
什么是机器学习中的正则化?

- 王林转载
- 2023-11-06 11:25:011139浏览
1. 引言
在机器学习领域中,相关模型可能会在训练过程中变得过拟合和欠拟合。为了防止这种情况的发生,我们在机器学习中使用正则化操作来适当地让模型拟合在我们的测试集上。一般来说,正则化操作通过降低过拟合和欠拟合的可能性来帮助大家获得最佳模型。
在本文中,我们将了解什么是正则化,正则化的类型。此外,我们将讨论偏差、方差、欠拟合和过拟合等相关概念。
我们不再废话,直接开始吧!
2. 偏差和方差
Bias和Variance是用来描述我们学习到的模型与真实模型之间差距的两个方面
需要被改写的是:二者的定义如下:
- Bias是用所有可能的训练数据集训练出的所有模型的输出的平均值与真实模型的输出值之间的差异。
- Variance是不同的训练数据集训练出的模型输出值之间的差异。
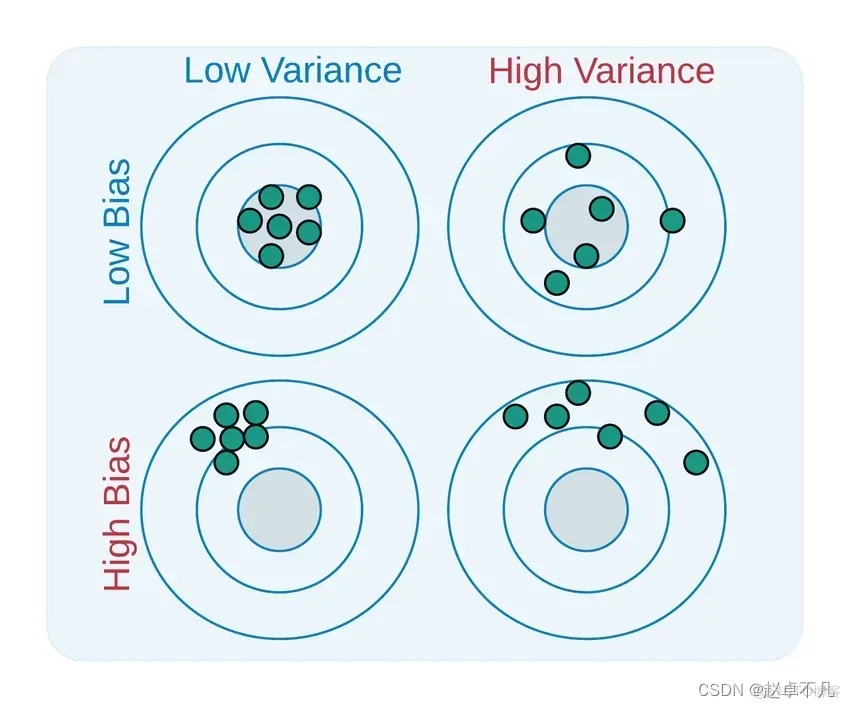
偏差降低了模型对单个数据点的敏感性,同时增加了数据的泛化性,降低了模型对孤立数据点的敏感度。由于所需的功能不太复杂,因此还可以减少训练时间。高偏差表示假定目标函数更可靠,但有时会导致模型拟合不足
方差(Variance)在机器学习中是指模型对数据集中微小变化的敏感性而产生的错误。由于数据集中存在显著变化,算法会对训练集中的噪声和异常值进行建模。这种情况通常被称为过拟合。在对新数据集进行评估时,由于模型本质上学习了每个数据点,因此无法提供准确的预测
