



图像语义分割是计算机视觉领域的一个重要研究方向,其目标是将输入的图像分割成多个具有语义含义的区域。在实际应用中,精确地标记每个像素的语义类别是一个关键问题。本文将探讨图像语义分割中的像素精确度问题,并给出相应的代码示例。
一、像素精确度问题分析
在图像语义分割中,像素精确度是评估分割算法性能的重要指标之一。准确地标记每个像素的语义类别对于图像分割结果的正确性至关重要。然而,由于图像中不同地区的物体边界模糊、噪声、光照变化等因素的干扰,实现像素精确度是非常具有挑战性的。
二、改进方法与代码示例
- 使用更精准的标注数据集
精准的标注数据集可以提供更准确的像素标签,为分割算法提供更可靠的ground truth。我们可以通过使用高质量的标注数据集,如PASCAL VOC,COCO等,来提高像素精确度。
代码示例:
from PIL import Image
import numpy as np
def load_labels(image_path):
# 从标注文件中加载像素级标签
label_path = image_path.replace('.jpg', '.png')
label = Image.open(label_path)
label = np.array(label) # 转换为numpy数组
return label
def evaluate_pixel_accuracy(pred_label, gt_label):
# 计算像素级精确度
num_correct = np.sum(pred_label == gt_label)
num_total = pred_label.size
accuracy = num_correct / num_total
return accuracy
# 加载预测结果和ground truth
pred_label = load_labels('pred_image.jpg')
gt_label = load_labels('gt_image.jpg')
accuracy = evaluate_pixel_accuracy(pred_label, gt_label)
print("Pixel Accuracy: ", accuracy)- 使用更复杂的模型
使用更复杂的模型,例如深度学习中的卷积神经网络(CNN),可以提高分割算法的像素精确度。这些模型能够学习到更高级的语义特征,并更好地处理图像中的细节。
代码示例:
import torch
import torchvision.models as models
# 加载预训练的分割模型
model = models.segmentation.deeplabv3_resnet50(pretrained=True)
# 加载图像数据
image = Image.open('image.jpg')
# 对图像进行预处理
preprocess = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
input_tensor = preprocess(image)
input_batch = input_tensor.unsqueeze(0)
# 使用模型进行预测
with torch.no_grad():
output = model(input_batch)['out'][0]
pred_label = output.argmax(0).numpy()
# 计算像素级精确度
accuracy = evaluate_pixel_accuracy(pred_label, gt_label)
print("Pixel Accuracy: ", accuracy)三、总结
在图像语义分割中,像素精确度是一个重要指标,评估分割算法的性能。本文介绍了改进像素精确度的方法和相应的代码示例,包括使用更精准的标注数据集和使用更复杂的模型。通过这些方法,可以提高分割算法的像素精确度,并获得更准确的分割结果。
以上是图像语义分割中的像素精确度问题的详细内容。更多信息请关注PHP中文网其他相关文章!

 Agent SDK vs Crewai vs Langchain:哪个何时使用?Apr 24, 2025 am 10:39 AM
Agent SDK vs Crewai vs Langchain:哪个何时使用?Apr 24, 2025 am 10:39 AM本文比较了建立AI代理的三个流行框架:OpenAI的Agent SDK,Langchain和Crewai。 每个都为自动化任务和增强决策提供了独特的优势。 这篇文章指导您选择最佳帧
 使用Pydantic构建结构化研究自动化系统Apr 24, 2025 am 10:32 AM
使用Pydantic构建结构化研究自动化系统Apr 24, 2025 am 10:32 AM在学术研究的动态领域,有效的信息收集,综合和演示至关重要。 文献综述的手动过程是耗时的,阻碍了更深入的分析。 多代理研究助理系统BUI
 10 GPT-4O图像生成会提示今天尝试!Apr 24, 2025 am 10:26 AM
10 GPT-4O图像生成会提示今天尝试!Apr 24, 2025 am 10:26 AMAI世界中发生了绝对野生的事情。 Openai的本地形象生成现在很疯狂。我们正在谈论令人jaw目结舌的视觉效果,可怕的细节和抛光的输出
 用帆板编码的氛围指南Apr 24, 2025 am 10:25 AM
用帆板编码的氛围指南Apr 24, 2025 am 10:25 AM毫不费力地将您的编码愿景带入Codeium's Windsurf,这是您的AI驱动的编码伴侣。 Windsurf简化了整个软件开发生命周期,从编码和调试到优化,将过程转换为INTU
 使用RMGB v2.0探索图像背景删除Apr 24, 2025 am 10:20 AM
使用RMGB v2.0探索图像背景删除Apr 24, 2025 am 10:20 AMBraiai的RMGB v2.0:强大的开源背景拆卸模型 图像分割模型正在彻底改变各个领域,而背景删除是进步的关键领域。 Braiai的RMGB v2.0是最先进的开源M
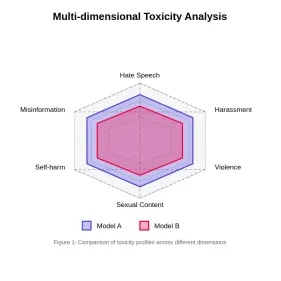 评估大语模型中的毒性Apr 24, 2025 am 10:14 AM
评估大语模型中的毒性Apr 24, 2025 am 10:14 AM本文探讨了大语言模型(LLM)中的毒性至关重要问题以及用于评估和减轻它的方法。 LLM,为从聊天机器人到内容生成的各种应用程序提供动力,需要强大的评估指标,机智
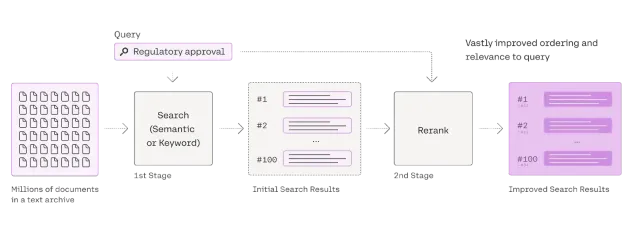 Rag Reranker的综合指南Apr 24, 2025 am 10:10 AM
Rag Reranker的综合指南Apr 24, 2025 am 10:10 AM检索增强发电(RAG)系统正在改变信息访问,但其有效性取决于检索到的数据的质量。 这是重读者变得至关重要的地方 - 充当搜索结果的质量过滤器,以确保仅确保
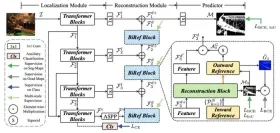
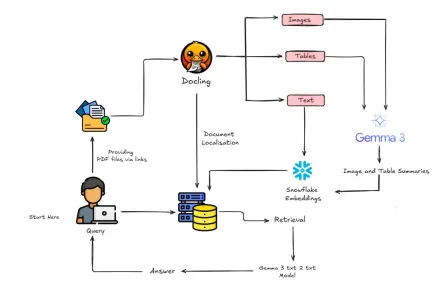 如何使用Gemma 3&Docling构建多模式抹布?Apr 24, 2025 am 10:04 AM
如何使用Gemma 3&Docling构建多模式抹布?Apr 24, 2025 am 10:04 AM该教程通过在Google Colab中构建精致的多式联运检索一代(RAG)管道来指导您。 我们将使用Gemma 3(用于语言和视觉),文档(文档转换),Langchain等尖端工具


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

SublimeText3汉化版
中文版,非常好用

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

SublimeText3 Linux新版
SublimeText3 Linux最新版

WebStorm Mac版
好用的JavaScript开发工具

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

