


PHP的XML分析函数
适合的阅读对象
本文适合于打算用XML编写程序的有经验PHP程序员。本文假设你熟悉XML的语法和优点。
如果读者希望学习更多的XML知识,在阅读本文以前应浏览以下网站:
What is XML? - 由Normal Walsh撰写XML介绍
XML FAQ -XML - 常见问题
Project Cool: XML resources - XML指南和参考
XML.com - XML入门网站
XML.org - XML的连接网站
Annotated XML specification - W3C的XML标准的解释
介绍
首先我得承认我喜欢计算机标准。如果每个人都遵从这个行业的标准,互联网将会是一个更好的媒体。使用标准化的数据交换格式才能使开放的和独立于平台的计算模式切实可行。这就是我作为XML爱好者的原因。
幸运的是,我最喜爱的脚本语言不但支持XML而且对其支持正不断加强。PHP可以让我迅速将XML文档发布到互联网上,收集XML文档的统计信息,将XML文档转换成其它格式。例如,我时常用PHP的XML处理能力来管理我用XML所写的文章和书。
本文中,我将讨论任何用PHP内建的Expat解析器来处理XML文档。通过范例,我将演示Expat的处理方法。同时,范例可以告诉你如何:
建立你自己的处理函数
将XML文档转换成你自己的PHP数据结构
介绍Expat
XML的解析器,同样称为XML处理器,可以使程序访问XML文档的结构和内容。Expat是PHP脚本语言的XML解析器。它同时也运用在其它项目中,例如Mozilla、Apache和Perl。
什么是基于事件的解析器?
XML解析器的两种基本类型:
基于树型的解析器:将XML文档转换成树型结构。这类解析器分析整篇文章,同时提供一个API来访问所产生树的每个元素。其通用的标准为DOM(文档对象模式)。
基于事件的解析器:将XML文档视为一系列的事件。当一个特殊事件发生时,解析器将调用开发者提供的函数来处理。
基于事件的解析器有一个XML文档的数据集中视图,也就是说它集中在XML文档的数据部分,而不是其结构。这些解析器从头到尾处理文档,并将类似于-元素的开始、元素的结尾、特征数据的开始等等-事件通过回调(callback)函数报告给应用程序。以下是一个"Hello-World"的XML文档范例:
greeting>
Hello World
/greeting>
基于事件的解析器将报告为三个事件:
开始元素:greeting
CDATA项的开始,值为:Hello World
结束元素:greeting
不像基于树型的解析器,基于事件的解析器不产生描述文档的结构。在CDATA项中,基于事件的解析器不会让你得到父元素greeting的信息。
然而,它提供一个更底层的访问,这就使得可以更好地利用资源和更快地访问。通过这种方式,就没有必要将整个文档放入内存;而事实上,整个文档甚至可以大于实际内存值。
Expat就是这样的一种基于事件的解析器。当然如果使用Expat,必要时它一样可以在PHP中生成完全的原生树结构。
上面Hello-World的范例包括完整的XML格式。但它是无效的,因为既没有DTD(文档类型定义)与其联系,也没有内嵌DTD。
对于Expat,这并没有区别:Expat是一个不检查有效性的解析器,因此忽略任何与文档联系的DTD。但应注意的是文档仍然需要完整的格式,否则Expat(和其他符合XML标准的解析器一样)将会随着出错信息而停止。
作为不检查有效性的解析器,Exapt的快速性和轻巧性使其十分适合互联网程序。
编译Expat
Expat可以编译进PHP3.0.6版本(或以上)中。从Apache1.3.9开始,Expat已经作为Apache的一部分。在Unix系统中,通过-with-xml选项配置PHP,你可以将其编译入PHP。
