



苹果的一项最新研究,大幅提高了扩散模型在高分辨率图像上性能。
利用这种方法,同样分辨率的图像,训练步数减少了超过七成。
在1024×1024的分辨率下,图片画质直接拉满,细节都清晰可见。

苹果把这项成果命名为MDM,DM就是扩散模型(Diffusion Model)的缩写,而第一个M则代表了套娃(Matryoshka)。
就像真的套娃一样,MDM在高分辨率过程中嵌套了低分辨率过程,而且是多层嵌套。
高低分辨率扩散过程同时进行,极大降低了传统扩散模型在高分辨率过程中的资源消耗。

对于256×256分辨率的图像,在批大小(batch size)为1024的环境下,传统扩散模型需要训练150万步,而MDM仅需39万,减少了超七成。
另外,MDM采用了端到端训练,不依赖特定数据集和预训练模型,在提速的同时依然保证了生成质量,而且使用灵活。

不仅可以画出高分辨率的图像,还能合成16×256²的视频。

有网友评论到,苹果终于把文本连接到图像中了。
那么,MDM的“套娃”技术,具体是怎么做的呢?
整体与渐进相结合
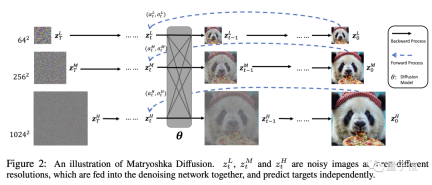
在开始训练之前,需要将数据进行预处理,高分辨率的图像会用一定算法重新采样,得到不同分辨率的版本。
然后就是利用这些不同分辨率的数据进行联合UNet建模,小UNet处理低分辨率,并嵌套进处理高分辨率的大UNet。
通过跨分辨率的连接,不同大小的UNet之间可以共用特征和参数。

MDM的训练则是一个循序渐进的过程。
虽然建模是联合进行的,但训练过程并不会一开始就针对高分辨率进行,而是从低分辨率开始逐步扩大。
这样做可以避免庞大的运算量,还可以让低分辨率UNet的预训练可以加速高分辨率训练过程。
训练过程中会逐步将更高分辨率的训练数据加入总体过程中,让模型适应渐进增长的分辨率,平滑过渡到最终的高分辨率过程。

不过从整体上看,在高分辨率过程逐步加入之后,MDM的训练依旧是端到端的联合过程。
在不同分辨率的联合训练当中,多个分辨率上的损失函数一起参与参数更新,避免了多阶段训练带来的误差累积。
每个分辨率都有对应的数据项的重建损失,不同分辨率的损失被加权合并,其中为保证生成质量,低分辨率损失权重较大。
在推理阶段,MDM采用的同样是并行与渐进相结合的策略。
此外,MDM利还采用了预训练的图像分类模型(CFG)来引导生成样本向更合理的方向优化,并为低分辨率的样本添加噪声,使其更贴近高分辨率样本的分布。
那么,MDM的效果究竟如何呢?
更少参数匹敌SOTA
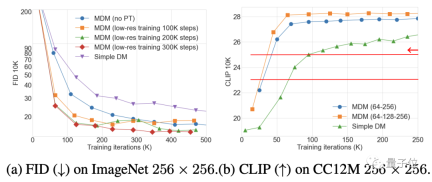
图像方面,在ImageNet和CC12M数据集上,MDM的FID(数值越低效果越好)和CLIP表现都显著优于普通扩散模型。
其中FID用于评价图像本身的质量,CLIP则说明了图像和文本指令之间的匹配程度。
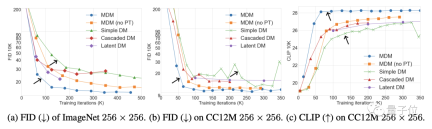
和DALL E、IMAGEN等SOTA模型相比,MDM的表现也很接近,但MDM的训练参数远少于这些模型。

不仅是优于普通扩散模型,MDM的表现也超过了其他级联扩散模型。
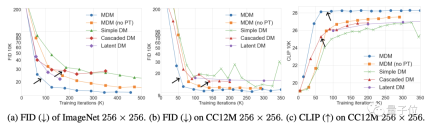
消融实验结果表明,低分辨率训练的步数越多,MDM效果增强就越明显;另一方面,嵌套层级越多,取得相同的CLIP得分需要的训练步数就越少。
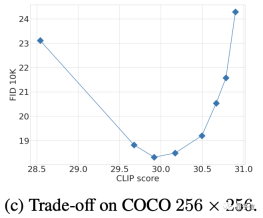
而关于CFG参数的选择,则是一个多次测试后再FID和CLIP之间权衡的结果(CLIP得分高相对于CFG强度增大)。
以上是苹果'套娃”式扩散模型,训练步数减少七成!的详细内容。更多信息请关注PHP中文网其他相关文章!

