
让AI模型成为GTA五星玩家,基于视觉的可编程智能体Octopus来了

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB转载
- 2023-11-11 08:34:461525浏览
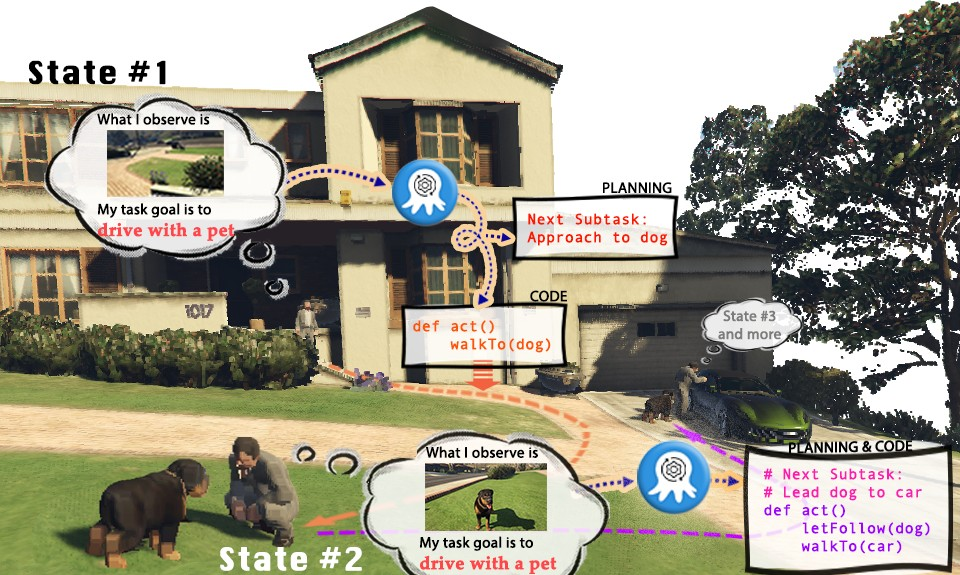
电子游戏已经成为现实世界的模拟舞台,展现出无限的可能性。以《侠盗猎车手》(GTA)为例,在游戏中,玩家可以以第一人称视角,在虚拟城市洛圣都中体验丰富多彩的生活。然而,既然人类玩家能够在洛圣都中尽情畅游并完成任务,我们是否也能有一个AI视觉模型来控制GTA中的角色,成为执行任务的“玩家”呢?GTA中的AI玩家是否能够扮演一个遵守交通规则的五星好市民,帮助警方抓捕罪犯,甚至做一个乐于助人的路人,帮助流浪汉找到适合的住所呢?
当前的视觉-语言模型(VLMs)在多模态感知和推理方面已经取得了实质性的进步,但它们通常基于较为简单的视觉问答(VQA)或者视觉标注(Caption)任务。然而,这些任务设定明显无法使VLM真正完成现实世界中的任务。因为实际任务不仅需要对视觉信息的理解,更需要模型具备规划推理和根据实时更新的环境信息做出反馈的能力。同时,生成的规划还需要能够操纵环境中的实体来真实地完成任务
尽管目前已有的语言模型(LLMs)能够根据提供的信息进行任务规划,但其无法理解视觉输入,这大大限制了语言模型在执行具体现实任务时的应用范围,特别是针对一些具身体智能的任务,基于文本输入往往过于复杂或难以详尽,这使得语言模型无法高效地从中提取信息以完成任务。目前,语言模型在程序生成方面已经进行了若干探索,但根据视觉输入生成结构化、可执行、稳健的代码的探索仍未深入
为了解决如何使大模型具身智能化的问题,创建能够准确制定计划并执行命令的自主和情境感知系统,来自新加坡南洋理工大学,清华大学等的学者提出了 Octopus。Octopus 是一种基于视觉的可编程智能体,它的目的是通过视觉输入学习,理解真实世界,并以生成可执行代码的方式完成各种实际任务。通过在大量视觉输入和可执行代码的数据对的训练,Octopus学会了如何操控电子游戏的角色完成游戏任务,或者完成复杂的家务活动。