如果你将PHP编译为Apache的模块,而Expat将默认作为Apache的一部分。在Windows中,你则必须要加载XML动态连接库。
XML范例:XMLstats
了解Expat的函数的一个办法就是通过范例。我们所要讨论的范例是使用Expat来收集XML文档的统计数据。
对于文档中每个元素,以下信息都将被输出:
该元素在文档中使用的次数
该元素中字符数据的数量
元素的父元素
元素的子元素
注意:为了演示,我们利用PHP来产生一个结构来保存元素的父元素和子元素
准备
用于产生XML解析器实例的函数为xml_parser_create()。该实例将用于以后的所有函数。这个思路非常类似于PHP中MySQL函数的连接标记。在解析文档前,基于事件的解析器通常要求你注册回调函数-用于特定的事件发生时调用。Expat没有例外事件,它定义了如下七个可能事件:
对象 XML解析函数 描述
元素 xml_set_element_handler() 元素的开始和结束
字符数据 xml_set_character_data_handler() 字符数据的开始
外部实体 xml_set_external_entity_ref_handler() 外部实体出现
未解析外部实体 xml_set_unparsed_entity_decl_handler() 未解析的外部实体出现
处理指令 xml_set_processing_instruction_handler() 处理指令的出现
记法声明 xml_set_notation_decl_handler() 记法声明的出现
默认 xml_set_default_handler() 其它没有指定处理函数的事件
所有的回调函数必须将解析器的实例作为其第一个参数(此外还有其它参数)。
对于本文最后的范例脚本。你需要注意的是它既用到了元素处理函数又用到了字符数据处理函数。元素的回调处理函数通过xml_set_element_handler()来注册。
这个函数需要三个参数:
解析器的实例
处理开始元素的回调函数的名称
处理结束元素的回调函数的名称
当开始解析XML文档时,回调函数必须存在。它们必须定义为与PHP手册中所描述的原型一致。
例如,Expat将三个参数传递给开始元素的处理函数。在脚本范例中,其定义如下:
function start_element($parser, $name, $attrs)
第一个参数是解析器标示,第二个参数是开始元素的名称,第三参数为包含元素所有属性和值的数组。
一旦你开始解析XML文档,Expat在遇到开始元素是都将调用你的start_element()函数并将参数传递过去。
XML的Case Folding选项
用xml_parser_set_option()函数将Case folding选项关闭。这个选项默认是打开的,使得传递给处理函数的元素名自动转换为大写。但XML对大小写是敏感的(所以大小写对统计XML文档是非常重要的)。对于我们的范例,case folding选项必须关闭。
解析文档
在完成所有的准备工作后,现在脚本终于可以解析XML文档:
Xml_parse_from_file(),一个自定义的函数,打开参数中指定的文件,并以4kb的大小进行解析
xml_parse()和xml_parse_from_file()一样,当发生错误时,即XML文档的格式不完全时,将会返回false。
你可以使用xml_get_error_code()函数来得到最后一个错误的数字代码。将此数字代码传递给xml_error_string()函数即可得到错误的文本信息。
输出XML当前的行数,使得调试更容易。
在解析的过程中,调用回调函数。
描述文档结构
当解析文档时,对于Expat需要强调问题的是:如何保持文档结构的基本描述?
