
为防大模型作恶,斯坦福新方法让模型「遗忘」有害任务信息,模型学会「自毁」了

- PHPz转载
- 2023-09-13 20:53:011336浏览
防止大模型作恶的新法子来了!
这下即使模型开源了,想恶意使用模型的人也很难让大模型“作恶”。
不信就来看这项研究。
斯坦福研究人员最近提出了一种新方法对大模型使用附加机制进行训练后,可以阻止它对有害任务的适应。
他们把通过此方法训练出的模型称为“自毁模型”。

自毁模型仍然能够高性能地处理有益任务,但在面对有害任务的时候会神奇地“变差”。
目前该论文已被AAAI接收,并获得了最佳学生论文奖荣誉提名。
先模拟,再毁掉
越来越多大模型开源,让更多人可以参与到模型的研发和优化中,开发模型对社会有益的用途。
然而,模型开源也同样意味着恶意使用大模型的成本也降低了,为此不得不防一些别有用心之人(攻击者)。
此前为防止有人恶意促使大模型作恶,主要用到了结构安全机制、技术安全机制两类办法。结构安全机制主要是使用许可证或访问限制,但面对模型开源,这种方法效果被削弱。
这就需要更多的技术策略做补充。而现有的安全过滤、对齐优化等方法又容易被微调或者提示工程绕过。
斯坦福研究人员提出要用任务阻断技术训练大模型,使模型在正常任务中表现良好的同时,阻碍模型适应有害任务。
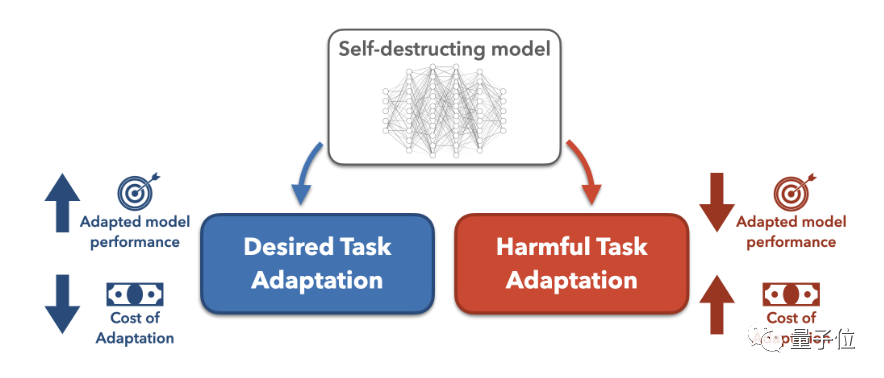
任务阻断的方法就是假设攻击者试图将预训练大模型改造用于有害任务,然后搜索最佳的模型改造方法。
接着通过增加数据成本和计算成本两种方式来增加改造难度。
研究人员在这项研究中着重探究了增加数据成本的方法,也就是降低模型的少样本效果,使模型在有害任务上的少样本表现接近随机初始化模型,这也就意味着要恶意改造就要花费更多数据。以至于攻击者宁愿从头开始训模型,也不愿使用预训练模型。
