



如何使用Python for NLP将PDF文本转换为可编辑的格式?
在进行自然语言处理(NLP)的过程中,经常会遇到需要从PDF文本中提取信息的需求,但是由于PDF文本通常是不可编辑的,这给NLP的处理带来了一定的困扰。幸运的是,使用Python的一些强大的库,我们可以轻松地将PDF文本转换为可编辑的格式,并进一步进行处理。本文将介绍如何使用Python中的PyPDF2和pdf2docx库来实现这一目标。
首先,我们需要安装所需的库。使用以下命令来安装PyPDF2和pdf2docx库:
pip install PyPDF2 pip install pdf2docx
安装完成后,我们可以开始编写代码。首先,我们需要导入所需的库:
import PyPDF2 from pdf2docx import Converter
接下来,我们需要创建一个函数来提取PDF文本。下面是一个示例函数的代码:
def extract_text_from_pdf(file_path):
with open(file_path, 'rb') as file:
pdf_reader = PyPDF2.PdfReader(file)
num_pages = len(pdf_reader.pages)
text = ""
for page_num in range(num_pages):
page = pdf_reader.pages[page_num]
text += page.extract_text()
return text在这个函数中,我们首先打开PDF文件并创建一个PdfReader对象。然后,我们使用pages方法获取PDF中的所有页面,并使用extract_text方法提取每个页面的文本。最后,我们将所有提取的文本拼接在一起并返回。pages方法获取PDF中的所有页面,并使用extract_text方法提取每个页面的文本。最后,我们将所有提取的文本拼接在一起并返回。
接下来,我们需要创建一个函数来将提取的文本转换为可编辑的格式(例如docx)。下面是一个示例函数的代码:
def convert_to_docx(file_path):
output_file_path = file_path.replace('.pdf', '.docx')
cv = Converter(file_path)
cv.convert(output_file_path)
cv.close()
return output_file_path在这个函数中,我们首先定义了输出文件的路径,这里我们将其与PDF文件的路径结合来创建一个新的文件。然后,我们使用pdf2docx库的Converter类来将提取的文本转换为docx格式。最后,我们关闭转换器,并返回输出文件的路径。
使用上述函数,我们可以将整个流程封装到一个主函数中:
def main():
pdf_file_path = 'path-to-pdf-file.pdf'
text = extract_text_from_pdf(pdf_file_path)
docx_file_path = convert_to_docx(pdf_file_path)
print("Extracted text:")
print(text)
print("Converted docx file path:")
print(docx_file_path)
if __name__ == "__main__":
main()在这个主函数中,我们首先定义了PDF文件的路径,然后调用extract_text_from_pdf函数来提取PDF文本。接着,我们调用convert_to_docx
rrreee
在这个函数中,我们首先定义了输出文件的路径,这里我们将其与PDF文件的路径结合来创建一个新的文件。然后,我们使用pdf2docx库的Converter类来将提取的文本转换为docx格式。最后,我们关闭转换器,并返回输出文件的路径。🎜🎜使用上述函数,我们可以将整个流程封装到一个主函数中:🎜rrreee🎜在这个主函数中,我们首先定义了PDF文件的路径,然后调用extract_text_from_pdf函数来提取PDF文本。接着,我们调用convert_to_docx函数将提取的文本转换为docx格式,并将转换后的文件路径打印出来。🎜🎜使用以上代码,我们可以轻松地将PDF文本转换为可编辑的格式。通过进一步对转换后的文本进行处理,我们可以进行更多的NLP任务,例如词频统计、关键词提取等。希望这篇文章对你理解如何使用Python for NLP将PDF文本转换为可编辑的格式有所帮助!🎜以上是如何使用Python for NLP将PDF文本转换为可编辑的格式?的详细内容。更多信息请关注PHP中文网其他相关文章!

