



机器学习模型的计算效率问题,需要具体代码示例
随着人工智能的快速发展,机器学习在各个领域中得到了广泛的应用。然而,随着训练数据规模的不断增大和模型复杂度的提高,机器学习模型的计算效率问题也变得日益突出。本文将结合实际代码示例,讨论机器学习模型的计算效率问题,并提出一些解决方案。
首先,让我们来看一个简单的示例。假设我们的任务是训练一个线性回归模型来预测房价。我们有一个包含10000个样本的训练集,每个样本有1000个特征。我们可以使用如下的Python代码来实现这个线性回归模型:
import numpy as np
class LinearRegression:
def __init__(self):
self.weights = None
def train(self, X, y):
X = np.concatenate((np.ones((X.shape[0], 1)), X), axis=1)
self.weights = np.linalg.inv(X.T @ X) @ X.T @ y
def predict(self, X):
X = np.concatenate((np.ones((X.shape[0], 1)), X), axis=1)
return X @ self.weights
# 生成训练数据
X_train = np.random.randn(10000, 1000)
y_train = np.random.randn(10000)
# 创建并训练线性回归模型
model = LinearRegression()
model.train(X_train, y_train)
# 使用模型进行预测
X_test = np.random.randn(1000, 1000)
y_pred = model.predict(X_test)以上是一个简单的线性回归模型的实现,但是当我们尝试在较大的数据集上进行训练时,计算时间会非常长。这是因为在每一次迭代中,我们都需要计算 X.T @ X,然后通过求逆运算来计算权重。这些操作的时间复杂度都较高,导致计算效率下降。
为了解决计算效率问题,我们可以采用以下几种方法:
- 特征选择:考虑到某些特征对目标变量的相关性较小,我们可以通过特征选择的方法减少特征的维度,从而降低计算量。常用的特征选择方法包括方差选择法、卡方检验等。
- 特征降维:当特征维度非常高时,可以考虑使用主成分分析(PCA)等降维方法将高维特征映射到低维空间,以减少计算量。
- 矩阵分解:可以使用矩阵分解的方法来替代求逆运算,例如使用奇异值分解(SVD)代替矩阵求逆运算。
- 并行计算:对于大规模数据集和复杂模型,可以考虑使用并行计算的方式来加速训练过程。例如使用并行编程框架(如OpenMP、CUDA等)来利用多核CPU或GPU进行并行计算。
以上是一些常见的解决机器学习模型计算效率问题的方法,但需要根据具体情况选择合适的方法。在实际应用中,我们可以根据数据集的大小、模型的复杂度以及系统资源的情况来选择合适的解决方案。
总结起来,机器学习模型的计算效率问题是一个需要重视并且需要解决的问题。通过合理选择特征、降低特征维度、使用矩阵分解和并行计算等方法,我们可以显著提高机器学习模型的计算效率,从而加速训练过程。在实际应用中,我们可以根据具体情况选择合适的方法来提高计算效率,并在算法的实现中结合以上方法,以便更好地应用机器学习模型于各个领域。
以上是机器学习模型的计算效率问题的详细内容。更多信息请关注PHP中文网其他相关文章!

