
深入探讨GET3D生成模型的五分钟技术趣谈

- 王林转载
- 2023-09-01 19:01:061469浏览
Part 01●
前言
近年来,随着以Midjourney和Stable Diffusion为代表的人工智能图像生成工具的兴起,2D人工智能图像生成技术已经成为许多设计师在实际项目中使用的辅助工具,在各种商业场景中得到应用,创造出越来越多的实际价值。同时,随着元宇宙的兴起,许多行业正朝着创建大规模3D虚拟世界的方向发展,多样化、高质量的3D内容对于游戏、机器人、建筑和社交平台等行业变得越来越重要。然而,手动创建3D资源非常耗时且需要特定的艺术素养和建模技能。其中一个主要挑战是规模问题——尽管可以在3D市场上找到大量的3D模型,但在游戏或电影中填充一群看起来都不一样的角色或建筑仍然需要艺术家投入大量时间。因此,对于能够在3D内容的数量、质量和多样性方面进行扩展的内容制作工具的需求也变得越来越明显
 图片
图片
请看图1,这是元宇宙空间的照片(来源:电影《无敌破坏王2》)
得益于2D生成模型在高分辨率图像合成中已经获得了逼真的质量,这一进展也启发了对3D内容生成的研究。早期的方法旨在将2D CNN生成器直接扩展到3D体素网格,但由于3D卷积的高内存占用和计算复杂性,阻碍了在高分辨率下的生成过程。作为一种替代方案,其他研究已经探索了点云、隐式或八叉树表示。然而,这些工作主要集中在生成几何体上,而忽略了外观。它们的输出表示还需要进行后处理,以使其与标准图形引擎兼容
为了能够实际应用到内容制作中,理想的3D生成模型应当满足以下要求:
具备生成具有几何细节和任意拓扑的形状的能力
重写内容:(b)输出的应该是纹理网格,这是Blender和Maya等标准图形软件所常用的表达方式
可以使用2D图像进行监督,因为它们比明确的3D形状更普遍
Part 02
3D生成模型简介
为了方便内容的创作过程并能够实际应用,生成性3D网络已经成为一个活跃的研究领域,能够产生高质量和多样化的3D资产。每年都有许多3D生成模型在ICCV、NeurlPS、ICML等大会上发表,其中包括以下几种前沿模型
Textured3DGAN是一种生成模型,它是卷积生成纹理3D网格方法的延伸。它能够在二维监督下学习使用GAN从实物图像中生成纹理网格。与以往的方法相比,Textured3DGAN放宽了姿态估计步骤中对关键点的要求,并将该方法推广到未标记的图像集合和新的类别/数据集,例如ImageNet
DIB-R:是一种基于插值的可微分渲染器,底层使用了PyTorch机器学习框架。这个渲染器已经被添加到了3D深度学习的PyTorch GitHub库中(Kaolin)。这种方法允许对图像中所有像素的梯度进行分析计算。其核心思想是将前景光栅化视为局部属性的加权插值,将背景光栅化视为基于距离的全局几何体的聚合。通过这种方式,它可以从单个图像预测出形状、纹理和光线等信息
PolyGen:PolyGen是一种基于Transformer架构的自回归生成模型,用于直接对网格进行建模。该模型依次预测网格的顶点和面。我们使用ShapeNet Core V2数据集对模型进行训练,得到的结果已经非常接近于人类构建的网格模型
SurfGen:具有显式表面鉴别器的对抗性3D形状合成。通过端到端训练的模型能够生成具有不同拓扑的高保真3D形状。
GET3D是一个生成模型,可以通过学习图像来生成高质量的3D纹理形状。它的核心是可微分表面建模、可微分渲染和2D生成对抗性网络。通过对2D图像集合进行训练,GET3D可以直接生成具有复杂拓扑、丰富几何细节和高保真纹理的显式纹理3D网格
 图片
图片
需要重写的内容是:图2 GET3D生成模型(来源:GET3D论文官网https://nv-tlabs.github.io/GET3D/)
GET3D是最近提出的一种3D生成模型,它通过使用ShapeNet、Turbosquid和Renderpeople等多个具有复杂几何图形的类别,例如椅子、摩托车、汽车、人物和建筑,展示了在无限制生成3D形状方面的最先进性能
Part 03
GET3D的架构和特性
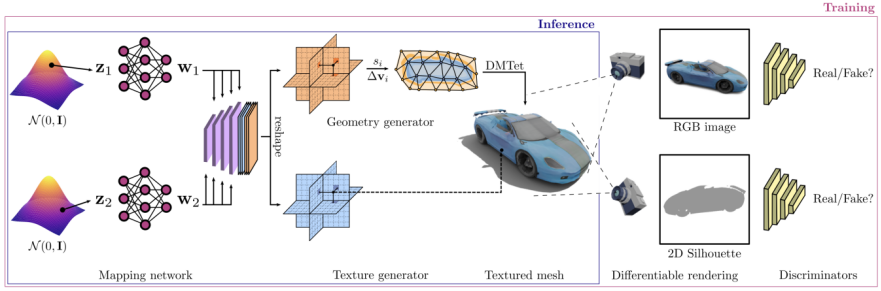 图片
图片
GET3D架构来源于GET3D论文官网,图3展示了该架构
通过两个潜在编码生成了一个3D SDF(有向距离场)和一个纹理场,再利用DMTet(Deep Marching Tetrahedra)从SDF中提取3D表面网格,并在表面点云查询纹理场以获取颜色。整个过程使用在2D图像上定义的对抗性损失来进行训练。特别是,RGB图像和轮廓是使用基于光栅化的可微分渲染器来获取的。最后使用两个2D鉴别器,每个鉴别器分别针对RGB图像和轮廓,来分辨输入是真实的还是伪造的。整个模型可以进行端到端的训练
GET3D在其他方面也非常灵活,除了将显式网格作为输出表达之外,还可以轻松适应其他任务,包括:
将几何体和纹理分离实现:模型的几何和纹理之间实现了良好的解耦,可以对几何潜在代码和纹理潜在代码进行有意义的插值
在生成不同类别形状之间的平滑过渡时,可以通过在潜在空间中进行随机行走,并生成相应的3D形状来实现
生成新的形状:可以通过向局部的潜在代码添加一些小的噪声来扰动,从而生成看起来相似但局部略有差异的形状
无监督材质生成:通过与DIBR++相结合,以完全无监督的方式生成材质,并产生具有意义的视图相关照明效果
以文本为导向的形状生成:通过结合StyleGAN NADA,利用计算渲染的2D图像和用户提供的文本上的定向CLIP损失来微调3D生成器,用户可以通过文本提示生成大量有意义的形状
 图片
图片
请参考图4,该图展示了基于文本生成形状的过程。该图的来源是GET3D论文官网,网址为https://nv-tlabs.github.io/GET3D/
Part 04
总结
虽然GET3D已经朝着实用的3D纹理形状的生成模型迈出了重要的一步,但是它仍然存在一些局限性。特别是在训练过程中,仍然依赖于2D剪影和相机分布的知识。因此,目前GET3D只能根据合成数据进行评估。一个有前景的扩展是利用实例分割和相机姿态估计方面的进步来缓解这个问题,并将GET3D扩展到真实世界的数据。GET3D目前还只按照类别进行训练,未来将扩展到多个类别,以更好地表示类别之间的多样性。希望这项研究能够让人们离使用人工智能进行3D内容的自由创作更近一步
以上是深入探讨GET3D生成模型的五分钟技术趣谈的详细内容。更多信息请关注PHP中文网其他相关文章!