论文链接:https://arxiv.org/abs/2310.08588
项目网页:https://choiszt.github.io/Octopus/
开源代码链接:https://github.com/dongyh20/Octopus
需要重写的内容是:数据采集与训练 重写后的内容:数据收集和训练
为了训练能够完成具身智能化任务的视觉 - 语言模型,研究者们还开发了 OctoVerse,其包含两个仿真系统用于为 Octopus 的训练提供训练数据以及测试环境。这两个仿真环境为 VLM 的具身智能化提供了可用 的训练以及测试场景,对模型的推理和任务规划能力都提出了更高的要求。具体如下:
1.OctoGibson:基于斯坦福大学开发的 OmniGibson 进行开发,一共包括了 476 个符合现实生活的家 务活动。整个仿真环境中包括 16 种不同类别的家庭场景,涵盖 155 个实际的家庭环境实例。模型可 以操作其中存在的大量可交互物体来完成最终的任务。
2.OctoGTA:基于《侠盗猎车手》(GTA)游戏进行开发,一共构建了 20 个任务并将其泛化到五个不 同的场景当中。通过预先设定好的程序将玩家设定在固定的位置,提供完成任务必须的物品和 NPC,以保证任务能够顺利进行。
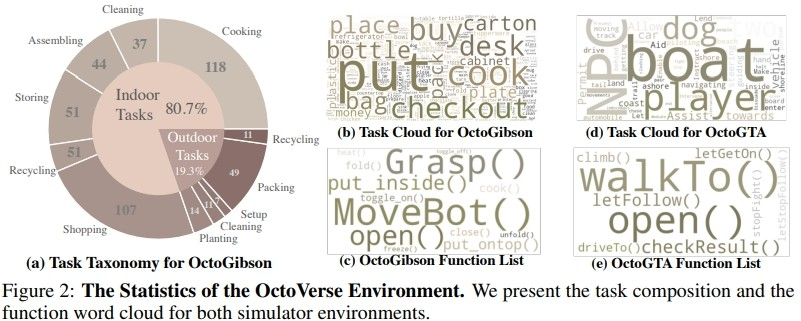
下图展示了 OctoGibson 的任务分类以及 OctoGibson 和 OctoGTA 的一些统计结果。
为了在两个构建的仿真环境中高效收集训练数据,研究人员建立了一个完整的数据收集系统。通过引入GPT-4作为任务执行者,研究人员利用预先实现的函数将从仿真环境中获取的视觉输入转化为文本信息,并提供给GPT-4。在GPT-4返回当前一步的任务规划和可执行代码后,再在仿真环境中执行代码,并判断当前一步的任务是否完成。如果成功,继续收集下一步的视觉输入;如果失败,则返回到上一步的起始位置,重新收集数据
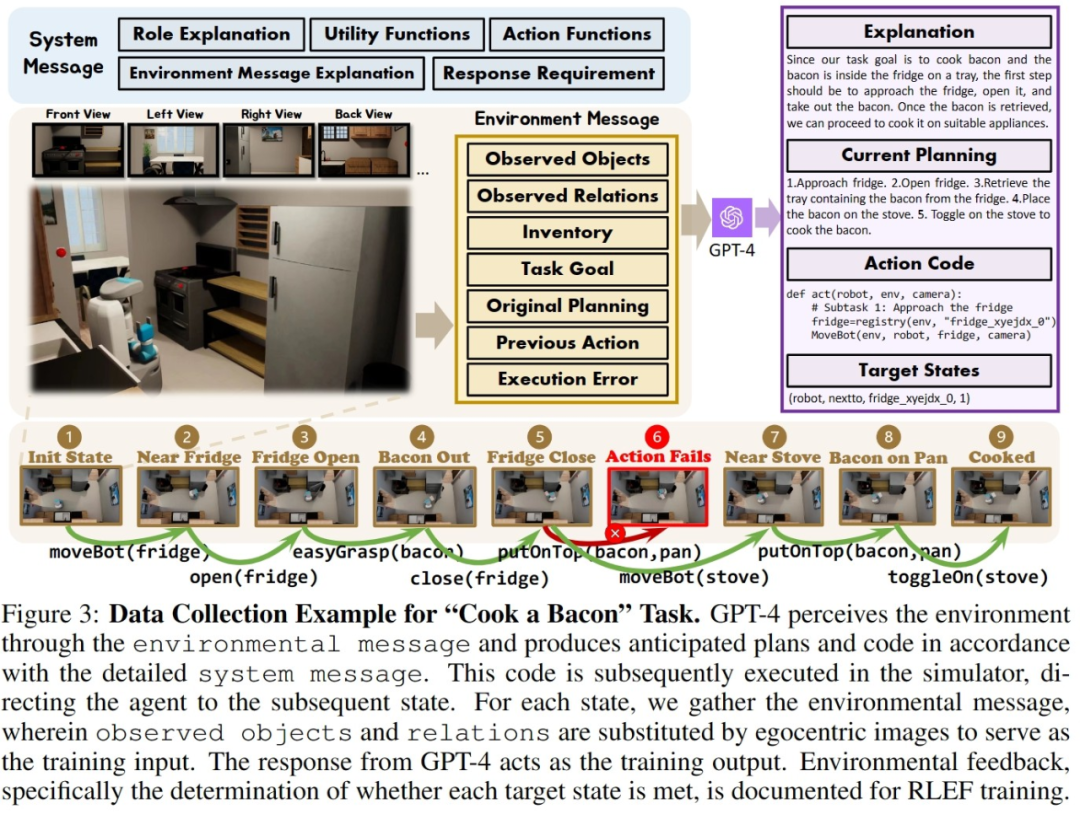
