



视频理解中的行为识别问题,需要具体代码示例
摘要:随着人工智能技术的发展,视频理解已经成为一个热门的研究领域。其中,行为识别是视频理解的重要任务之一。本文将介绍行为识别的背景意义,探讨该问题的挑战性,并提供一些具体的代码示例,帮助读者理解行为识别的实现方法。
一、引言
视频理解是指通过对视频数据的解析和分析,从中获取有关内容、结构和语义的信息。最常见和重要的任务之一就是行为识别。行为识别的目标是从视频中识别出特定的行为或活动,如人物的运动、交通信号灯、人物的情绪等。行为识别在很多领域都有广泛的应用,例如视频监控、无人驾驶、视频会议等。
二、行为识别的挑战性
行为识别是一个具有挑战性的问题。首先,视频中的行为是多样化的,涉及到很多不同的对象和动作。这就要求算法能够具备很强的泛化能力,能够适应各种不同的场景和环境。
其次,视频数据的维度很高。对于每一帧视频,都会包含很多像素点的信息,而且视频的时长也很长。因此,对于大规模的视频数据,如何高效地提取有用的特征,并进行有效的分类是一个关键问题。
另外,视频中的行为是动态的、时序变化的。这就要求算法能够对视频序列的时序信息进行建模,能够捕捉到行为的时序关系。这对于算法的设计和优化提出了进一步的要求。
三、行为识别的实现方法
行为识别的实现方法主要分为两个步骤:特征提取和分类模型训练。
特征提取是指从视频中提取有用的特征信息,以便后续的分类模型训练。常用的特征提取方法有两种:手工设计的特征和深度学习的特征。
手工设计的特征一般基于前人的经验和知识,通过对视频数据进行观察和分析,提取其中的有用信息。常用的手工设计特征有颜色直方图、光流向量、时空金字塔等。这些特征的提取过程较为复杂,需要一定的专业知识和经验。
深度学习的特征则是利用深度神经网络从数据中自动学习到的特征表示。深度学习的特征在行为识别领域取得了很大的突破,相比于手工设计的特征,深度学习的特征更具有表达能力和泛化能力。
分类模型训练是指通过使用已经提取好的特征,对视频进行分类。分类模型训练可以使用传统的机器学习算法,如支持向量机(SVM)、随机森林等;也可以使用深度神经网络,如卷积神经网络(CNN)、循环神经网络(RNN)等。
代码示例:
以下是一个使用深度学习进行行为识别的代码示例:
import torch
import torch.nn as nn
import torch.optim as optim
# 定义一个简单的行为识别网络
class BehaviorRecognitionNet(nn.Module):
def __init__(self):
super(BehaviorRecognitionNet, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1)
self.relu1 = nn.ReLU(inplace=True)
self.fc1 = nn.Linear(32 * 32 * 32, 64)
self.relu2 = nn.ReLU(inplace=True)
self.fc2 = nn.Linear(64, 10)
def forward(self, x):
x = self.conv1(x)
x = self.relu1(x)
x = x.view(x.size(0), -1)
x = self.fc1(x)
x = self.relu2(x)
x = self.fc2(x)
return x
# 定义训练数据和标签
train_data = torch.randn(100, 3, 32, 32)
train_labels = torch.empty(100, dtype=torch.long).random_(10)
# 创建行为识别网络的实例
net = BehaviorRecognitionNet()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 开始训练
for epoch in range(100):
running_loss = 0.0
# 将输入数据和标签转换为张量
inputs = torch.tensor(train_data)
targets = torch.tensor(train_labels)
# 清零梯度
optimizer.zero_grad()
# 正向传播
outputs = net(inputs)
loss = criterion(outputs, targets)
loss.backward()
# 更新参数
optimizer.step()
# 打印训练状态
running_loss += loss.item()
if (epoch + 1) % 10 == 0:
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 10))
running_loss = 0.0以上代码是一个简单的行为识别网络的训练过程。通过定义网络架构、损失函数和优化器,以及对输入数据进行处理和训练参数的更新,可以实现一个简单的行为识别模型。
四、结论
本文介绍了行为识别的背景意义、挑战性以及实现方法。行为识别是视频理解中的重要任务之一,其涉及到多样化的行为类型、高维的视频数据和动态的时序信息。通过特征提取和分类模型训练,可以实现行为识别的自动化。通过以上提供的代码示例,读者可以更好地理解和实践行为识别的过程。
以上是视频理解中的行为识别问题的详细内容。更多信息请关注PHP中文网其他相关文章!

