
小米公司:声音识别算法国际性能排名第一,音频标记任务取得重要进展

- 王林转载
- 2023-09-19 11:53:091600浏览
本站 9 月 13 日消息,小米公司今日发布消息,小米自研声音识别算法在音频标记(Audio Tagging)任务中取得重要进展。
据介绍,以公开数据集 AudioSet-2M 的音频数据作为训练集的音频标记模型,首次突破 50 mAP 的分数,此项突破标志着小米声音识别算法已在国际上性能排名第一。

小米公司表示:“未来我们将不断探索科技新高度,在手机、音箱、手环、CyberDog 等丰富的设备使用场景中,给用户带来更高效更准确的声音识别体验。”
正如本站此前报道,小米目前在 AI 大模型方面也有发力,并结合小爱同学进一步拓展用户覆盖范围。结合声音识别算法的进步,小爱同学有望迎来更好的体验。
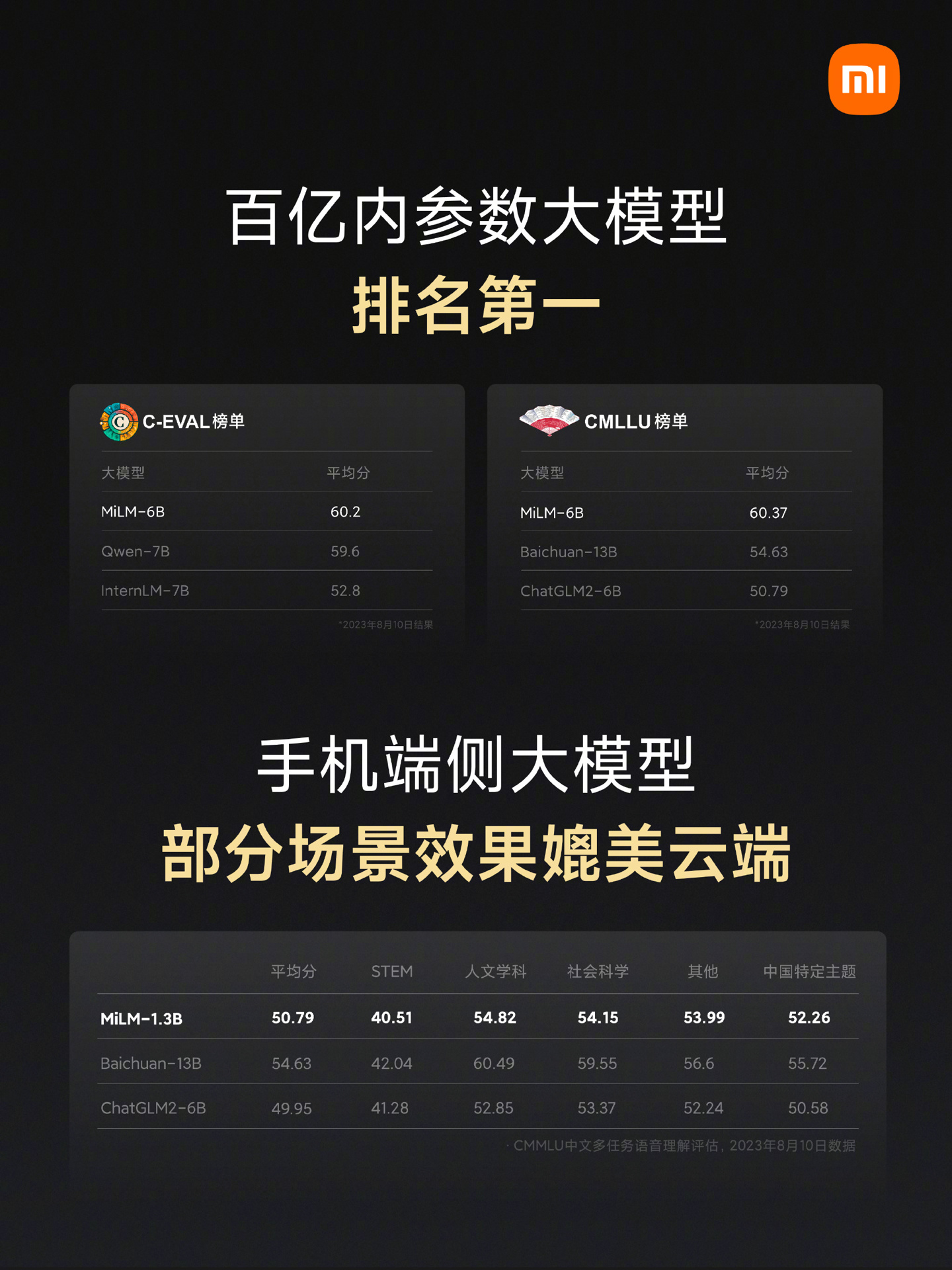
雷军在此前的年度演讲中透露称,在 AI 方面,小米从 2016 年 7 月起就开始布局,今年 4 月成立大模型团队,相关团队超过 3000 人。小米 AI 大模型最新一个 13 亿参数大模型已经成功在手机本地跑通,部分场景可以媲美 60 亿参数模型在云端运行结果。
广告声明:文内含有的对外跳转链接(包括不限于超链接、二维码、口令等形式),用于传递更多信息,节省甄选时间,结果仅供参考,本站所有文章均包含本声明。
以上是小米公司:声音识别算法国际性能排名第一,音频标记任务取得重要进展的详细内容。更多信息请关注PHP中文网其他相关文章!
声明:
本文转载于:ithome.com。如有侵权,请联系admin@php.cn删除