如前所述,基于事件的解析器本身并不产生任何结构信息。
不过标签(tag)结构是XML的重要特性。例如,元素序列book>title>表示的意思不同于figure>title>。也就是说,任何作者都会告诉你书名和图名是没有关系的,虽然它们都用到"title"这个术语。因此,为了更有效地使用基于事件的解析器处理XML,你必须使用自己的栈(stacks)或列表(lists)来维护文档的结构信息。
为了产生文档结构的镜像,脚本至少需要知道目前元素的父元素。用Exapt的API是无法实现的,它只报告目前元素的事件,而没有任何前后关系的信息。因此,你需要建立自己的栈结构。
脚本范例使用先进后出(FILO)的栈结构。通过一个数组,栈将保存全部的开始元素。对于开始元素处理函数,目前的元素将被array_push()函数推到栈的顶部。相应的,结束元素处理函数通过array_pop()将最顶的元素移走。
对于序列book>title>/title>/book>,栈的填充如下:
开始元素book:将"book"赋给栈的第一个元素($stack[0])。
开始元素title:将"title"赋给栈的顶部($stack[1])。
结束元素title:从栈中将最顶部的元素移去($stack[1])。
结束元素title:从栈中将最顶部的元素移去($stack[0])。
PHP3.0通过一个$depth变量手动控制元素的嵌套来实现范例。这就使脚本看起来比较复杂。PHP4.0通过array_pop()和array_push()两个函数来使脚本看起来更简洁。
收集数据
为了收集每个元素的信息,脚本需要记住每个元素的事件。通过使用一个全局的数组变量$elements来保存文档中所有不同的元素。数组的项目是元素类的实例,有4个属性(类的变量)
$count -该元素在文档中被发现的次数
$chars -元素中字符事件的字节数
$parents -父元素
$childs - 子元素
正如你所看到的,将类实例保存在数组中是轻而易举的。
注意:PHP的一个特性是你可以通过while(list() = each())loop遍历整个类结构,如同你遍历整个相应的数组一样。所有的类变量(当你用PHP3.0时还有方法名)都以字符串的方式输出。
当发现一个元素时,我们需要增加其相应的记数器来跟踪它在文档中出现多少次。在相应的$elements项中的记数元素也要加一。
我们同样要让父元素知道目前的元素是它的子元素。因此,目前元素的名称将会加入到父元素的$childs数组的项目中。最后,目前元素应该记住谁是它的父元素。所以,父元素被加入到目前元素$parents数组的项目中。
显示统计信息
剩下的代码在$elements数组和其子数组中循环显示其统计结果。这就是最简单的嵌套循环,尽管输出正确的结果,但代码既不简洁又没有任何特别的技巧,它仅仅是一个你可能每天用他来完成工作的循环。
脚本范例被设计为通过PHP的CGI方式的命令行来调用。因此,统计结果输出的格式为文本格式。如果你要将脚本运用到互联网上,那么你需要修改输出函数来产生HTML格式。
总结
Exapt是PHP的XML解析器。作为基于事件的解析器,它不产生文档的结构描述。但通过提供底层访问,这就使得可以更好地利用资源和更快地访问。
作为一个不检查有效性的解析器,Expat忽略与XML文档连接的DTD,但如果文档的格式不完整,它将会随着出错信息而停止。
提供事件处理函数来处理文档
建立自己的事件结构例如栈和树来获得XML结构信息标记的优点。
每天都有新的XML程序出现,而PHP对XML的支持也不断加强(例如,增加了支持基于DOM的XML解析器LibXML)。
有了PHP和Expat,你就可以为即将出现的有效、开放和独立于平台的标准作准备。
范例
/*****************************************************************************
* 名称:XML解析范例:XML文档信息统计
* 描述
* 本范例通过PHP的Expat解析器收集和统计XML文档的信息(例如:每个元素出现的次数、父元素和子元素
* XML文件作为一个参数 ./xmlstats_PHP4.php3 test.xml
* $Requires: Expat 要求:Expat PHP4.0编译为CGI模式
*****************************************************************************/
// 第一个参数是XML文件
$file = $argv[1];
// 变量的初始化
$elements = $stack = array();
$total_elements = $total_chars = 0;
// 元素的基本类
class element
{
var $count = 0;
var $chars = 0;
var $parents = array();
var $childs = array();
}
// 解析XML文件的函数
function xml_parse_from_file($parser, $file)
{
if(!file_exists($file))
{
die("Can't find file "$file".");
}
if(!($fp = @fopen($file, "r")))
{
die("Can't open file "$file".");
}
while($data = fread($fp, 4096))
{
if(!xml_parse($parser, $data, feof($fp)))
{
return(false);
}
}
fclose($fp);
return(true);
}
// 输出结果函数(方框形式)
function print_box($title, $value)
{
printf("n %'-60s n", "");
printf("| s", "$title:");
printf("s", $value);
printf("&s|n", "");
printf(" %'-60s n", "");
}
// 输出结果函数(行形式)
function print_line($title, $value)
{
printf(" s", "$title:");
printf("sn", $value);
}
// 排序函数
function my_sort($a, $b)
{
return(is_object($a) && is_object($b) ? $b->count - $a->count: 0);
}
function start_element($parser, $name, $attrs)
{
global $elements, $stack;
// 元素是否已在全局$elements数组中?