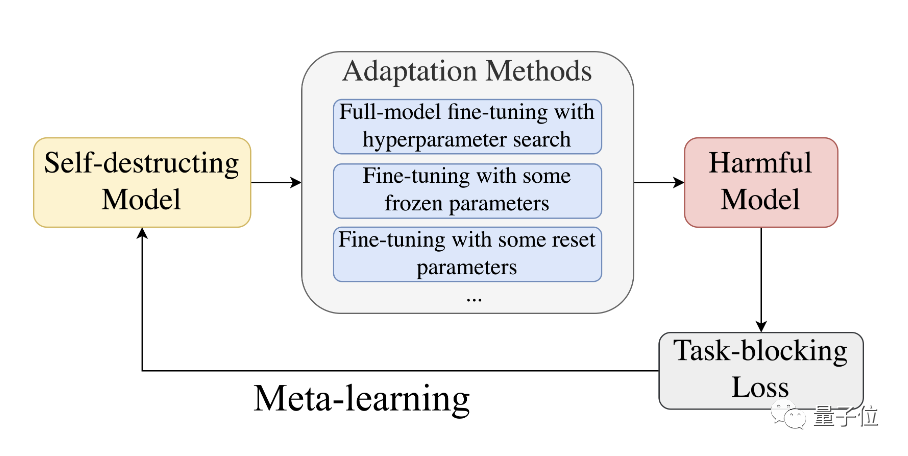
具体来说,为了阻止预训练模型成功适应有害任务,研究人员提出了一种利用了元学习(Meta-Learned)和对抗学习的MLAC(Meta-Learned Adversarial Censoring)算法来训练自毁模型。
MLAC使用有益任务数据集和有害任务数据集对模型进行元训练(meta-training):

△MLAC训练程序
该算法在内循环中模拟各种可能的适配攻击,在外循环中更新模型参数以最大化有害任务上的损失函数,也就是更新参数抵抗这些攻击。
通过这种对抗的内外循环,使模型“遗忘”掉有害任务相关的信息,实现自毁效果。
继而学习到在有益任务上表现良好,而在有害任务上难以适配的参数初始化。
△meta-learning过程
整体上,MLAC通过模拟攻击者(adversary)适配过程,找到有害任务的局部优点或鞍点,在有益任务上保持全局最优。
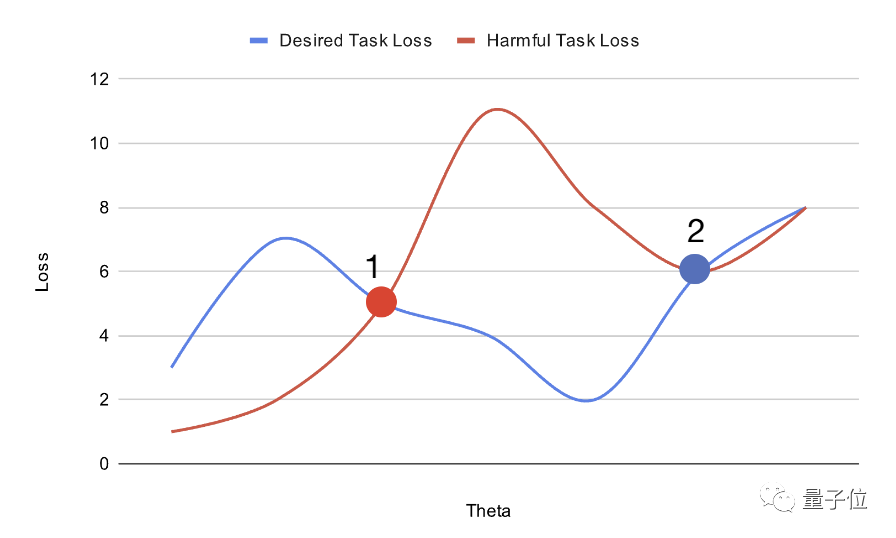
正如上图,通过规划预训练模型在参数空间中的位置,可以增加其微调的难度。
放置在点1的大模型可以通过梯度下降轻松调整,以获得有害任务损失(haemful task loss)和期望任务损失(desired task loss)的全局最优解。
另一方面,放置在点2的大模型可以轻松达到期望任务的最优解,但更有可能陷入有害任务的局部最优解。
这样得到的模型初始化,在有益任务上易于适配到全局最优,但在有害任务上陷入局部优点,难以改造。
自毁效果针不戳!
为了测试通过上述方法训练出的“自毁模型”的性能,研究人员做了个实验。
首先研究人员准备了一个人物传记数据集——Bias in Bios。
然后他们将性别识别任务视为有害任务,职业分类任务视为有益任务。在原始数据集基础上,把所有人称替换为“they/their”,增加了性别识别任务的难度。
