
跨模态Transformer:面向快速鲁棒的3D目标检测

- 王林转载
- 2023-10-10 22:53:161220浏览

目前,在自动驾驶的车辆中已经配备了多种信息采集传感器,如激光雷达、毫米波雷达以及相机传感器。从目前来看,多种传感器在自动驾驶的感知任务中显示出了巨大的发展前景。例如,相机采集到的2D图像信息捕获了丰富的语义特征,激光雷达采集到的点云数据可以为感知模型提供物体的准确位置信息和几何信息。通过充分利用不同传感器获取到的信息,可以减少自动驾驶感知过程中的不确定性因素的发生,同时提升感知模型的检测鲁棒性
今天介绍的是一篇来自旷视的自动驾驶感知论文,并且中稿了今年的ICCV2023 视觉顶会,该文章的主要特点是类似PETR这类End-to-End的BEV感知算法(不再需要利用NMS后处理操作过滤感知结果中的冗余框),同时又额外使用了激光雷达的点云信息来提高模型的感知性能,是一篇非常不错的自动驾驶感知方向的论文,文章的链接和官方开源仓库链接如下:
- 论文链接:https://arxiv.org/pdf/2301.01283.pdf
- 代码链接:https://github.com/junjie18/CMT
CMT算法模型整体结构
接下来,我们将对CMT感知模型的网络结构进行整体介绍,如下图所示:
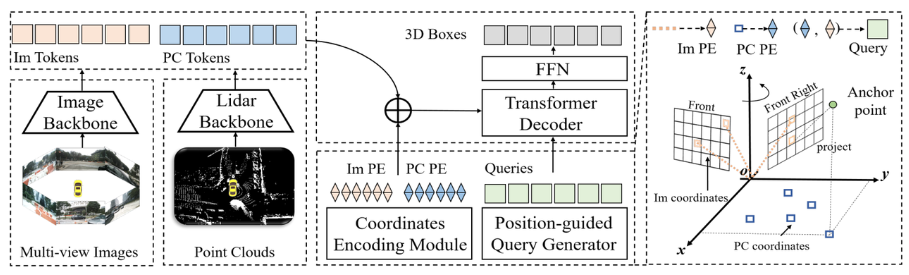
通过整个算法框图可以看出,整个算法模型主要包括三个部分
- 激光雷达主干网络+相机主干网络(Image Backbone + Lidar Backbone):用于获取点云和环视图像的特征得到Point Cloud Token**(PC Tokens)以及Image Token(Im Tokens)**
- 位置编码的生成:针对不同传感器采集到的数据信息,Im Tokens生成对应的坐标位置编码Im PE,PC Tokens生成对应的坐标位置编码PC PE,同时Object Queries也生成对应的坐标位置编码查询嵌入
- Transformer Decoder+FFN网络:输入为Object Queries + 查询嵌入 以及完成位置编码的Im Tokens和PC Tokens进行交叉注意力的计算,利用FFN生成最终的3D Boxes + 类别预测
在详细介绍了网络的整体结构之后,接下来将详细介绍上述提到的三个子部分
激光雷达主干网络+相机主干网络(Image Backbone + Lidar Backbone)
- 激光雷达主干网络
通常采用的激光雷达主干网络提取点云数据特征包括以下五个部分
- 点云信息体素化
- 体素特征编码
- 3D Backbone(常用VoxelResBackBone8x网络)对体素特征编码后的结果进行3D特征的提取
- 将3D Backbone提取到特征的Z轴进行压缩,得到BEV空间下的特征
- 利用2D Backbone对投影到BEV空间的特征做进一步的特征拟合
- 由于2D Backbone输出的特征图的通道数与Image输出的通道数不一致,用了一个卷积层进行通道数的对齐(针对本文模型而言,做了一个通道数量的对齐,但并不属于原有点云信息提取的范畴)
- 相机主干网络
一般采用的相机主干网络提取2D图像特征包括以下两个部分: 输入:2D Backbone输出的降采样16倍和32倍的特征图
输出:将下采样16倍和32倍的图像特征进行融合,获取降采样16倍的特征图
Tensor([bs * N, 1024, H / 16, W / 16])Tensor([bs * N, 1024, H / 16, W / 16])Tensor([bs * N,2048,H / 16,W / 16])需要重新写的内容是:张量([bs * N,256,H / 16,W / 16])-