上图以 OctoGibson 环境当中的 Cook a Bacon 任务为例,展示了收集数据的完整流程。需要指出的是,在收集数据的过程中,研究者不仅记录了任务执行过程中的视觉信息,GPT-4 返回的可执行代码等,还记录了每一个子任务的成功情况,这些将作为后续引入强化学习来构建更高效的 VLM 的基础。GPT-4 的功能虽然强大,但并非无懈可击。错误可以以多种方式显现,包括语法错误和模拟器中的物理挑战。例如,如图 3 所示,在状态 #5 和 #6 之间,由于 agent 拿着的培根与平底锅之间的距离过远,导致 “把培根放到平底锅” 的行动失败。此类挫折会将任务重置到之前的状态。如果一个任务在 10 步之后仍未完成,则被认定为不成功,我们会因预算问题而终止这个任务,而这个任务的所有子任务的数据对都会认为执行失败。
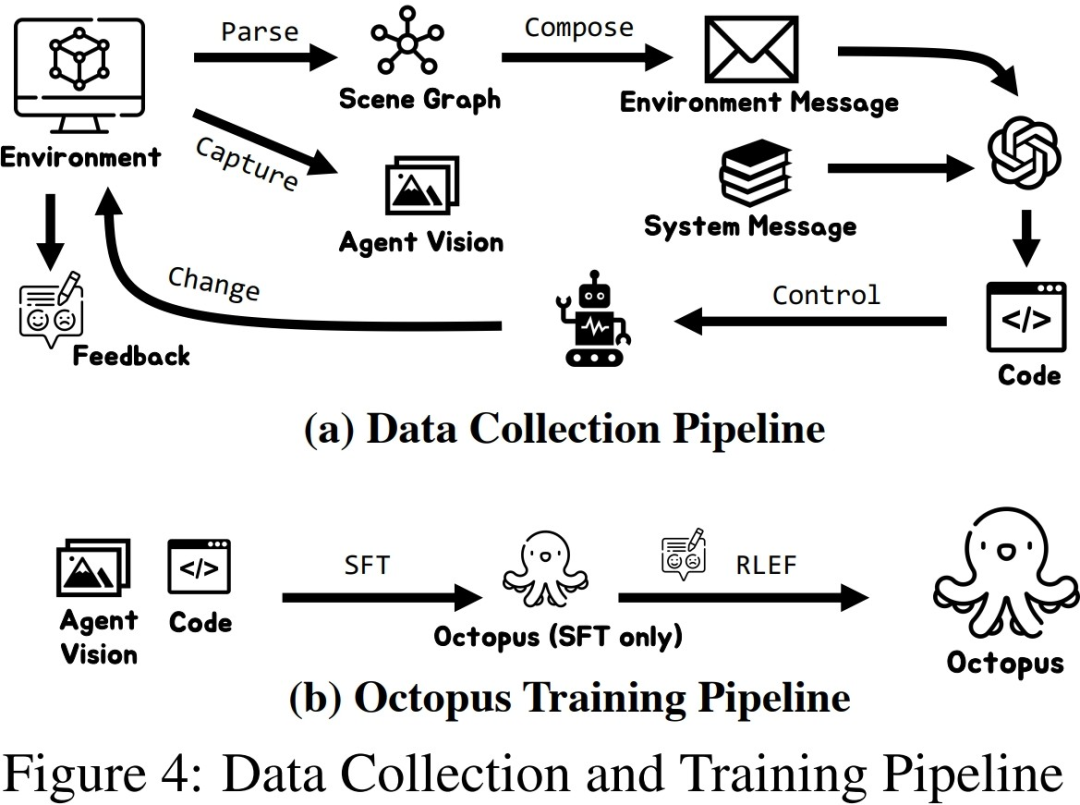
研究者在收集了一定规模的训练数据后,利用这些数据训练出了一个具备智能化的视觉-语言模型Octopus。下图展示了完整的数据采集和训练过程。在第一阶段,通过使用采集的数据进行监督式微调,研究者构建出了一个能够接收视觉信息作为输入,并按照固定格式进行输出的VLM模型。在这个阶段,模型能够将视觉输入信息映射为任务计划和可执行代码。在第二阶段,研究者引入了RLEF
利用环境反馈的强化学习,通过先前采集的子任务的成功情况作为奖励信号,进一步提升 VLM 的任务规划能力,以提高整体任务的成功率
实验结果
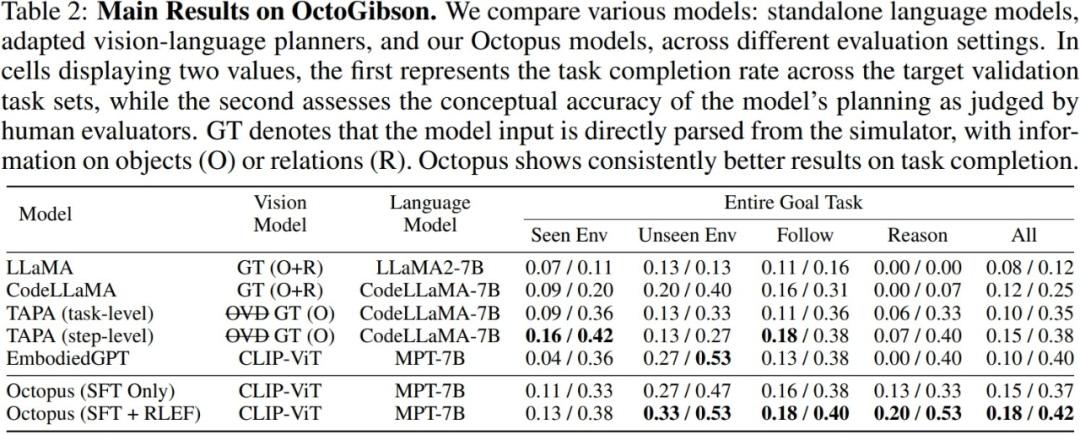
研究者在构建的 OctoGibson 环境中,对于当前主流的 VLM 和 LLM 进行了测试,下表展示了主要实验结 果。对于不同的测试模型,Vision Model 列举了不同模型所使用的视觉模型,对于 LLM 来说,研究者将视觉信息处理为文本作为 LLM 的输入。其中 O 代表提供了场景中可交互物体的信息,R 代表提供了场景中 物体相对关系的信息,GT 代表使用真实准确的信息,而不引入额外的视觉模型来进行检测。
对于所有的测试任务,研究者报告了完整的测试集成功率,并进一步将其分为四个类别,分别记录在训 练集中存在的场景中完成新任务,在训练集中不存在的场景中完成新任务的泛化能力,以及对于简单的 跟随任务以及复杂的推理任务的泛化能力。对于每一种类别的统计,研究者报告了两种评价指标,其中 第一个为任务的完成率,以衡量模型完成具身智能任务的成功率;第二个为任务规划准确率,用于体现 模型进行任务规划的能力。
