板即可实现擦掉东西。
 谷歌超强AI超算碾压英伟达A100!TPU v4性能提升10倍,细节首次公开Apr 07, 2023 pm 02:54 PM
谷歌超强AI超算碾压英伟达A100!TPU v4性能提升10倍,细节首次公开Apr 07, 2023 pm 02:54 PM虽然谷歌早在2020年,就在自家的数据中心上部署了当时最强的AI芯片——TPU v4。但直到今年的4月4日,谷歌才首次公布了这台AI超算的技术细节。论文地址:https://arxiv.org/abs/2304.01433相比于TPU v3,TPU v4的性能要高出2.1倍,而在整合4096个芯片之后,超算的性能更是提升了10倍。另外,谷歌还声称,自家芯片要比英伟达A100更快、更节能。与A100对打,速度快1.7倍论文中,谷歌表示,对于规模相当的系统,TPU v4可以提供比英伟达A100强1.
 ai可以转成psd格式吗Feb 22, 2023 pm 05:56 PM
ai可以转成psd格式吗Feb 22, 2023 pm 05:56 PMai可以转成psd格式。转换方法:1、打开Adobe Illustrator软件,依次点击顶部菜单栏的“文件”-“打开”,选择所需的ai文件;2、点击右侧功能面板中的“图层”,点击三杠图标,在弹出的选项中选择“释放到图层(顺序)”;3、依次点击顶部菜单栏的“文件”-“导出”-“导出为”;4、在弹出的“导出”对话框中,将“保存类型”设置为“PSD格式”,点击“导出”即可;
 GPT-4的研究路径没有前途?Yann LeCun给自回归判了死刑Apr 04, 2023 am 11:55 AM
GPT-4的研究路径没有前途?Yann LeCun给自回归判了死刑Apr 04, 2023 am 11:55 AMYann LeCun 这个观点的确有些大胆。 「从现在起 5 年内,没有哪个头脑正常的人会使用自回归模型。」最近,图灵奖得主 Yann LeCun 给一场辩论做了个特别的开场。而他口中的自回归,正是当前爆红的 GPT 家族模型所依赖的学习范式。当然,被 Yann LeCun 指出问题的不只是自回归模型。在他看来,当前整个的机器学习领域都面临巨大挑战。这场辩论的主题为「Do large language models need sensory grounding for meaning and u
 ai顶部属性栏不见了怎么办Feb 22, 2023 pm 05:27 PM
ai顶部属性栏不见了怎么办Feb 22, 2023 pm 05:27 PMai顶部属性栏不见了的解决办法:1、开启Ai新建画布,进入绘图页面;2、在Ai顶部菜单栏中点击“窗口”;3、在系统弹出的窗口菜单页面中点击“控制”,然后开启“控制”窗口即可显示出属性栏。
 ai移动不了东西了怎么办Mar 07, 2023 am 10:03 AM
ai移动不了东西了怎么办Mar 07, 2023 am 10:03 AMai移动不了东西的解决办法:1、打开ai软件,打开空白文档;2、选择矩形工具,在文档中绘制矩形;3、点击选择工具,移动文档中的矩形;4、点击图层按钮,弹出图层面板对话框,解锁图层;5、点击选择工具,移动矩形即可。
 强化学习再登Nature封面,自动驾驶安全验证新范式大幅减少测试里程Mar 31, 2023 pm 10:38 PM
强化学习再登Nature封面,自动驾驶安全验证新范式大幅减少测试里程Mar 31, 2023 pm 10:38 PM引入密集强化学习,用 AI 验证 AI。 自动驾驶汽车 (AV) 技术的快速发展,使得我们正处于交通革命的风口浪尖,其规模是自一个世纪前汽车问世以来从未见过的。自动驾驶技术具有显着提高交通安全性、机动性和可持续性的潜力,因此引起了工业界、政府机构、专业组织和学术机构的共同关注。过去 20 年里,自动驾驶汽车的发展取得了长足的进步,尤其是随着深度学习的出现更是如此。到 2015 年,开始有公司宣布他们将在 2020 之前量产 AV。不过到目前为止,并且没有 level 4 级别的 AV 可以在市场


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

