




预测燃油效率对于优化车辆性能和减少碳排放至关重要,这可以使用 Python 库 Tensorflow 轻松预测。在本文中,我们将探讨如何利用流行的机器学习库 Tensorflow 的强大功能,使用 Python 来预测燃油效率。通过基于 Auto MPG 数据集构建预测模型,我们可以准确估计车辆的燃油效率。让我们深入了解在 Python 中利用 Tensorflow 进行准确燃油效率预测的过程。
自动 MPG 数据集
为了准确预测燃油效率,我们需要可靠的数据集。 Auto MPG 数据集源自 UCI 机器学习存储库,为我们的模型提供了必要的信息。它包含各种属性,例如气缸数量、排量、重量、马力、加速度、原产地和型号年份。这些属性充当特征,而燃油效率(以每加仑英里数或 MPG 为单位衡量)充当标签。通过分析该数据集,我们可以训练模型识别模式并根据相似的车辆特征进行预测。
准备数据集
在构建预测模型之前,我们需要准备数据集。这涉及处理缺失值和标准化特征。缺失值可能会破坏训练过程,因此我们将它们从数据集中删除。对马力和重量等特征进行标准化可确保每个特征都处于相似的范围内。这一步至关重要,因为具有大数值范围的特征可以主导模型的学习过程。标准化数据集可确保在训练期间公平对待所有特征。
如何使用 TensorFlow 预测燃油效率?
以下是我们使用 Tensorflow 预测燃油效率时将遵循的步骤 -
导入必要的库 - 我们导入tensorflow、Keras、layers 和 pandas。
加载 Auto MPG 数据集。我们还指定列名称并处理任何缺失值。
将数据集分为特征和标签 - 我们将数据集分为两部分 - 特征(输入变量)和标签(输出变量)。
标准化特征 - 我们使用最小-最大缩放来标准化特征。
数据集分为训练集和测试集。
定义模型架构 - 我们定义一个具有三个密集层的简单顺序模型,其中每层有 64 个神经元并使用 ReLU 激活函数。
编译模型 - 我们使用均方误差 (MSE) 损失函数和 RMSprop 优化器编译模型。
训练模型 - 在训练集上进行 1000 个时期的模型训练,并指定验证分割为 0.2。
评估模型 - 在测试集上进行模型评估并计算平均 MSE 以及燃油效率和绝对误差 (MAE)。
计算新车的燃油效率 - 我们使用 pandas DataFrame 创建新车的功能。我们使用与原始数据集相同的缩放因子来标准化新车的特征。
使用经过训练的模型预测新车的燃油效率。
打印预测燃油效率 - 我们将新车的预测燃油效率打印到控制台
打印测试指标 - 我们将测试 MAE 和 MSE 打印到控制台。
下面的程序使用 Tensorflow 构建神经网络模型,用于根据 Auto MPG 数据集预测燃油效率。
示例
# Import necessary libraries
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import pandas as pd
# Load the Auto MPG dataset
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data"
column_names = ['MPG','Cylinders','Displacement','Horsepower','Weight',
'Acceleration', 'Model Year', 'Origin']
raw_dataset = pd.read_csv(url, names=column_names,
na_values='?', comment='\t', sep=' ', skipinitialspace=True)
# Drop missing values
dataset = raw_dataset.dropna()
# Separate the dataset into features and labels
cfeatures = dataset.drop('MPG', axis=1)
labels = dataset['MPG']
# Normalize the features using min-max scaling
normalized_features = (cfeatures - cfeatures.min()) / (cfeatures.max() - cfeatures.min())
# Split the dataset into training and testing sets
train_features = normalized_features[:300]
test_features = normalized_features[300:]
train_labels = labels[:300]
test_labels = labels[300:]
# Define the model architecture for this we will use sequential API of the keras
model1 = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_features.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
#if you want summary of the model’s architecture you can use the code: model1.summary()