此外,研究人员还展示了对于 OctoGibson 仿真环境中采集的视觉数据,不同模型的响应实例。下图展示了使用 TAPA+CodeLLaMA、Octopus以及GPT-4V三种模型在OctoGibson中生成视觉输入后的回应。可以看出,相较于只进行了监督式微调的Octopus模型和TAPA+CodeLLaMA,经过RLEF训练的Octopus模型的任务规划更加合理。即使对于较为模糊的任务指令“寻找一个大瓶”,也能提供更加完善的计划。这些表现进一步说明了RLEF训练策略对于提升模型的任务规划能力和推理能力的有效性

总体来说,现有的模型在仿真环境中表现出的实际任务完成度和任务规划能力依旧有很大的提升空间。研究者们总结了一些较为关键的发现:
1.CodeLLaMA 能够提升模型的代码生成能力,但不能提升任务规划能力。
研究者指出,实验结果表明,CodeLLaMA能够显著提高模型的代码生成能力。相比传统的LLM,使用CodeLLaMA能够获得更好、更高可执行性的代码。然而,尽管一些模型使用CodeLLaMA生成代码,但整体任务的成功率仍然受到任务规划能力的限制。任务规划能力较弱的模型,尽管生成的代码可执行性较高,但最终任务成功率仍然较低。反观Octopus,尽管没有使用CodeLLaMA,代码可执行性略有下降,但由于其强大的任务规划能力,整体任务成功率仍然优于其他模型
当面对大量的文本信息输入时,LLM 的处理变得相对困难
在实际的测试过程中,研究者通过对比 TAPA 和 CodeLLaMA 的实验结果得出了一个结论,即语言模型很难较好地处理长文本输入。研究者们遵从 TAPA 的方法,使用真实的物体信息来进行任务规划,而 CodeLLaMA 使用物体和物体之间的相对位置关系,以期提供较为完整的信息。但在实验过程中,研究者发现由于环境当中存在大量的冗余信息,因此当环境较为复杂时,文本输入显着增加,LLM 难以从大量的冗余信息当中提取有价值的线索,从而降低了任务的成功率。这也体现了 LLM 的局限性,即如果使用 文本信息来表示复杂的场景,将会产生大量冗余且无价值的输入信息。