一个相对平衡的模型将具有低偏差和低方差,而高偏差和高方差将导致欠拟合和过拟合。
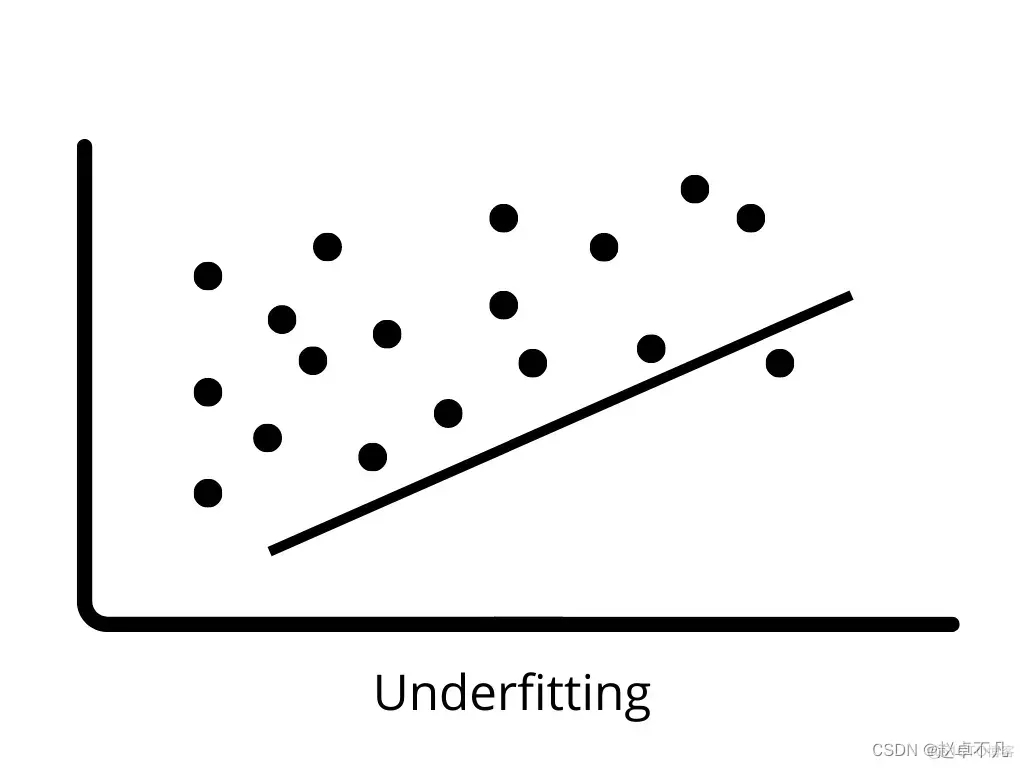
3. 欠拟合
当模型不能正确地将训练数据中的模式加以学习并推广到新数据时,就会出现欠拟合现象。欠拟合模型在训练数据上的性能不佳,会导致错误的预测结果。当出现高偏差和低方差时,就容易出现欠拟合
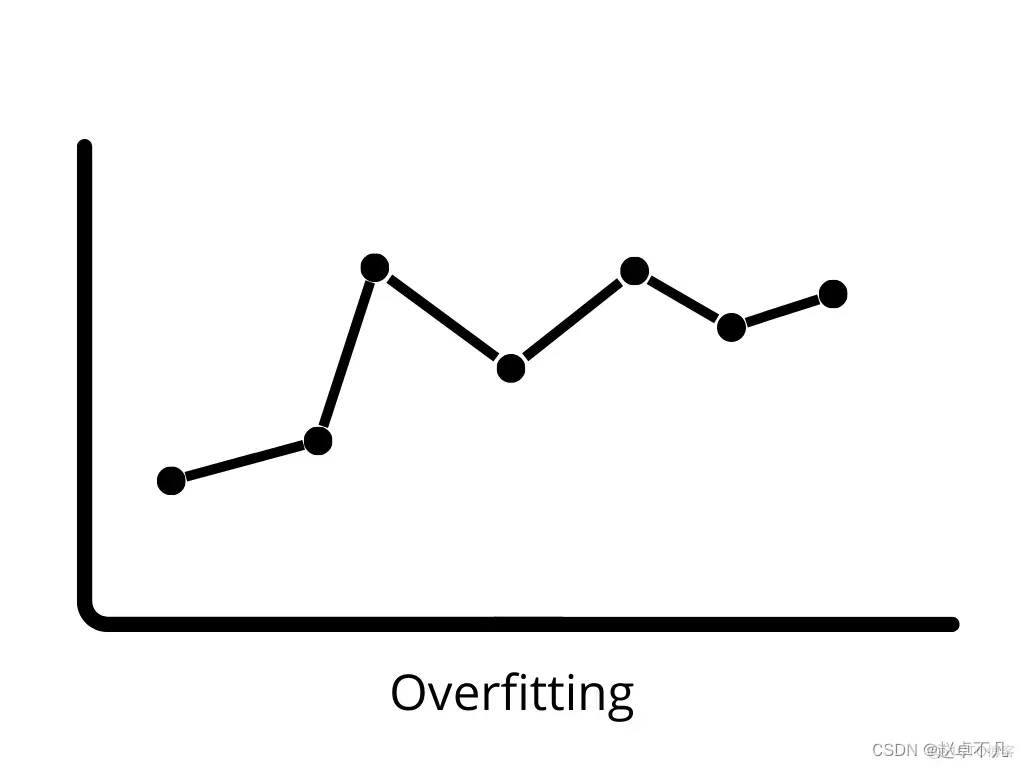
4. 过拟合
当一个模型在训练数据上表现得非常好,但在测试数据上表现不佳时,它被称为过拟合(新数据)。在这种情况下,机器学习模型因为拟合到训练数据中的噪声,这会对模型在测试数据上的表现产生负面影响。低偏差和高方差可能导致过拟合。
5. 正则化概念
术语“正则化”描述了校准机器学习模型的方法,以减少调整后的损失函数并避免过拟合或欠拟合。
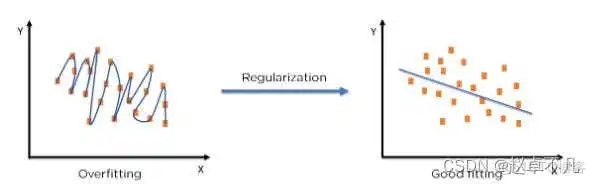
通过使用正则化技术,我们可以让机器学习模型更加准确地拟合到特定的测试集上,从而有效降低测试集中的误差
6. L1正则化
相对于领回归,L1正则化的实现方式主要是在损失函数中增加一个惩罚项,该项的惩罚值为所有系数的绝对值之和,具体如下:
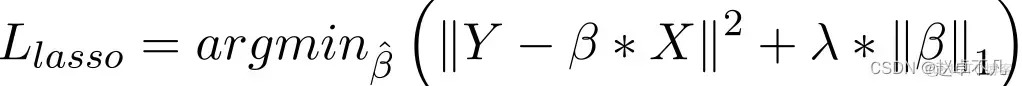
