
不用4个H100!340亿参数Code Llama在Mac可跑,每秒20个token,代码生成最拿手

- PHPz转载
- 2023-09-19 13:05:011030浏览
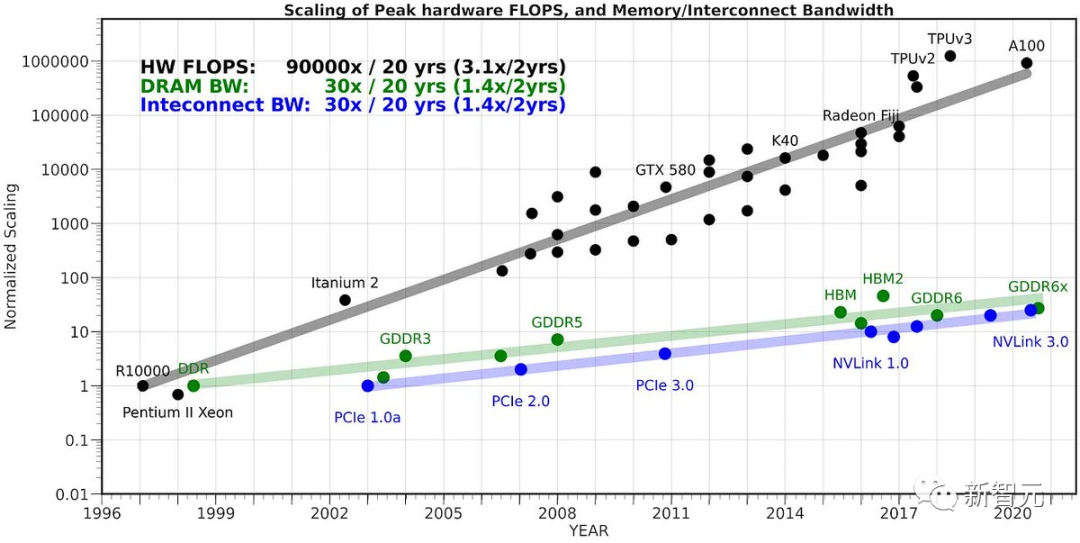
开源社区的一位开发者Georgi Gerganov发现,自己可以在M2 Ultra上运行全F16精度的34B Code Llama模型,而且推理速度超过了20 token/s。
M2 Ultra的带宽达到了800GB/s,这在其他人通常需要使用4个高端GPU才能实现的情况下
而这背后真正的答案是:投机采样(Speculative Sampling)。
乔治的发现立刻引发了人工智能界大佬们的讨论
Karpathy转发评论道,「LLM的投机执行是一种出色的推理时间优化」。

「投机采样」加速推理
在这个例子中,Georgi借助Q4 7B quantum草稿模型(也就是Code Llama 7B)进行了投机解码,然后在M2 Ultra上使用Code Llama34B进行生成。
简单讲,就是用一个「小模型」做草稿,然后用「大模型」来检查修正,以此加速整个过程。