 如何利用C++开发高度可定制的编程框架?Aug 25, 2023 pm 01:21 PM
如何利用C++开发高度可定制的编程框架?Aug 25, 2023 pm 01:21 PM如何利用C++开发高度可定制的编程框架?引言:在软件开发领域,我们经常需要构建自己的编程框架来满足特定的需求。C++是一种强大的编程语言,可以用于开发高度可定制的编程框架。本文将介绍如何使用C++来开发一个高度可定制的编程框架,并提供相应的代码示例。一、确定框架的目标和需求在开发框架之前,我们需要明确框架的目标和需求。这些目标和需求将指导我们在设计和实现框架
 解决win11右键无响应问题的步骤Dec 25, 2023 pm 06:56 PM
解决win11右键无响应问题的步骤Dec 25, 2023 pm 06:56 PM一般来说,我们可以通过右键空白处打开右键菜单,或者右键文件打开属性菜单等,但是如果我们在使用win11系统时,出现右键没反应的情况,可以在注册表编辑器中找到对应的项更改设置就解决了,下面一起来操作一下吧。win11右键没反应怎么办1、首先使用键盘“win+r”快捷键打开运行,在其中输入“regedit”回车确定打开注册表。2、在注册表中找到“HKEY_CLASSES_ROOT\lnkfile”路径下的“lnkfile”文件夹。3、然后在右侧右键选择新建一个“字符串值”4、新建完成后双击打开,将它
 如何调整Windows 7桌面显示比例Dec 27, 2023 am 08:13 AM
如何调整Windows 7桌面显示比例Dec 27, 2023 am 08:13 AM使用win7的小伙伴非常的多,在电脑上看视频或是资料的时候都会需要进行比例的调整吧,那么该怎么去调整呢?下面就来看看详细的设置方法吧。win7桌面显示比例怎么设置:1、点击左下角电脑打开“控制面板”。2、随后在控制面板中找到“外观”。3、进入外观后点击“显示”。4、随后即可根据需要显示的效果进行桌面的大小显示调节。5、也可以点击左侧的“调整分辨率”。6、通过更改屏幕分辨率来调整电脑桌面的比例。
 在Java中,枚举类型可以实现接口吗?Sep 08, 2023 pm 02:17 PM
在Java中,枚举类型可以实现接口吗?Sep 08, 2023 pm 02:17 PM是的,Enum在Java中实现了一个接口,当我们需要实现一些与给定对象或类的可区分属性紧密耦合的业务逻辑时,它会很有用。枚举是Java1.5版本中添加的一种特殊数据类型。枚举是常量,默认情况下它们是静态的strong>和final,因此枚举类型字段的名称采用大写字母。示例interfaceEnumInterface{ intcalculate(intfirst,intsecond);}enumEnumClassOperatorimplementsEnu
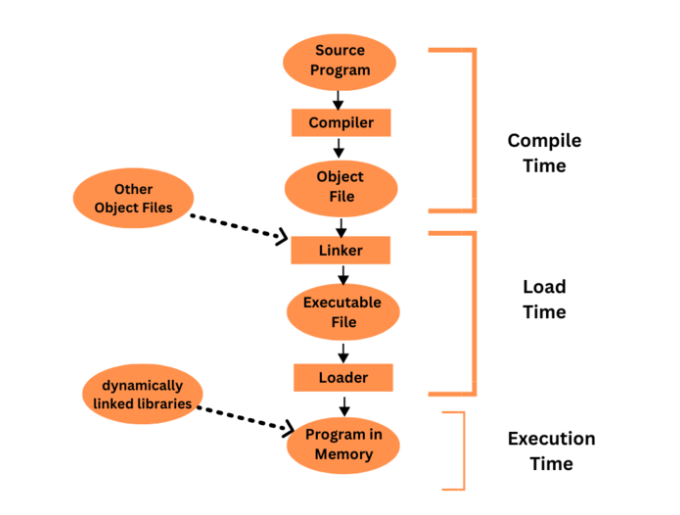 用户程序的多步处理Aug 31, 2023 pm 04:45 PM