 如何解决 VS Code 中 IntelliSense 不起作用的问题Apr 21, 2023 pm 07:31 PM
如何解决 VS Code 中 IntelliSense 不起作用的问题Apr 21, 2023 pm 07:31 PM最常称为VSCode的VisualStudioCode是开发人员用于编码的工具之一。Intellisense是VSCode中包含的一项功能,可让编码人员的生活变得轻松。它提供了编写代码的建议或工具提示。这是开发人员更喜欢的一种扩展。当IntelliSense不起作用时,习惯了它的人会发现很难编码。你是其中之一吗?如果是这样,请通过本文找到不同的解决方案来解决IntelliSense在VS代码中不起作用的问题。Intellisense如下所示。它在您编码时提供建议。首先检
 解决C++代码中出现的“error: redefinition of class 'ClassName'”问题Aug 25, 2023 pm 06:01 PM
解决C++代码中出现的“error: redefinition of class 'ClassName'”问题Aug 25, 2023 pm 06:01 PM解决C++代码中出现的“error:redefinitionofclass'ClassName'”问题在C++编程中,我们经常会遇到各种各样的编译错误。其中一个常见的错误是“error:redefinitionofclass'ClassName'”(类‘ClassName’的重定义错误)。这个错误通常出现在同一个类被定义了多次的情况下。本文将
 机器学习模型的泛化能力问题Oct 08, 2023 am 10:46 AM
机器学习模型的泛化能力问题Oct 08, 2023 am 10:46 AM机器学习模型的泛化能力问题,需要具体代码示例随着机器学习的发展和应用越来越广泛,人们越来越关注机器学习模型的泛化能力问题。泛化能力指的是机器学习模型对未标记数据的预测能力,也可以理解为模型在真实世界中的适应能力。一个好的机器学习模型应该具有较高的泛化能力,能够对新的数据做出准确的预测。然而,在实际应用中,我们经常会遇到模型在训练集上表现良好,但在测试集或真实
 解决PHP报错:继承父类时遇到的问题Aug 17, 2023 pm 01:33 PM
解决PHP报错:继承父类时遇到的问题Aug 17, 2023 pm 01:33 PM解决PHP报错:继承父类时遇到的问题在PHP中,继承是一种重要的面向对象编程的特性。通过继承,我们能够重用已有的代码,并且能够在不修改原有代码的情况下,对其进行扩展和改进。尽管继承在开发中应用广泛,但有时候在继承父类时可能会遇到一些报错问题,本文将围绕解决继承父类时遇到的常见问题进行讨论,并提供相应的代码示例。问题一:未找到父类在继承父类的过程中,如果系统无
 强化学习中的奖励设计问题Oct 08, 2023 pm 01:09 PM
强化学习中的奖励设计问题Oct 08, 2023 pm 01:09 PM强化学习中的奖励设计问题,需要具体代码示例强化学习是一种机器学习的方法,其目标是通过与环境的交互来学习如何做出能够最大化累积奖励的行动。在强化学习中,奖励起着至关重要的作用,它是代理人(Agent)学习过程中的信号,用于指导其行为。然而,奖励设计是一个具有挑战性的问题,合理的奖励设计可以极大地影响到强化学习算法的性能。在强化学习中,奖励可以被视为代理人与环境
 win10浏览器自动关闭是怎么回事Jul 02, 2023 pm 08:09 PM
win10浏览器自动关闭是怎么回事Jul 02, 2023 pm 08:09 PMwin10浏览器自动关闭是怎么回事?我们在使用电脑的时候经常会去用到各种浏览器,而最近有不少用户在Win10电脑中使用浏览器的时候经常会出现自动关闭的情况,那么我们要是遇到这种问题应该怎么解决呢?很多小伙伴不知道怎么详细操作,小编下面整理了Win10系统浏览器自动关闭的解决教程,如果你感兴趣的话,跟着小编一起往下看看吧! Win10系统浏览器自动关闭的解决教程 1、针对浏览器崩溃的问题,可以借助电脑管家所提供的电脑诊所工具进行修复操作。只需要在其中搜索IE浏览器崩溃并点击如图所示立即修复
 弱监督学习中的标签获取问题Oct 08, 2023 am 09:18 AM
弱监督学习中的标签获取问题Oct 08, 2023 am 09:18 AM弱监督学习中的标签获取问题,需要具体代码示例引言:弱监督学习是一种利用弱标签进行训练的机器学习方法。与传统的监督学习不同,弱监督学习只需利用较少的标签来训练模型,而不是每个样本都需要有准确的标签。然而,在弱监督学习中,如何从弱标签中准确地获取有用的信息是一个关键问题。本文将介绍弱监督学习中的标签获取问题,并给出具体的代码示例。弱监督学习中的标签获取问题简介:
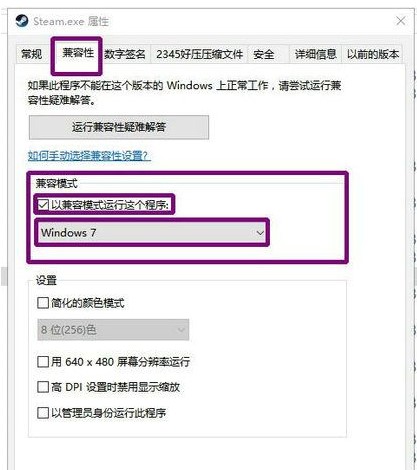 win10下载不了steam怎么办Jul 07, 2023 pm 01:37 PM
win10下载不了steam怎么办Jul 07, 2023 pm 01:37 PMSteam是十分受欢迎的一个平台游戏,拥有众多优质游戏,可是有些win10用户体现自己下载不了steam,这是怎么回事呢?极有可能是用户的ipv4服务器地址没有设置好。要想解决这个问题的话,你可以试着在兼容模式下安装Steam,随后手动修改一下DNS服务器,将其改成114.114.114.114,以后应当就能下载了。win10下载不了steam怎么办:WIn10下能够试着兼容模式下安装,更新后必须关掉兼容模式,不然网页将无法加载。点击程序安装的属性,以兼容模式运作运行这个程序。重启以增加内存,电


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

SublimeText3 Linux新版
SublimeText3 Linux最新版

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

WebStorm Mac版
好用的JavaScript开发工具

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