在Lasso回归模型中,以类似于岭回归的方式通过增加回归系数的绝对值这一惩罚项来实现。此外,L1正则化在提高线性回归模型的精度方面有着良好的表现。同时,由于L1正则化对所有参数的惩罚力度都一样,可以让一部分权重变为零,因此产生稀疏模型,能够去除某些特征(权重为0则等效于去除)。
7. L2正则化
L2正则化也是通过在损失函数中增加一项惩罚项来实现,惩罚项等于所有系数的平方和。如下所示:
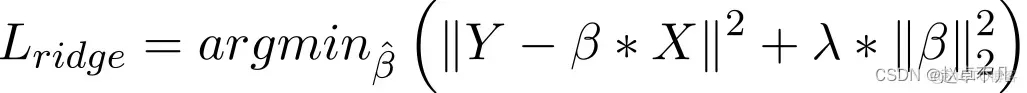
一般而言,当数据表现出多重共线性(自变量高度相关)时,它被认为是一种采用的方法。尽管多重共线性中的最小二乘估计值 (OLS) 是无偏的,但它们的巨大方差会导致观测值与实际值相差很大。L2通过在一定程度上降低了回归估计值的误差。它通常使用收缩参数来解决多重共线性问题。L2正则化减少了权重的固定比例,使权重平滑。
8. 总结
经过上述分析,对本文中相关正则化的知识进行总结如下:
L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择;
L2正则化可以防止模型过拟合,在一定程度上,L1也可以防止过拟合,提升模型的泛化能力;
L1(拉格朗日)正则假设参数的先验分布是Laplace分布,可以保证模型的稀疏性,也就是某些参数等于0;
L2(岭回归)的假设是参数的先验分布是高斯分布,这可以确保模型的稳定性,即参数的值不会过大或过小
在实际应用中,如果特征是高维稀疏的,就应该使用L1正则化;如果特征是低维密集的,就应该使用L2正则化
以上是什么是机器学习中的正则化?的详细内容。更多信息请关注PHP中文网其他相关文章!