Tensor([bs * N,2048,H / 16,W / 16]) -
需要重新写的内容是:张量([bs * N,256,H / 16,W / 16])🎜🎜重写内容:使用ResNet-50网络来提取环视图像的特征🎜🎜🎜🎜输出:输出下采样16倍和32倍的图像特征🎜 输入张量:
Tensor([bs * N,3,H,W])Tensor([bs * N,3,H,W])输出张量:
Tensor([bs * N,1024,H / 16,W / 16])输出张量:``Tensor([bs * N,2048,H / 32,W / 32])`
需要进行改写的内容是:2D骨架提取图像特征
Neck(CEFPN)
位置编码的生成
根据以上介绍,位置编码的生成主要包括三个部分,分别是图像位置嵌入、点云位置嵌入和查询嵌入。下面将逐一介绍它们的生成过程
- Image Position Embedding(Im PE)
Image Position Embedding的生成过程与PETR中图像位置编码的生成逻辑是一样的(具体可以参考PETR论文原文,这里不做过多的阐述),可以总结为以下四个步骤:
- 在图像坐标系下生成3D图像视锥点云
- 3D图像视锥点云利用相机内参矩阵变换到相机坐标系下得到3D相机坐标点
- 相机坐标系下的3D点利用cam2ego坐标变换矩阵转换到BEV坐标系下
- 将转换后的BEV 3D 坐标利用MLP层进行位置编码得到最终的图像位置编码
- Point Cloud Position Embedding(PC PE)
Point Cloud Position Embedding的生成过程可以分为以下两个步骤 -
在BEV空间的网格坐标点利用
pos2embed()
输出张量:Tensor([bs * N,1024,H / 16,W / 16])
输出张量:``Tensor([bs * N,2048,H / 32,W / 32])` -
需要进行改写的内容是:2D骨架提取图像特征
Neck(CEFPN)
位置编码的生成
根据以上介绍,位置编码的生成主要包括三个部分,分别是图像位置嵌入、点云位置嵌入和查询嵌入。下面将逐一介绍它们的生成过程Image Position Embedding(Im PE)Image Position Embedding的生成过程与PETR中图像位置编码的生成逻辑是一样的(具体可以参考PETR论文原文,这里不做过多的阐述),可以总结为以下四个步骤:
在图像坐标系下生成3D图像视锥点云
3D图像视锥点云利用相机内参矩阵变换到相机坐标系下得到3D相机坐标点
相机坐标系下的3D点利用cam2ego坐标变换矩阵转换到BEV坐标系下
- Point Cloud Position Embedding(PC PE)
Point Cloud Position Embedding的生成过程可以分为以下两个步骤
在BEV空间的网格坐标点利用
函数将二维的横纵坐标点变换到高维的特征空间pos2embed()# 点云位置编码`bev_pos_embeds`的生成bev_pos_embeds = self.bev_embedding(pos2embed(self.coords_bev.to(device), num_pos_feats=self.hidden_dim))def coords_bev(self):x_size, y_size = (grid_size[0] // downsample_scale,grid_size[1] // downsample_scale)meshgrid = [[0, y_size - 1, y_size], [0, x_size - 1, x_size]]batch_y, batch_x = torch.meshgrid(*[torch.linspace(it[0], it[1], it[2]) for it in meshgrid])batch_x = (batch_x + 0.5) / x_sizebatch_y = (batch_y + 0.5) / y_sizecoord_base = torch.cat([batch_x[None], batch_y[None]], dim=0) # 生成BEV网格.coord_base = coord_base.view(2, -1).transpose(1, 0)return coord_base# shape: (x_size *y_size, 2)def pos2embed(pos, num_pos_feats=256, temperature=10000):scale = 2 * math.pipos = pos * scaledim_t = torch.arange(num_pos_feats, dtype=torch.float32, device=pos.device)dim_t = temperature ** (2 * (dim_t // 2) / num_pos_feats)pos_x = pos[..., 0, None] / dim_tpos_y = pos[..., 1, None] / dim_tpos_x = torch.stack((pos_x[..., 0::2].sin(), pos_x[..., 1::2].cos()), dim=-1).flatten(-2)pos_y = torch.stack((pos_y[..., 0::2].sin(), pos_y[..., 1::2].cos()), dim=-1).flatten(-2)posemb = torch.cat((pos_y, pos_x), dim=-1)return posemb# 将二维的x,y坐标编码成512维的高维向量
-
通过使用多层感知器(MLP)网络进行空间转换,确保通道数量的对齐
🎜查询嵌入🎜🎜🎜🎜为了让Object Queries、Image Token以及Lidar Token之间计算相似性更加的准确,论文中的查询嵌入会利用Lidar和Camera生成位置编码的逻辑来生成;具体而言查询嵌入 = Image Position Embedding(同下面的rv_query_embeds) + Point Cloud Position Embedding(同下面的bev_query_embeds)。🎜🎜🎜🎜🎜🎜🎜🎜bev_query_embeds生成逻辑🎜🎜🎜🎜由于论文中的Object Query原本就是在BEV空间进行初始化的,所以直接复用Point Cloud Position Embedding生成逻辑中的位置编码和bev_embedding()函数即可,对应关键代码如下:🎜def _bev_query_embed(self, ref_points, img_metas):bev_embeds = self.bev_embedding(pos2embed(ref_points, num_pos_feats=self.hidden_dim))return bev_embeds# (bs, Num, 256)