3.Octopus 表现出了较好的任务泛化能力。
Octopus具有很强的任务泛化能力,通过实验结果可以得知。在未出现在训练集中的新场景中,Octopus完成任务的成功率和任务规划的成功率均优于现有模型。这也展现了视觉-语言模型在同一类别的任务中具有内在优势,其泛化性能优于传统的LLM
4.RLEF 能够增强模型的任务规划能力。
研究人员在实验结果中提供了两个模型的性能比较:一个是经过第一阶段监督式微调的模型,另一个是经过RLEF训练的模型。从结果中可以看出,经过RLEF训练后,模型在需要强大的推理和任务规划能力的任务上,整体成功率和规划能力都有显着提高。相比已有的VLM训练策略,RLEF更加高效。示例图表明,经过RLEF训练的模型在任务规划方面有所提高。在面对复杂任务时,模型能够学会在环境中探索;此外,模型在任务规划方面更加符合仿真环境的实际要求(例如,模型需要先移动到要交互的物体,才能开始交互),从而降低任务规划失败的风险
讨论
需要重写的内容是:融化试验
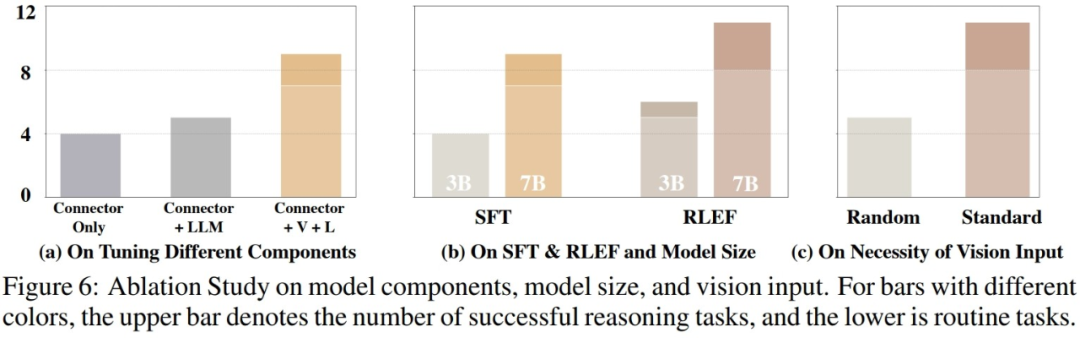
在对模型实际能力进行评估后,研究人员进一步探究了影响模型性能的可能因素。如下图所示,研究人员从三个方面进行了实验
需要重写的内容是:1. 训练参数的比重
研究者进行了对比实验,比较了仅训练视觉模型和语言模型的连接层、训练连接层和语言模型,以及完整训练模型的性能。结果显示,随着训练参数的增加,模型的性能逐渐提升。这表明,训练参数的数量对于模型在一些固定场景中能否完成任务至关重要
2. 模型的大小
研究人员对比了较小的3B参数模型和基线7B模型在两个训练阶段的性能差异。比较结果表明,当模型整体参数量较大时,模型的性能也会明显提升。未来在VLM领域的研究中,如何选择适当的模型训练参数,以确保模型具备完成对应任务的能力,同时也保证模型的轻量化和快速推理速度,将是一个非常关键的问题
需要重写的内容是:3. 视觉输入的连续性。 重写后的内容:3. 视觉输入的连贯性
