
如何在Python中实现梯度下降算法以寻找局部最小值?

- 王林转载
- 2023-09-06 22:37:05955浏览
梯度下降是机器学习中一种重要的优化方法,用于最小化模型的损失函数。通俗地说,它需要反复改变模型的参数,直到找到最小化损失函数的理想值范围。该方法的工作原理是沿着损失函数负梯度的方向,或者更具体地说,沿着最速下降的路径,迈出微小的一步。学习率是调节算法速度和准确性之间权衡的超参数,它会影响步长的大小。许多机器学习方法,包括线性回归、逻辑回归和神经网络,仅举几例,都采用梯度下降。它的主要应用是模型训练,其目标是最小化目标变量的预期值和实际值之间的差异。在这篇文章中,我们将研究在 Python 中实现梯度下降来找到局部最小值。
现在是时候在 Python 中实现梯度下降了。以下是我们如何实现它的基本说明 -
首先,我们导入必要的库。
定义它的函数及其导数。
接下来,我们将应用梯度下降函数。
应用函数后,我们将设置参数来查找局部最小值,
最后,我们将绘制输出图。
在Python中实现梯度下降
导入库
import numpy as np import matplotlib.pyplot as plt
然后我们定义函数 f(x) 及其导数 f'(x) -
def f(x): return x**2 - 4*x + 6 def df(x): return 2*x - 4
F(x) 是必须减少的函数,df 是其导数 (x)。梯度下降方法利用导数通过揭示函数沿途的斜率来引导自身趋向最小值。
然后定义梯度下降函数。
def gradient_descent(initial_x, learning_rate, num_iterations):
x = initial_x
x_history = [x]
for i in range(num_iterations):
gradient = df(x)
x = x - learning_rate * gradient
x_history.append(x)
return x, x_history
x的起始值、学习率和所需的迭代次数被发送到梯度下降函数。为了在每次迭代后保存 x 的值,它将 x 初始化为其原始值并生成一个空列表。然后,该方法对所提供的迭代次数执行梯度下降,根据方程 x = x - 学习率 * 梯度在每次迭代中更改 x。该函数生成每次迭代的 x 值以及 x 的最终值的列表。
梯度下降函数现在可用于定位 f(x) 的局部最小值 -
示例
initial_x = 0
learning_rate = 0.1
num_iterations = 50
x, x_history = gradient_descent(initial_x, learning_rate, num_iterations)
print("Local minimum: {:.2f}".format(x))
输出
Local minimum: 2.00
在此图中,x 一开始设置为 0,学习率为 0.1,并运行 50 次迭代。最后,我们发布 x 的值,该值应该接近 x=2 处的局部最小值。
绘制函数 f(x) 和每次迭代的 x 值可以让我们看到实际的梯度下降过程 -
示例
# Create a range of x values to plot
x_vals = np.linspace(-1, 5, 100)
# Plot the function f(x)
plt.plot(x_vals, f(x_vals))
# Plot the values of x at each iteration
plt.plot(x_history, f(np.array(x_history)), 'rx')
# Label the axes and add a title
plt.xlabel('x')
plt.ylabel('f(x)')
plt.title('Gradient Descent')
# Show the plot
plt.show()
输出
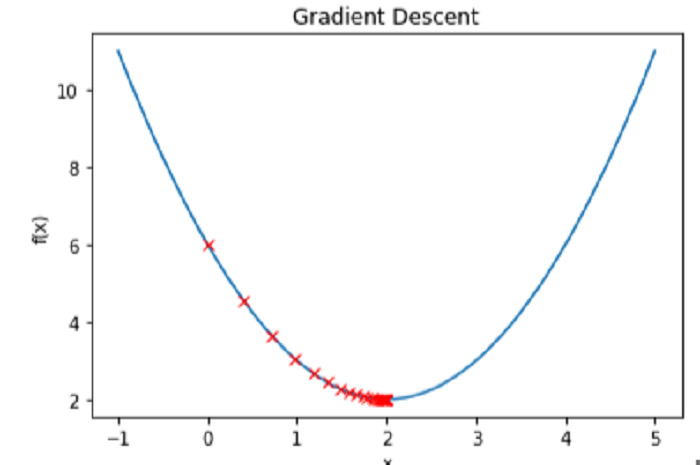
结论
总之,为了找到函数的局部最小值,Python 利用了称为梯度下降的有效优化过程。梯度下降通过在每一步计算函数的导数,沿最陡下降的方向重复更新输入值,直到达到最低值。在 Python 中实现梯度下降需要指定要优化的函数及其导数、初始化输入值以及确定算法的学习率和迭代次数。优化完成后,可以通过跟踪其步骤到最小值并查看它是如何达到这一目标来评估该方法。梯度下降在机器学习和优化应用中是一种有用的技术,因为 Python 可以处理大数据集和复杂的函数。
以上是如何在Python中实现梯度下降算法以寻找局部最小值?的详细内容。更多信息请关注PHP中文网其他相关文章!