用户程序的多步处理Aug 31, 2023 pm 04:45 PM计算机系统必须将用户的高级编程语言程序转换为机器代码,以便计算机的处理器可以运行它。多步处理是一个术语,用于描述将用户程序转换为可执行代码所涉及的多个过程。用户程序在其多步骤处理过程中通常会经历许多不同的阶段,包括词法分析、句法分析、语义分析、代码创建、优化和链接。为了将用户程序从高级形式转换为可以在计算机系统上运行的机器代码,每个阶段都是必不可少的。用户程序与操作系统或其他系统软件的组件不同,用户程序是由用户编写和运行的计算机程序。大多数时候,用户程序是用高级编程语言创建的,旨在执行特定的活动
 重复的字符,其第一次出现在最左边Aug 31, 2023 pm 06:05 PM
重复的字符,其第一次出现在最左边Aug 31, 2023 pm 06:05 PM简介在本教程中,我们将开发一种方法来查找字符串中首次出现在最左边的重复字符。这意味着该字符首先出现在字符串的开头。为了确定第一个字符是否重复,我们遍历整个字符串并将每个字符与字符串的第一个字符进行匹配。为了解决这个任务,我们使用C++编程语言的find()、length()和end()函数。示例1String=“Tutorialspoint”Output=Therepeatingcharacteris“t”在上面的示例中,输入字符串“tutorialspoint”最左边的字符是“t”,并且该字符
 Win11引导选项在哪Jun 29, 2023 pm 01:13 PM
Win11引导选项在哪Jun 29, 2023 pm 01:13 PMWin11引导选项在哪?Win11引导选项怎么设置?引导选项是开机的时候系统会在前台或者后台运行的程序,用户可以在引导选项中选择电脑系统从哪个磁盘设备启动。下面小编将为大家带来Win11引导选项的设置方法,我们一起来看看吧。 Win11引导选项设置步骤 1、使用Windows11设置菜单 按键并从菜单中Windows打开Windows设置。 选择系统设置,然后单击恢复设置。 在Advancedstartup选项中单击Restartnow。 您的系统现在将重新启动进入引导设置。
 检查一个数字是否为Munchhausen数Sep 05, 2023 pm 10:01 PM
检查一个数字是否为Munchhausen数Sep 05, 2023 pm 10:01 PM孟希豪森数是具有独特属性的奇数。如果一个数字的各位数字之和(其自身的幂)等于原始数字,则该数字被认为是明克豪森数字。这些数字并不常见,而且其中很多都不为人所知。如果使用00=0的定义,那么0也可以被认为是孟希豪森数。下面的文章提供了一种方法来确定一个数字是否是明克豪森数,同时牢记明克豪森数的这些特征。问题陈述当前的任务是检查给定的整数n是否是Münchhausen数,即当每个数字取其自己的幂并求和时,结果等于原始数。如果它是Münchhausen数,则程序应返回true,否则应返回false。示


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

SublimeText3 Linux新版
SublimeText3 Linux最新版

SublimeText3汉化版
中文版,非常好用

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

