
智源开放3亿条语义向量模型训练数据,BGE模型持续进行迭代更新

- 王林转载
- 2023-09-21 21:33:111713浏览
随着大型模型的开发和应用火热发展,作为大型模型核心基础组件的Embedding的重要性变得越来越突出。智源公司在一个月前发布的开源可商用的中英文语义向量模型BGE(BAAI General Embedding)在社区中引起了广泛的关注,Hugging Face平台上的下载量已经达到了数十万次。目前,BGE已经快速迭代推出了1.5版本,并公布了多项更新。其中,BGE首次开源了三亿条大规模训练数据,为社区提供了训练类似模型的帮助,推动了该领域技术的发展
- MTP数据集链接:https://data.baai.ac.cn/details/BAAI-MTP
- BGE 模型链接:https://huggingface.co/BAAI
- BGE 代码仓库:https://www.php.cn/link/8944871f1c9865a77a3d9c92cadf124d
3 亿中英向量模型训练数据开放
首次开源的业界语义向量模型训练数据达到了3亿条中英文数据
BGE 的出色能力很大程度上源于其大规模、多样化的训练数据。此前,业界同行鲜有发布同类数据集。在本次更新中,智源首次将 BGE 的训练数据向社区予以开放,为推动此类技术进一步发展打下了基础。
此次发布的数据集 MTP 由总计 3 亿条中英文关联文本对构成。其中,中文记录达 1 亿条,英文数据达 2 亿条。数据的来源包括 Wudao Corpora、Pile、DuReader、Sentence Transformer 等语料。经过必要的采样、抽取和清洗后获得
详细细节请参考 Data Hub:https://data.baai.ac.cn
MTP 为迄今开源的最大规模中英文关联文本对数据集,为训练中英文语义向量模型提供重要基础。
响应开发者社区,BGE 功能升级
根据社区反馈,BGE 在其 1.0 版本的基础上进行了进一步优化,使其表现更加稳定和出色。具体的升级内容如下:
- 模型更新。BGE-*-zh-v1.5 缓解了相似度分布问题,通过对训练数据进行过滤,删除低质量数据,提高训练时温度系数 temperature 至 0.02,使得相似度数值更加平稳 。