if(!isset($elements[$name]))
{
// 否-增加一个元素的类实例
$element = new element;
$elements[$name] = $element;
}
// 该元素的记数器加一
$elements[$name]->count ;
// 是否有父元素?
if(isset($stack[count($stack)-1]))
{
// 是-将父元素赋给$last_element
$last_element = $stack[count($stack)-1];
// 如果目前元素的父元素数组为空,初始化为0
if(!isset($elements[$name]->parents[$last_element]))
{
$elements[$name]->parents[$last_element] = 0;
}
// 该元素的父元素记数器加一
$elements[$name]->parents[$last_element] ;
// 如果目前元素的父元素的子元素数组为空,初始化为0
if(!isset($elements[$last_element]->childs[$name]))
{
$elements[$last_element]->childs[$name] = 0;
}
// 该元素的父元素的子元素记数器加一
$elements[$last_element]->childs[$name] ;
}
// 将目前的元素加入到栈中
array_push($stack, $name);
}
function stop_element($parser, $name)
{
global $stack;
// 从栈中将最顶部的元素移去
array_pop($stack);
}
function char_data($parser, $data)
{
global $elements, $stack, $depth;
// 增加目前元素的字符数目
$elements[$stack[count($stack)-1]]->chars = strlen(trim($data));
}
// 产生解析器的实例
$parser = xml_parser_create();
// 设置处理函数
xml_set_element_handler($parser, "start_element", "stop_element");
xml_set_character_data_handler($parser, "char_data");
xml_parser_set_option($parser, XML_OPTION_CASE_FOLDING, 0);
// 解析文件
$ret = xml_parse_from_file($parser, $file);
if(!$ret)
{
die(sprintf("XML error: %s at line %d",
xml_error_string(xml_get_error_code($parser)),
xml_get_current_line_number($parser)));
}
// 释放解析器
xml_parser_free($parser);
// 释放协助元素
unset($elements["current_element"]);
unset($elements["last_element"]);
// 根据元素的次数排序
uasort($elements, "my_sort");
// 在$elements中循环收集元素信息
while(list($name, $element) = each($elements))
{
print_box("Element name", $name);
print_line("Element count", $element->count);
print_line("Character count", $element->chars);