GitHub地址:https://twitter.com/ggerganov/status/1697262700165013689
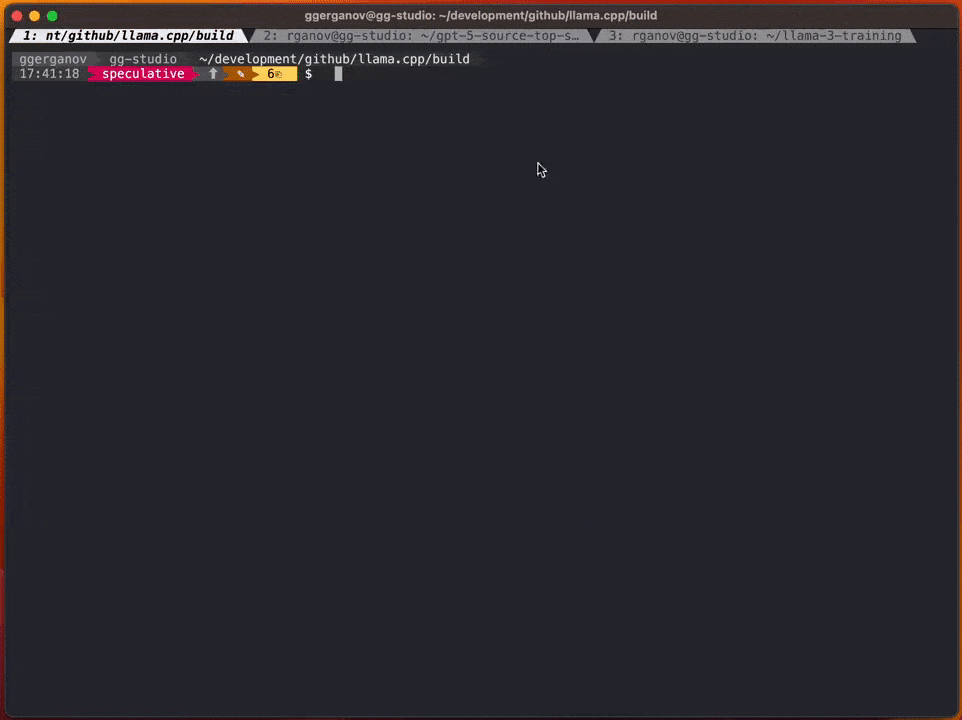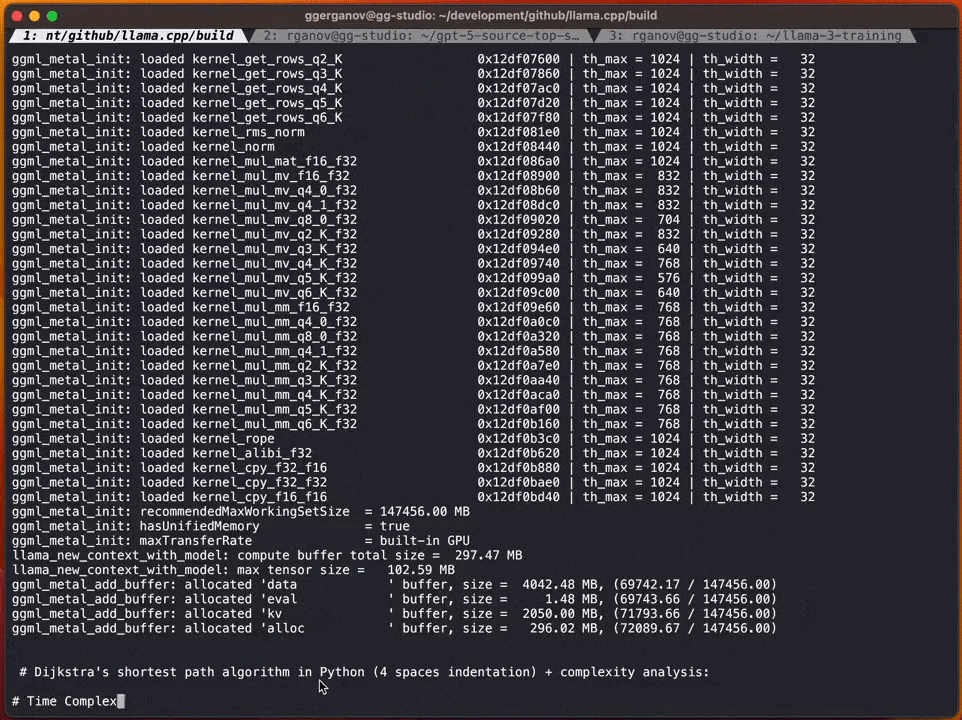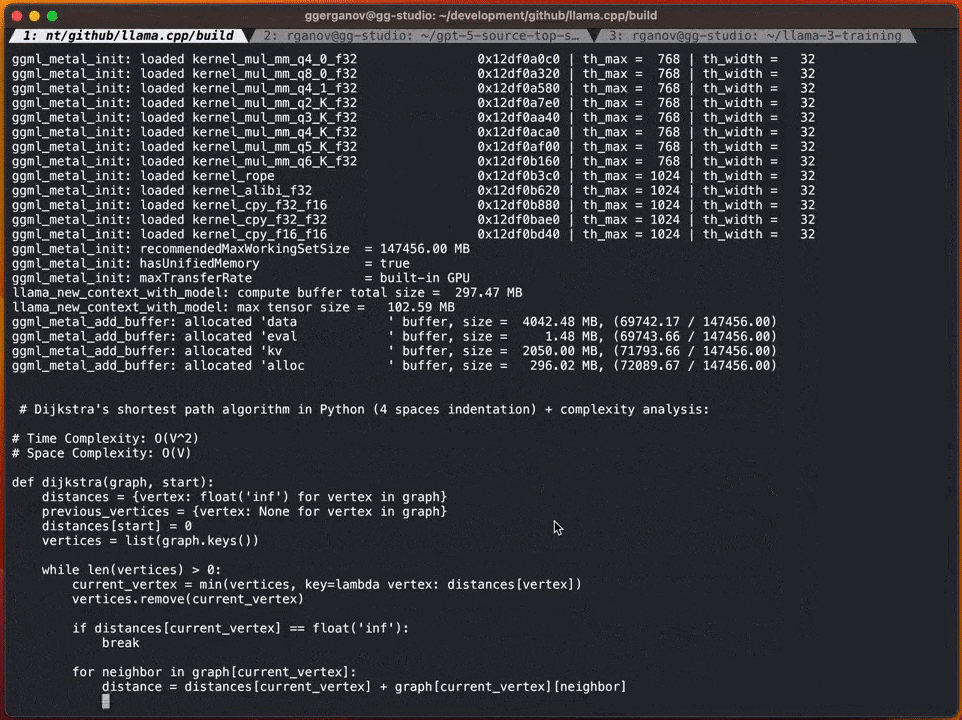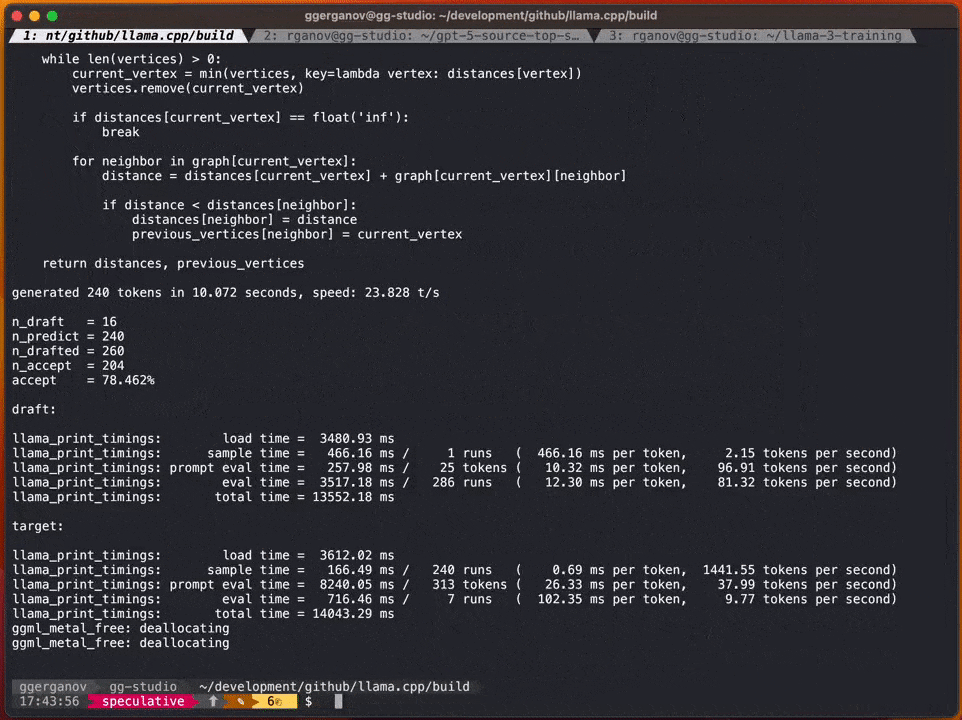
根据Georgi的介绍,这些模型的速度分别如下:
F16 34B:每秒约10个令牌
需要进行改写的内容是:Q4 7B:每秒约80个令牌
以下是一个没有使用投机采样的标准F16采样示例:
在加入投机采样策略之后,速度可以达到每秒约20个标记
根据Georgi的说法,生成内容的速度可能会有所不同。然而,这种方法在代码生成方面似乎非常有效,因为大多数词库都能被草稿模型正确猜测
使用「语法采样」的用例也有可能从中受益匪浅