- 新增模型。开源 BGE-reranker 交叉编码器模型,可更加精准找到相关文本,支持中英双语。不同于向量模型需要输出向量,BGE-reranker 直接文本对输出相似度,排序准确度更高,可用于对向量召回结果的重新排序,提升最终结果的相关性。
- 新增功能。BGE1.1 增加难负样本挖掘脚本,难负样本可有效提升微调后检索的效果;在微调代码中增加在微调中增加指令的功能;模型保存也将自动转成 sentence transformer 格式,更方便模型加载。
值得一提的是,日前,智源联合 Hugging Face 发布了一篇技术报告,报告提出用 C-Pack 增强中文通用语义向量模型。
《C-Pack: Packaged Resources To Advance General Chinese Embedding》
链接:https://arxiv.org/pdf/2309.07597.pdf
在开发者社区收获高热度
BGE 自发布以来受到了大型模型开发者社区的关注,目前 Hugging Face 的下载量已经达到了数十万次,并且已经被知名的开源项目 LangChain、LangChain-Chatchat、llama_index 等集成使用
Langchain 官方、LangChain 联合创始人兼首席执行官 Harrison Chase、Deep trading 创始人 Yam Peleg 等社区大 V 对 BGE 表示关注。
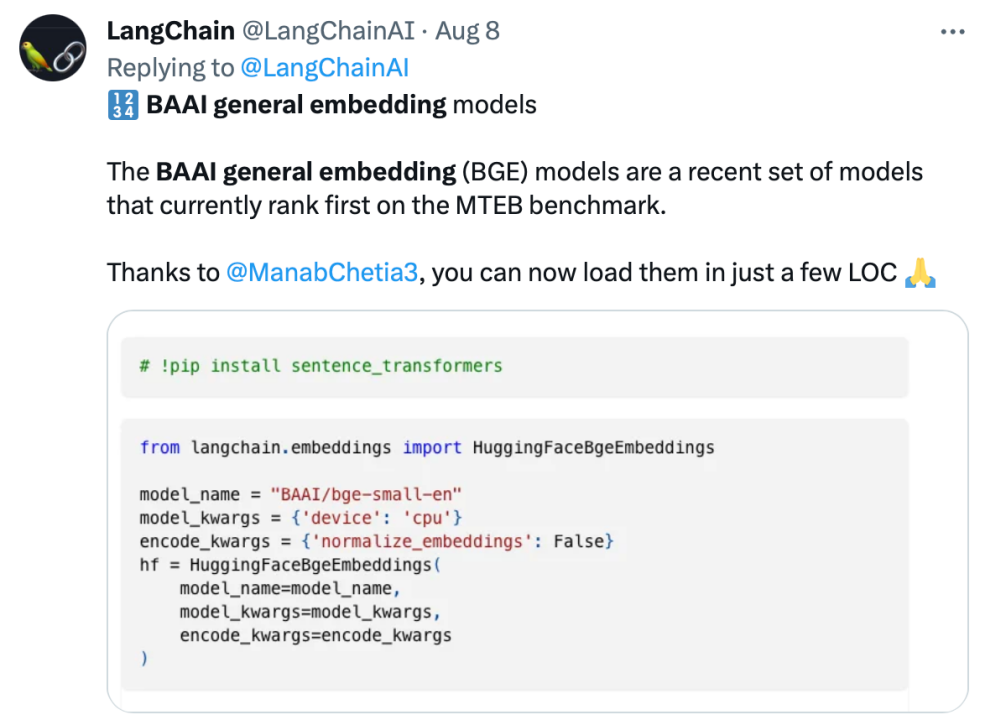
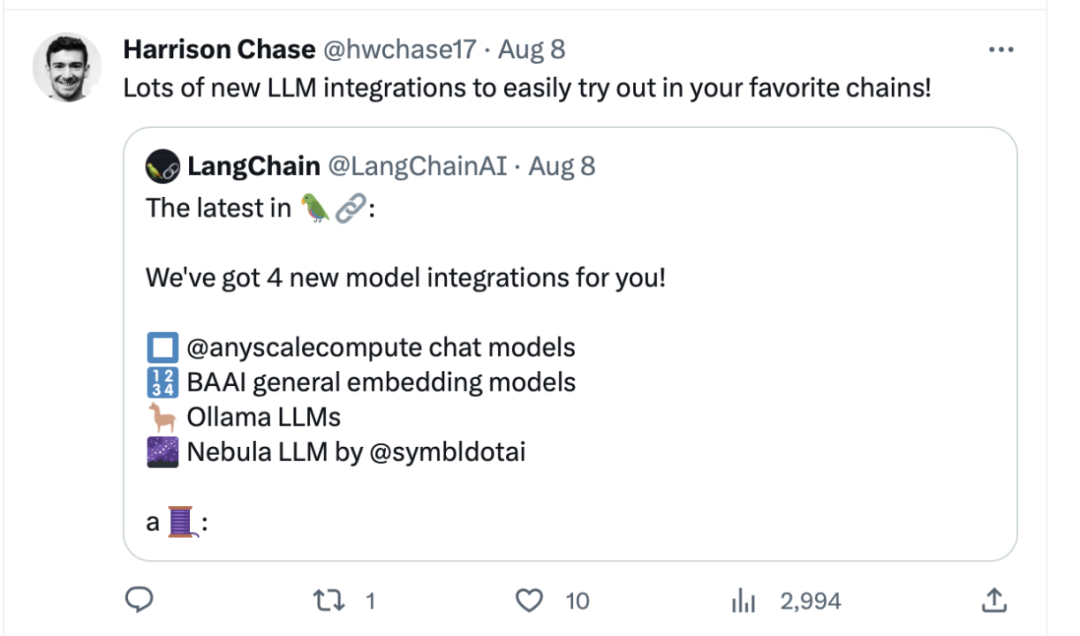
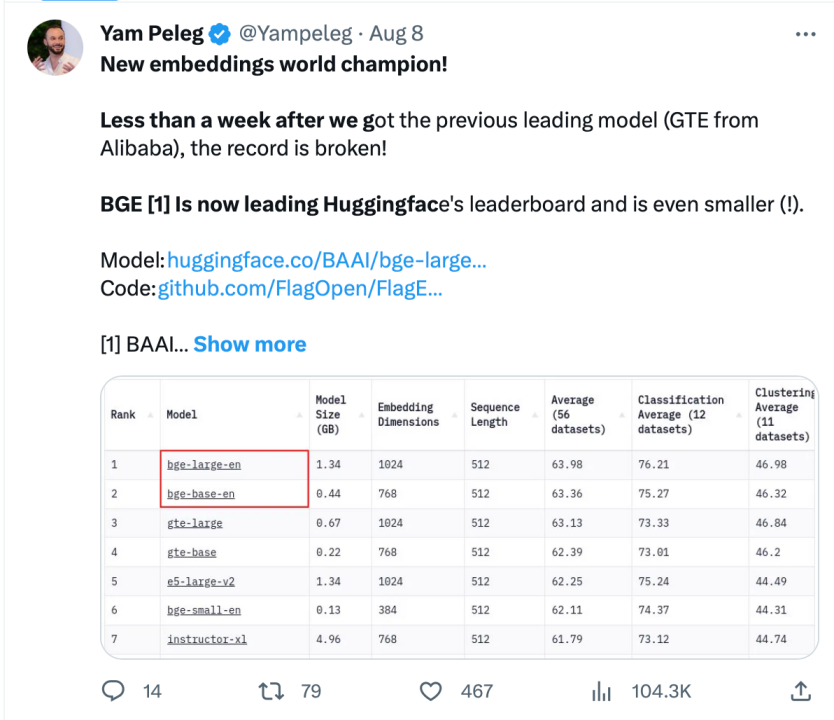
坚持开源开放,促进协同创新,智源大模型技术开体系 FlagOpen BGE 新增 FlagEmbedding 新版块,专注于 Embedding 技术和模型,BGE 是其中备受瞩目的开源项目之一。FlagOpen 致力于构建大模型时代的人工智能技术基础设施,未来将继续向学术界和产业界开放更完整的大模型全栈技术
以上是智源开放3亿条语义向量模型训练数据,BGE模型持续进行迭代更新的详细内容。更多信息请关注PHP中文网其他相关文章!