🎜🎜🎜🎜🎜🎜🎜rv_query_embeds生成逻辑需要被重新编写🎜🎜🎜🎜在前面提到的内容中,Object Query是在BEV坐标系下的初始点。为了遵循Image Position Embedding的生成过程,论文中需要先将BEV坐标系下的3D空间点投影到图像坐标系下,然后再利用之前生成Image Position Embedding的处理逻辑,以确保生成过程的逻辑相同。以下是核心代码:🎜def _rv_query_embed(self, ref_points, img_metas):pad_h, pad_w = pad_shape# 由归一化坐标点映射回正常的roi range下的3D坐标点ref_points = ref_points * (pc_range[3:] - pc_range[:3]) + pc_range[:3]points = torch.cat([ref_points, ref_points.shape[:-1]], dim=-1)points = bda_mat.inverse().matmul(points)points = points.unsqueeze(1)points = sensor2ego_mats.inverse().matmul(points)points =intrin_mats.matmul(points)proj_points_clone = points.clone() # 选择有效的投影点z_mask = proj_points_clone[..., 2:3, :].detach() > 0proj_points_clone[..., :3, :] = points[..., :3, :] / (points[..., 2:3, :].detach() + z_mask * 1e-6 - (~z_mask) * 1e-6)proj_points_clone = ida_mats.matmul(proj_points_clone)proj_points_clone = proj_points_clone.squeeze(-1)mask = ((proj_points_clone[..., 0] = 0)& (proj_points_clone[..., 1] = 0))mask &= z_mask.view(*mask.shape)coords_d = (1 + torch.arange(depth_num).float() * (pc_range[4] - 1) / depth_num)projback_points = (ida_mats.inverse().matmul(proj_points_clone))projback_points = torch.einsum("bvnc, d -> bvndc", projback_points, coords_d)projback_points = torch.cat([projback_points[..., :3], projback_points.shape[:-1]], dim=-1)projback_points = (sensor2ego_mats.matmul(intrin_mats).matmul(projback_points))projback_points = (bda_mat@ projback_points)projback_points = (projback_points[..., :3] - pc_range[:3]) / (pc_range[3:] - self.pc_range[:3])rv_embeds = self.rv_embedding(projback_points)rv_embeds = (rv_embeds * mask).sum(dim=1)return rv_embeds🎜通过上述的变换,即完成了BEV空间坐标系下的点先投影到图像坐标系,再利用之前生成Image Position Embedding的处理逻辑生成rv_query_embeds的过程。🎜🎜最后查询嵌入 = rv_query_embeds + bev_query_embeds🎜🎜🎜🎜