printf("n sn", "* Parent elements");
// 在该元素的父中循环,输出结果
while(list($key, $value) = each($element->parents))
{
print_line($key, $value);
}
if(count($element->parents) == 0)
{
printf("5sn", "[root element]");
}
// 在该元素的子中循环,输出结果
printf("n sn", "* Child elements");
while(list($key, $value) = each($element->childs))
{
print_line($key, $value);
}
if(count($element->childs) == 0)
{
printf("5sn", "[no childs]");
}
$total_elements = $element->count;
$total_chars = $element->chars;
}
// 最终结果
print_box("Total elements", $total_elements);
print_box("Total characters", $total_chars);
?>
(原文为Tobias Ratschiller 所著,发表在http://www.zend.com上

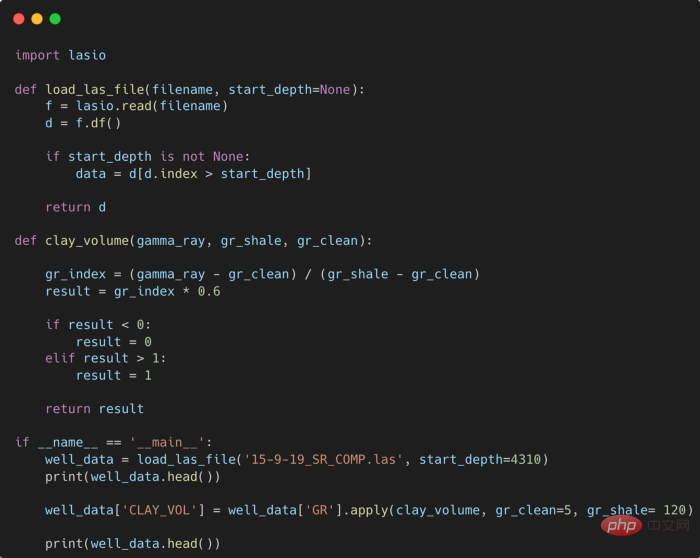 提高 Python 代码可读性的五个基本技巧Apr 12, 2023 pm 08:58 PM
提高 Python 代码可读性的五个基本技巧Apr 12, 2023 pm 08:58 PMPython 中有许多方法可以帮助我们理解代码的内部工作原理,良好的编程习惯,可以使我们的工作事半功倍!例如,我们最终可能会得到看起来很像下图中的代码。虽然不是最糟糕的,但是,我们需要扩展一些事情,例如:load_las_file 函数中的 f 和 d 代表什么?为什么我们要在 clay 函数中检查结果?这些函数需要什么类型?Floats? DataFrames?在本文中,我们将着重讨论如何通过文档、提示输入和正确的变量名称来提高应用程序/脚本的可读性的五个基本技巧。1. Comments我们可
 CRPS:贝叶斯机器学习模型的评分函数Apr 12, 2023 am 11:07 AM
CRPS:贝叶斯机器学习模型的评分函数Apr 12, 2023 am 11:07 AM连续分级概率评分(Continuous Ranked Probability Score, CRPS)或“连续概率排位分数”是一个函数或统计量,可以将分布预测与真实值进行比较。机器学习工作流程的一个重要部分是模型评估。这个过程本身可以被认为是常识:将数据分成训练集和测试集,在训练集上训练模型,并使用评分函数评估其在测试集上的性能。评分函数(或度量)是将真实值及其预测映射到一个单一且可比较的值 [1]。例如,对于连续预测可以使用 RMSE、MAE、MAPE 或 R 平方等评分函数。如果预测不是逐点
 详解JavaScript函数如何实现可变参数?(总结分享)Aug 04, 2022 pm 02:35 PM
详解JavaScript函数如何实现可变参数?(总结分享)Aug 04, 2022 pm 02:35 PMjs是弱类型语言,不能像C#那样使用param关键字来声明形参是一个可变参数。那么js中,如何实现这种可变参数呢?下面本篇文章就来聊聊JavaScript函数可变参数的实现方法,希望对大家有所帮助!
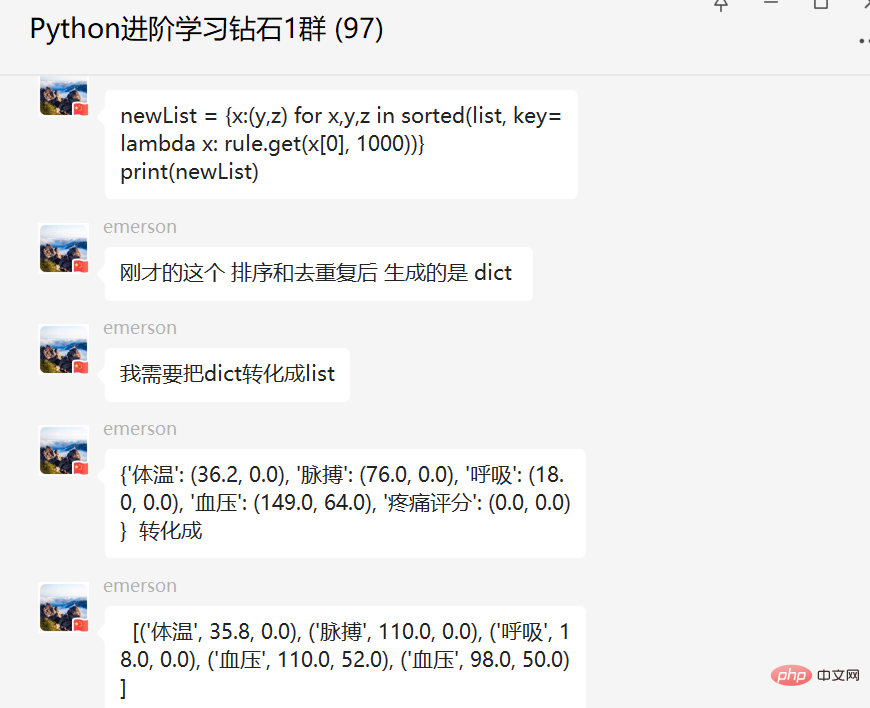 盘点Python内置函数sorted()高级用法实战May 13, 2023 am 10:34 AM