 个人黑客将是一只非常凶猛的熊May 11, 2025 am 11:09 AM
个人黑客将是一只非常凶猛的熊May 11, 2025 am 11:09 AM网络攻击正在发展。 通用网络钓鱼电子邮件的日子已经一去不复返了。 网络犯罪的未来是超个性化的,利用了容易获得的在线数据和AI来制作高度针对性的攻击。 想象一个知道您的工作的骗子
 教皇狮子座XIV揭示了AI如何影响他的名字选择May 11, 2025 am 11:07 AM
教皇狮子座XIV揭示了AI如何影响他的名字选择May 11, 2025 am 11:07 AM新当选的教皇狮子座(Leo Xiv)在对红衣主教学院的就职演讲中,讨论了他的同名人物教皇里奥XIII的影响,他的教皇(1878-1903)与汽车和汽车和汽车公司的黎明相吻合
 Fastapi -MCP初学者和专家教程-Analytics VidhyaMay 11, 2025 am 10:56 AM
Fastapi -MCP初学者和专家教程-Analytics VidhyaMay 11, 2025 am 10:56 AM本教程演示了如何使用模型上下文协议(MCP)和FastAPI将大型语言模型(LLM)与外部工具集成在一起。 我们将使用FastAPI构建一个简单的Web应用程序,并将其转换为MCP服务器,使您的L
 dia-1.6b tts:最佳文本到二元格生成模型 - 分析vidhyaMay 11, 2025 am 10:27 AM
dia-1.6b tts:最佳文本到二元格生成模型 - 分析vidhyaMay 11, 2025 am 10:27 AM探索DIA-1.6B:由两个本科生开发的开创性的文本对语音模型,零资金! 这个16亿个参数模型产生了非常现实的语音,包括诸如笑声和打喷嚏之类的非语言提示。本文指南
 AI可以使指导比以往任何时候都更有意义May 10, 2025 am 11:17 AM
AI可以使指导比以往任何时候都更有意义May 10, 2025 am 11:17 AM我完全同意。 我的成功与导师的指导密不可分。 他们的见解,尤其是关于业务管理,构成了我的信念和实践的基石。 这种经验强调了我对导师的承诺
 AI发掘了采矿业的新潜力May 10, 2025 am 11:16 AM
AI发掘了采矿业的新潜力May 10, 2025 am 11:16 AMAI 增强型矿业设备 矿业作业环境恶劣且危险重重。人工智能系统通过将人类从最危险的环境中移除并增强人类能力,帮助提高整体效率和安全性。人工智能越来越多地用于为矿业作业中使用的自动驾驶卡车、钻机和装载机提供动力。 这些 AI 驱动的车辆能够在危险环境中精确作业,从而提高安全性和生产力。一些公司已经开发出用于大型矿业作业的自动驾驶采矿车辆。 在挑战性环境中运行的设备需要持续维护。然而,维护会使关键设备离线并消耗资源。更精确的维护意味着昂贵且必要的设备的正常运行时间增加以及显着的成本节约。 AI 驱动
 为什么AI代理会触发25年来最大的工作场所革命May 10, 2025 am 11:15 AM
为什么AI代理会触发25年来最大的工作场所革命May 10, 2025 am 11:15 AMSalesforce首席执行官Marc Benioff预测了由AI代理商驱动的巨大的工作场所革命,这是Salesforce及其客户群中已经进行的转型。 他设想从传统市场转变为一个较大的市场,重点是
 随着AI采用的飙升,人力资源将摇滚我们的世界May 10, 2025 am 11:14 AM
随着AI采用的飙升,人力资源将摇滚我们的世界May 10, 2025 am 11:14 AM人力资源中AI的崛起:与机器人同事一起导航劳动力 将人工智能集成到人力资源(HR)不再是未来派的概念。它正在迅速成为新现实。 这种转变影响了人力资源专业人员和员工,DEM


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver Mac版
视觉化网页开发工具

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

SublimeText3汉化版
中文版,非常好用

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