投机采样是如何实现快速推理的?
Karpathy根据此前谷歌大脑、UC伯克利、DeepMind的三项研究,做出了解释。

请点击以下链接查看论文:https://arxiv.org/pdf/2211.17192.pdf

论文地址:https://arxiv.org/pdf/1811.03115.pdf

论文地址:https://arxiv.org/pdf/2302.01318.pdf
这取决于以下不直观的观察结果:
在单个输入token上转发LLM所需的时间,与在K个输入token上批量转发LLM所需的时间相同(K比你想象的要大)。
这个不直观的事实是因为采样受到内存的严重限制,大部分「工作」不计算,而是将Transformer的权重从VRAM读取到芯片上缓存中进行处理。

为了完成读取所有权重的任务,最好将它们应用于整个批量的输入向量
我们之所以不能天真地利用这一事实,来一次采样K个token,是因为每N个token都取决于,我们在第N-1步时采样的token。这是一种串行依赖关系,因此基线实现只是从左到右逐个进行。
现在,一个巧妙的想法是使用一个小而廉价的草稿模型,首先生成一个由K个标记组成的候选序列——「草稿」。然后,我们将所有这些信息一起批量送入大模型
根据上述方法,这与只输入一个token的速度几乎一样快。
然后,我们从左到右检查模型,以及样本token预测的logits。任何与草稿一致的样本都允许我们立即跳转到下一个token。
如果存在分歧,我们将放弃草稿模型,并承担进行一些一次性工作的成本(对草稿模型进行采样,并对后续的标记进行前向传递)
这在实践中行之有效的原因是,大多数情况下,draft token都会被接受,因为是简单的token,所以即使是更小的草稿模型也能接受它们。
当这些简单的token被接受时,我们就会跳过这些部分。大模型不同意的困难token会「回落」到原始速度,但实际上因为有额外的工作会慢一些。
所以,总而言之:这一怪招之所以管用,是因为LLM在推理时是受内存限制。在「批大小为1」的情况下,对感兴趣的单个序列进行采样,而大部分「本地 LLM」用例都属于这种情况。而且,大多数token都很「简单」。
HuggingFace的联合创始人表示,340亿参数的模型在一年半以前的数据中心之外,看起来非常庞大和难以管理。现在只需使用笔记本电脑就可以轻松处理了

现在的LLM并不是单点突破,而是需要多个重要组件有效协同工作的系统。投机解码就是一个很好的例子,可以帮助我们从系统的角度进行思考。
以上是不用4个H100!340亿参数Code Llama在Mac可跑,每秒20个token,代码生成最拿手的详细内容。更多信息请关注PHP中文网其他相关文章!