盘点Python内置函数sorted()高级用法实战May 13, 2023 am 10:34 AM一、前言前几天在Python钻石交流群有个叫【emerson】的粉丝问了一个Python排序的问题,这里拿出来给大家分享下,一起学习下。其实这里【瑜亮老师】、【布达佩斯的永恒】等人讲了很多,只不过对于基础不太好的小伙伴们来说,还是有点难的。不过在实际应用中内置函数sorted()用的还是蛮多的,这里也单独拿出来讲一下,希望下次再有小伙伴遇到的时候,可以不慌。二、基础用法内置函数sorted()可以用来做排序,基础的用法很简单,看个例子,如下所示。lst=[3,28,18,29,2,5,88
 学Python,还不知道main函数吗Apr 12, 2023 pm 02:58 PM
学Python,还不知道main函数吗Apr 12, 2023 pm 02:58 PMPython 中的 main 函数充当程序的执行点,在 Python 编程中定义 main 函数是启动程序执行的必要条件,不过它仅在程序直接运行时才执行,而在作为模块导入时不会执行。要了解有关 Python main 函数的更多信息,我们将从如下几点逐步学习:什么是 Python 函数Python 中 main 函数的功能是什么一个基本的 Python main() 是怎样的Python 执行模式Let’s get started什么是 Python 函数相信很多小伙伴对函数都不陌生了,函数是可
 Python面向对象里常见的内置成员介绍Apr 12, 2023 am 09:10 AM
Python面向对象里常见的内置成员介绍Apr 12, 2023 am 09:10 AM好嘞,今天我们继续剖析下Python里的类。[[441842]]先前我们定义类的时候,使用到了构造函数,在Python里的构造函数书写比较特殊,他是一个特殊的函数__init__,其实在类里,除了构造函数还有很多其他格式为__XXX__的函数,另外也有一些__xx__的属性。下面我们一一说下:构造函数Python里所有类的构造函数都是__init__,其中根据我们的需求,构造函数又分为有参构造函数和无惨构造函数。如果当前没有定义构造函数,那么系统会自动生成一个无参空的构造函数。例如:在有继承关系
 Golang函数的类型断言用法介绍May 16, 2023 am 08:02 AM
Golang函数的类型断言用法介绍May 16, 2023 am 08:02 AMGolang的函数类型断言是一个非常重要的特性,它可以让我们在函数中精细地控制变量的类型,从而更加方便地进行数据处理和转换。本文将介绍Golang函数的类型断言用法,希望能够对大家的学习有所帮助。一、什么是Golang函数的类型断言?Golang函数的类型断言可以理解为函数参数中所声明变量的类型具有多态性,这使得一个函数在不同的参数传递下可以灵活
 Python编程:有关函数返回值以及最佳实践基本指导原则Apr 10, 2023 am 11:31 AM
Python编程:有关函数返回值以及最佳实践基本指导原则Apr 10, 2023 am 11:31 AM本篇内容作为以函数为主题的最后一篇,来介绍一下函数返回值以及编写函数的一些基本的最佳实践指导原则。函数输出:返回值函数的返回值是Python领先于竞争对手的东西之一。在大多数其他语言中,函数通常只允许返回一个对象,但是在Python中,你可以返回一个元组——这意味着可以返回任何你想要的东西。这个特性允许程序员编写用其他语言编写的软件要困难得多,或者肯定会更加乏味。我们已经说过,要从函数返回一些东西,我们需要使用return语句,后面跟着我们想要返回的东西。函数体中可以根据需要有多个返回语句。另一


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

SublimeText3 Linux新版
SublimeText3 Linux最新版

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