Transformer Decoder+FFN网络
- Transformer Decoder
这里与Transformer中的Decoder计算逻辑是完全一样的,但在输入数据上有点不同
- 第一点是Memory:这里的Memory是Image Token和Lidar Token进行Concat后的结果(可以理解为两种模态的融
- 第二点是位置编码:这里的位置编码是rv_query_embeds和bev_query_embeds进行concat的结果,query_embed是rv_query_embeds + bev_query_embeds;
- FFN网络
这个FFN网络的作用与PETR中的作用是完全相同的,具体的输出结果可以看PETR原文,这里就不做过多的赘述了。
论文实验结果
首先先放出来CMT和其他自动驾驶感知算法的比较实验,论文作者分别在nuScenes的test和val集上进行了比较,实验结果如下
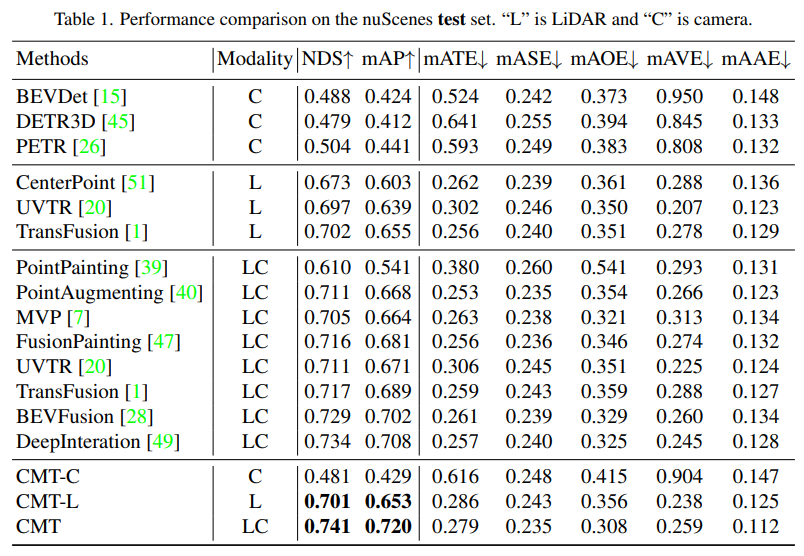
- 各个感知算法在nuScenes的test set上的感知结果对比
表格中的Modality代表输入到感知算法中的传感器类别,C代表相机传感器,模型只喂入相机数据。L代表激光雷达传感器,模型只喂入点云数据。LC代表激光雷达和相机传感器,模型输入的是多模态的数据。通过实验结果可以看出,CMT-C模型的性能要高于BEVDet和DETR3D。CMT-L模型的性能要高于CenterPoint和UVTR这类纯激光雷达的感知算法模型。而当CMT采用激光雷达的点云数据和相机数据后超越了现有的所有单模态方法,得到了SOTA的结果。
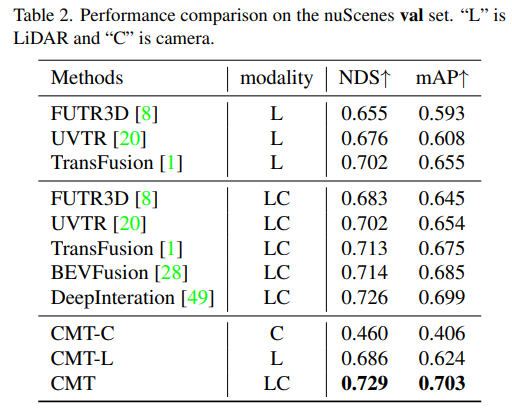
- 模型在nuScenes的val set上的感知结果对比
通过实验结果可以看出,CMT-L的感知模型的性能超越了FUTR3D和UVTR。当同时采用激光雷达的点云数据和相机数据后,CMT较大幅度超越了现有的采用多模态的感知算法,像FUTR3D、UVTR、TransFusion、BEVFusion等多模态算法,取得了在val set上的SOTA结果。
接下来是CMT创新点的消融实验部分
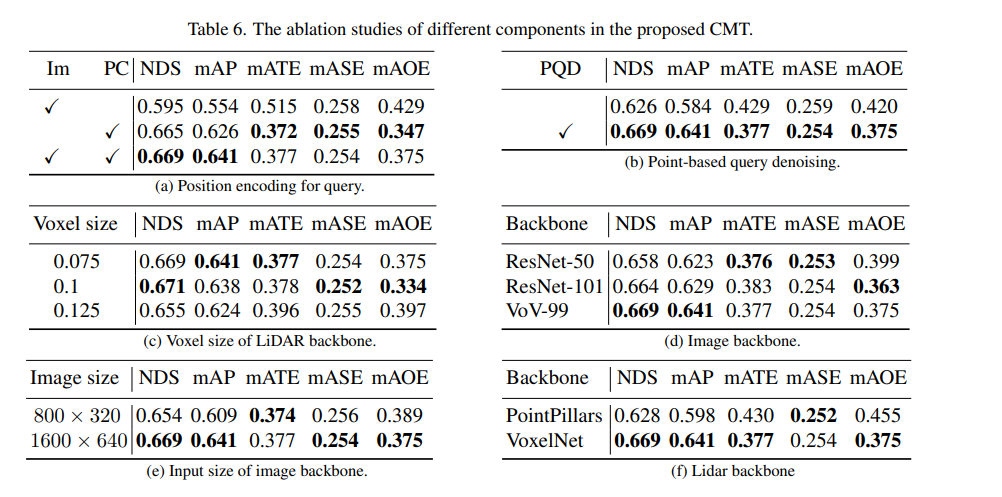
首先,我们进行了一系列消融实验,来确定是否采用位置编码。通过实验结果发现,当同时采用图像和激光雷达的位置编码时,NDS和mAP指标实现了最佳效果。接下来,在消融实验的(c)和(f)部分,我们对点云主干网络的类型和体素大小进行了不同的尝试。而在(d)和(e)部分的消融实验中,我们则对相机主干网络的类型和输入分辨率的大小进行了不同的尝试。以上只是对实验内容的简要概括,如需了解更多详细的消融实验,请参阅原文
最后放一张CMT的感知结果在nuScenes数据集上可视化结果的展示,通过实验结果可以看出,CMT还是有较好的感知结果的。

总结
目前,将各种模态融合在一起以提升模型的感知性能已经成为一个热门的研究方向(尤其是在自动驾驶汽车上,配备了多种传感器)。同时,CMT是一个完全端到端的感知算法,不需要额外的后处理步骤,并且在nuScenes数据集上具有最先进的精度。本文对这篇文章进行了详细介绍,希望对大家有所帮助
需要重写的内容是: 原文链接:https://mp.weixin.qq.com/s/Fx7dkv8f2ibkfO66-5hEXA
以上是跨模态Transformer:面向快速鲁棒的3D目标检测的详细内容。更多信息请关注PHP中文网其他相关文章!