
第一!vivo自研AI大模型位列C-Eval、CMMLU榜首

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB转载
- 2023-10-16 15:17:01936浏览
国内自研AI大模型再次迎来显着突破。
10月16日消息,vivo将发布自研AI大模型矩阵,其中包括十亿、百亿、千亿三个不同参数量级的5款自研大模型,全面覆盖核心应用场景。 最新数据显示,vivo自研AI大模型同时位列C-Eval、CMMLU双榜的全球中文榜单榜首,在人文、社科等领域的表现远超同级别大模型。
C-Eval榜单是由清华大学、上海交通大学和爱丁堡大学合作构建的面向中文语言模型的综合性考试评测集,涵盖52个不同学科,共有13948道多项选择题,是目前较为权威的中文AI大模型评测榜单。 CMMLU数据集则是一个综合性的中文评估基准,由MBZUAI、上海交通大学、微软亚洲研究院共同推出,在评估语言模型在中文语境下的知识和推理能力方面极具权威性。
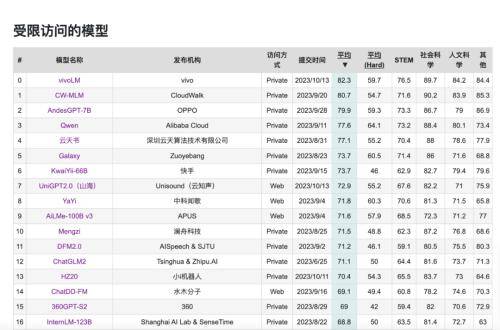
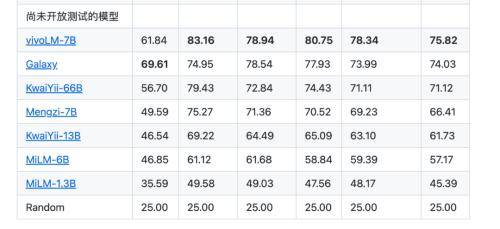
据相关负责人透露,vivo自研AI大模型将会在即将发布的OriginOS 4系统中被首次应用,为消费者带来更加智能、便捷、安全的手机使用体验。
当下,AI大模型技术快速发展,推动社会生产、生活方式发生颠覆性变革,在手机行业,其也有望成为厂商加速产品迭代、开辟蓝海赛道的关键机遇。本次vivo打造自研AI大模型矩阵并将其应用于新系统,证明其对大模型的探索已从技术研发阶段进阶至应用及产业布局阶段,这不仅会有力推动vivo自身的业务增长和高端化战略落地,对于整个行业而言都有十分积极的带动作用。
来源:观察者网
以上是第一!vivo自研AI大模型位列C-Eval、CMMLU榜首的详细内容。更多信息请关注PHP中文网其他相关文章!
声明:
本文转载于:sohu.com。如有侵权,请联系admin@php.cn删除