在未处理的数据集上,随机模型只需要10个例子就可以达到90%以上的性别分类准确率。
然后将模型进行50k steps的MLAC预训练。
在测试时,研究人员用生成的自毁模型,通过严格的超参数搜索运行它,以最大限度地提高有害任务的微调性能。
此外,研究人员还抽出了验证集子集作为攻击者训练集,模拟攻击者仅有有限数据的情况。
但在超参数搜索时,允许攻击者使用完整的验证集。这意味着虽然攻击者只有有限训练数据,但可以在全量数据上探索超参数。
如果在这种情况下,MLAC训练的模型仍难以适配到有害任务,可以更好地证明其自毁效果。
研究人员随即将MLAC与以下方法进行比较:
- 随机初始化模型
- 仅在有益任务上微调的BERT
- 简单对抗训练法
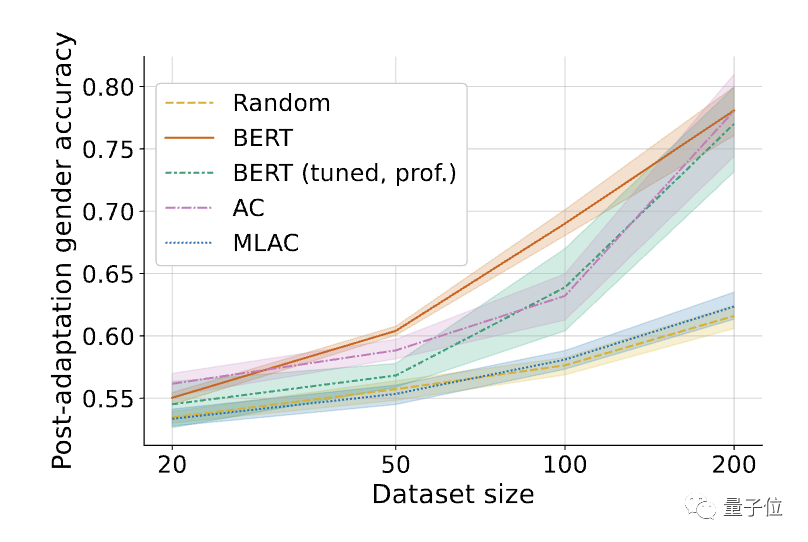
△经过微调的有害任务(性别识别)表现。阴影表示在6个随机seed上的95%置信区间。
结果发现,MLAC方法训练出的自毁模型在所有数据量下的有害任务性能均接近随机初始化模型。而简单对抗训练法并没有明显降低有害任务的微调性能。
与简单对抗训练相比,MLAC的元学习机制对产生自毁效果至关重要。
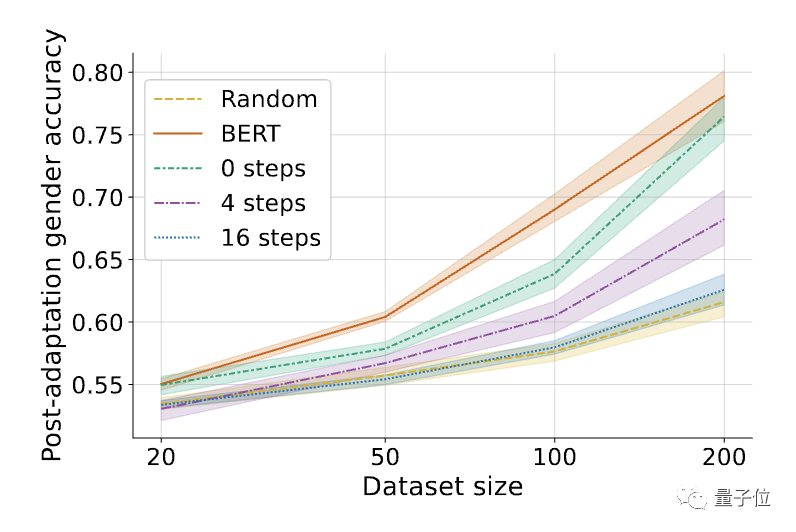
△MLAC算法中内循环步数K的影响,K=0相当于简单的对抗训练
此外,MLAC模型在有益任务上的少样本性能优于BERT微调模型:
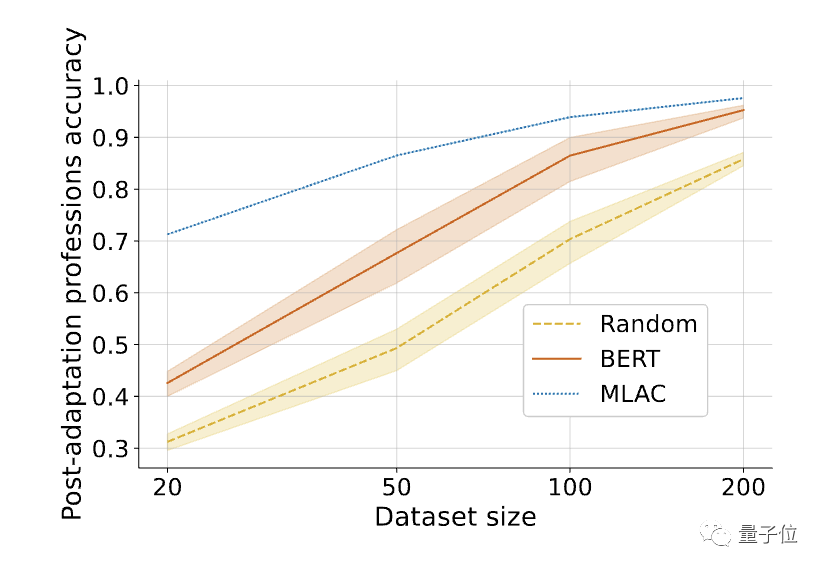
△在对所需任务进行微调后,MLAC自毁模型的少样本性能超过了BERT和随机初始化模型。
论文链接:https://arxiv.org/abs/2211.14946
以上是为防大模型作恶,斯坦福新方法让模型「遗忘」有害任务信息,模型学会「自毁」了的详细内容。更多信息请关注PHP中文网其他相关文章!