 如何利用Python for NLP将PDF文件中的文本进行翻译?Sep 28, 2023 pm 01:13 PM
如何利用Python for NLP将PDF文件中的文本进行翻译?Sep 28, 2023 pm 01:13 PM如何利用PythonforNLP将PDF文件中的文本进行翻译?随着全球化的进程日益加深,跨语言翻译的需求也越来越大。而PDF文件作为一种常见的文档形式,其中可能包含了大量的文本信息。如果我们想将PDF文件中的文字内容进行翻译,可以运用Python的自然语言处理(NLP)技术来实现。本文将介绍一种利用PythonforNLP进行PDF文本翻译的方法,并
 如何利用Python for NLP处理PDF文件中的表格数据?Sep 27, 2023 pm 03:04 PM
如何利用Python for NLP处理PDF文件中的表格数据?Sep 27, 2023 pm 03:04 PM如何利用PythonforNLP处理PDF文件中的表格数据?摘要:自然语言处理(NaturalLanguageProcessing,简称NLP)是一个涉及计算机科学和人工智能领域的重要领域,而处理PDF文件中的表格数据是NLP中一个常见的任务。本文将介绍如何使用Python和一些常用的库来处理PDF文件中的表格数据,包括提取表格数据、数据预处理和转换
 详细讲解Python之Seaborn(数据可视化)Apr 21, 2022 pm 06:08 PM
详细讲解Python之Seaborn(数据可视化)Apr 21, 2022 pm 06:08 PM本篇文章给大家带来了关于Python的相关知识,其中主要介绍了关于Seaborn的相关问题,包括了数据可视化处理的散点图、折线图、条形图等等内容,下面一起来看一下,希望对大家有帮助。
 Python for NLP:如何处理包含多个章节的PDF文件?Sep 27, 2023 pm 08:55 PM
Python for NLP:如何处理包含多个章节的PDF文件?Sep 27, 2023 pm 08:55 PMPythonforNLP:如何处理包含多个章节的PDF文件?在自然语言处理(NLP)任务中,我们常常需要处理包含多个章节的PDF文件。这些文件往往是学术论文、小说、技术手册等,每个章节都有其特定的格式和内容。本文将介绍如何使用Python处理这类PDF文件,并提供具体的代码示例。首先,我们需要安装一些Python库来帮助我们处理PDF文件。其中最常用的是
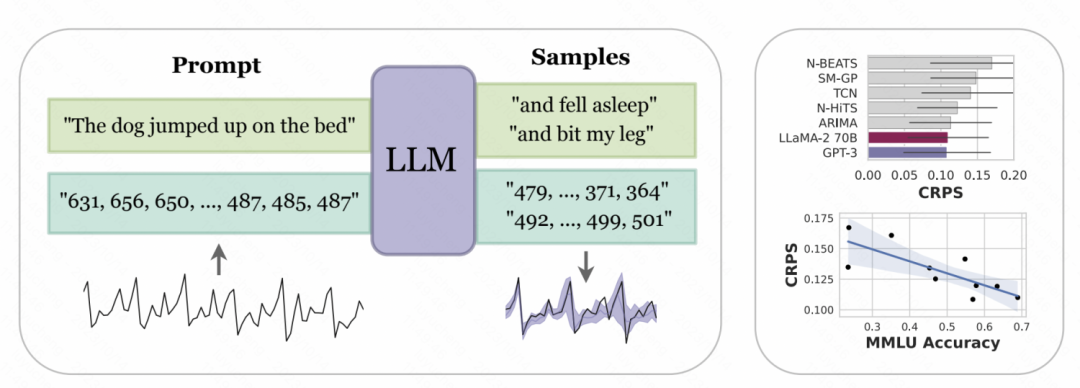 一篇学会大模型浪潮下的时间序列预测Nov 06, 2023 am 08:13 AM