为了研究不同的视觉输入对实际VLM性能的影响,研究人员进行了实验。在测试过程中,模型在仿真环境中按顺序转动,并采集第一视角图像和两张鸟瞰图,然后按顺序将这些视觉图像输入VLM。在实验中,当研究人员随机打乱视觉图像的顺序再输入VLM时,VLM的性能受到较大的损失。这一方面说明了完整且结构化的视觉信息对VLM的重要性,另一方面也反映了VLM在响应视觉输入时需要依赖视觉图像之间的内在联系,一旦这种联系被破坏,将极大地影响VLM的表现
GPT-4
此外,研究者还对GPT-4 以及GPT-4V 在仿真环境当中的性能进行了测试和统计。
需要进行改写的是:1. GPT-4
针对 GPT-4,在测试过程中研究者提供与使用其采集训练数据时完全相同的文本信息作为输入。在测试任务上,GPT-4 能够完成一半的任务,这一方面说明现有的VLM 相对于GPT-4 这样的语言模型,从性能上还有很大的提升空间;另一方面也说明,即使是GPT-4 这样性能较强的语言模型,在面对具身智能任务时, 其任务规划能力和任务执行能力依然需要更进一步的提升。
需要重新书写的内容是:2. GPT-4V
由于 GPT-4V 刚刚发布可以直接调用的 API,研究者还没来得及尝试,但是研究者们之前也手动测试了一些实例来展现 GPT-4V 的性能。通过一些示例,研究者认为 GPT-4V 对于仿真环境当中的任务具有较强的零样本泛化能力,也能够根据视觉输入生成对应的可执行的代码,但其在一些任务规划上稍逊色于在仿真环境采集的数据上微调之后的模型。
总结
研究人员指出了当前工作的一些限制:
当前的Octopus模型在处理复杂任务时表现不佳。面对复杂任务时,Octopus经常会做出错误的规划,并且严重依赖环境的反馈信息,导致难以完成整个任务
2.Octopus 模型仅在仿真环境当中进行训练,而如何将其迁移到真实世界当中将会面临一系列的问题。例如,真实环境当中模型将难以得到较为准确的物体相对位置信息,如何构建起物体对于场景 的理解将变得更加困难。
3. 目前,章鱼的视觉输入是离散的静态图片,将其能够处理连续的视频成为未来的挑战。连续的视频可以进一步提高模型完成任务的性能,但如何高效地处理和理解连续视觉输入将成为提升 VLM 性能的关键
以上是让AI模型成为GTA五星玩家,基于视觉的可编程智能体Octopus来了的详细内容。更多信息请关注PHP中文网其他相关文章!