一篇学会大模型浪潮下的时间序列预测Nov 06, 2023 am 08:13 AM今天跟大家聊一聊大模型在时间序列预测中的应用。随着大模型在NLP领域的发展,越来越多的工作尝试将大模型应用到时间序列预测领域中。这篇文章介绍了大模型应用到时间序列预测的主要方法,并汇总了近期相关的一些工作,帮助大家理解大模型时代时间序列预测的研究方法。1、大模型时间序列预测方法最近三个月涌现了很多大模型做时间序列预测的工作,基本可以分为2种类型。重写后的内容:一种方法是直接使用NLP的大型模型进行时间序列预测。在这种方法中,使用GPT、Llama等NLP大型模型来进行时间序列预测,关键在于如何将
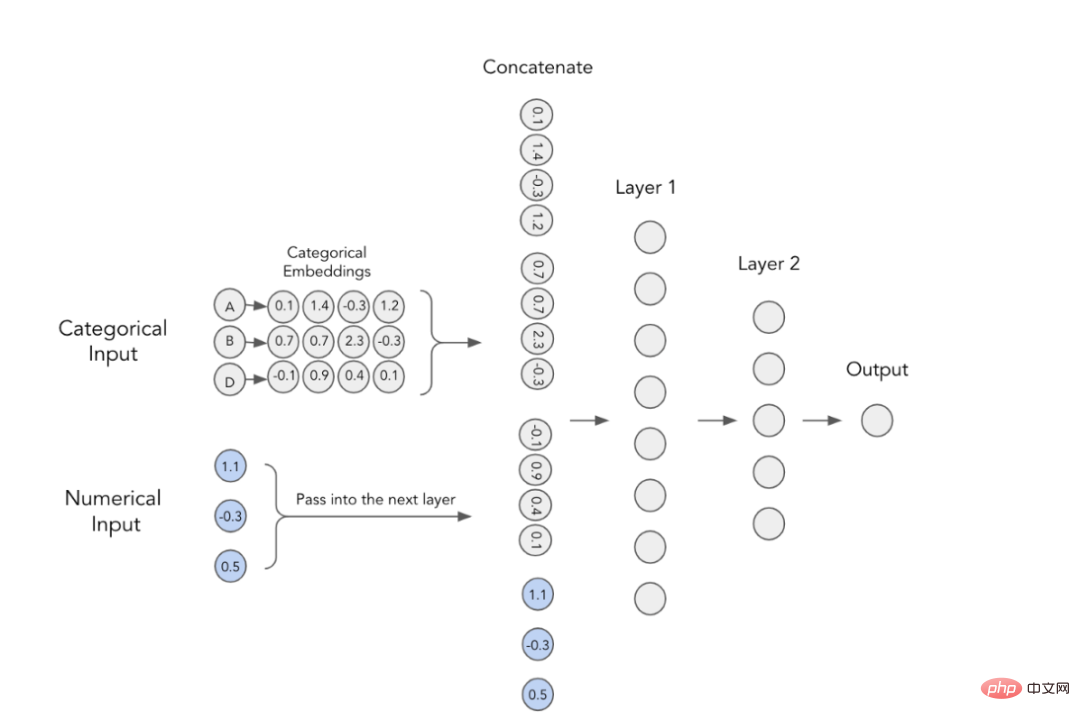 TabTransformer转换器提升多层感知机性能深度解析Apr 17, 2023 pm 03:25 PM
TabTransformer转换器提升多层感知机性能深度解析Apr 17, 2023 pm 03:25 PM如今,转换器(Transformers)成为大多数先进的自然语言处理(NLP)和计算机视觉(CV)体系结构中的关键模块。然而,表格式数据领域仍然主要以梯度提升决策树(GBDT)算法为主导。于是,有人试图弥合这一差距。其中,第一篇基于转换器的表格数据建模论文是由Huang等人于2020年发表的论文《TabTransformer:使用上下文嵌入的表格数据建模》。本文旨在提供该论文内容的基本展示,同时将深入探讨TabTransformer模型的实现细节,并向您展示如何针对我们自己的数据来具体使用Ta
 分享10款高效的VSCode插件,总有一款能够惊艳到你!!Mar 09, 2021 am 10:15 AM
分享10款高效的VSCode插件,总有一款能够惊艳到你!!Mar 09, 2021 am 10:15 AMVS Code的确是一款非常热门、有强大用户基础的一款开发工具。本文给大家介绍一下10款高效、好用的插件,能够让原本单薄的VS Code如虎添翼,开发效率顿时提升到一个新的阶段。
 Python for NLP:如何从PDF文件中提取并分析脚注和尾注?Sep 28, 2023 am 11:45 AM
Python for NLP:如何从PDF文件中提取并分析脚注和尾注?Sep 28, 2023 am 11:45 AMPythonforNLP:如何从PDF文件中提取并分析脚注和尾注引言:自然语言处理(NLP)是计算机科学和人工智能领域中的一个重要研究方向。PDF文件作为一种常见的文档格式,在实际应用中经常遇到。本文介绍如何使用Python从PDF文件中提取并分析脚注和尾注,为NLP任务提供更全面的文本信息。文章将结合具体的代码示例进行介绍。一、安装和导入相关库要实现从


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

Dreamweaver CS6
视觉化网页开发工具

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

记事本++7.3.1
好用且免费的代码编辑器

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