# Model compilation
optimizer = tf.keras.optimizers.RMSprop(0.001)
model1.compile(loss='mse', optimizer=optimizer, metrics=['mae', 'mse'])
# Train the model
Mhistory = model1.fit(
train_features, train_labels,
epochs=1000, validation_split = 0.2, verbose=0)
# Evaluate the model on the test set
test_loss, test_mae, test_mse = model1.evaluate(test_features, test_labels)
# Train the model
model1.fit(train_features, train_labels, epochs=1000, verbose=0)
# Calculation of the fuel efficiency for a new car
new_car_features = pd.DataFrame([[4, 121, 110, 2800, 15.4, 81, 3]], columns=column_names[1:])
normalized_new_car_features = (new_car_features - cfeatures.min()) / (cfeatures.max() - cfeatures.min())
fuel_efficiencyc = model1.predict(normalized_new_car_features)
# Print the test metrics
print("Test MAE:", test_mae)
print("Test MSE:", test_mse)
print("Predicted Fuel Efficiency:", fuel_efficiencyc[0][0])
输出
C:\Users\Tutorialspoint>python image.py 3/3 [==============================] - 0s 2ms/step - loss: 18.8091 - mae: 3.3231 - mse: 18.8091 1/1 [==============================] - 0s 90ms/step Test MAE: 3.3230929374694824 Test MSE: 18.80905532836914 Predicted Fuel Efficiency: 24.55885
结论
总之,使用 Python 中的 Tensorflow 来预测燃油效率是一个强大的工具,可以帮助制造商和消费者做出明智的决策。通过分析各种车辆特征并训练神经网络模型,我们可以准确预测燃油效率。
这些信息可以促进更节能的车辆的开发,减少对环境的影响并为消费者节省成本。 Tensorflow 的多功能性和易用性使其成为汽车行业追求提高燃油效率的宝贵资产。
以上是使用Python中的Tensorflow预测燃油效率的详细内容。更多信息请关注PHP中文网其他相关文章!

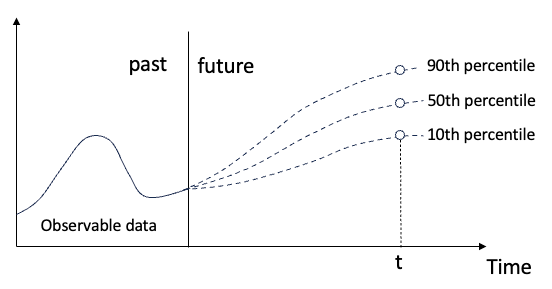 用于时间序列概率预测的分位数回归May 07, 2024 pm 05:04 PM
用于时间序列概率预测的分位数回归May 07, 2024 pm 05:04 PM不要改变原内容的意思,微调内容,重写内容,不要续写。“分位数回归满足这一需求,提供具有量化机会的预测区间。它是一种统计技术,用于模拟预测变量与响应变量之间的关系,特别是当响应变量的条件分布命令人感兴趣时。与传统的回归方法不同,分位数回归侧重于估计响应变量变量的条件量值,而不是条件均值。”图(A):分位数回归分位数回归概念分位数回归是估计⼀组回归变量X与被解释变量Y的分位数之间线性关系的建模⽅法。现有的回归模型实际上是研究被解释变量与解释变量之间关系的一种方法。他们关注解释变量与被解释变量之间的关
 SIMPL:用于自动驾驶的简单高效的多智能体运动预测基准Feb 20, 2024 am 11:48 AM
SIMPL:用于自动驾驶的简单高效的多智能体运动预测基准Feb 20, 2024 am 11:48 AM原标题:SIMPL:ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving论文链接:https://arxiv.org/pdf/2402.02519.pdf代码链接:https://github.com/HKUST-Aerial-Robotics/SIMPL作者单位:香港科技大学大疆论文思路:本文提出了一种用于自动驾驶车辆的简单高效的运动预测基线(SIMPL)。与传统的以代理为中心(agent-cent
 如何使用MySQL数据库进行预测和预测分析?Jul 12, 2023 pm 08:43 PM
如何使用MySQL数据库进行预测和预测分析?Jul 12, 2023 pm 08:43 PM如何使用MySQL数据库进行预测和预测分析?概述:预测和预测分析在数据分析中扮演着重要角色。MySQL作为一种广泛使用的关系型数据库管理系统,也可以用于预测和预测分析任务。本文将介绍如何使用MySQL进行预测和预测分析,并提供相关的代码示例。数据准备:首先,我们需要准备相关的数据。假设我们要进行销售预测,我们需要具有销售数据的表。在MySQL中,我们可以使用
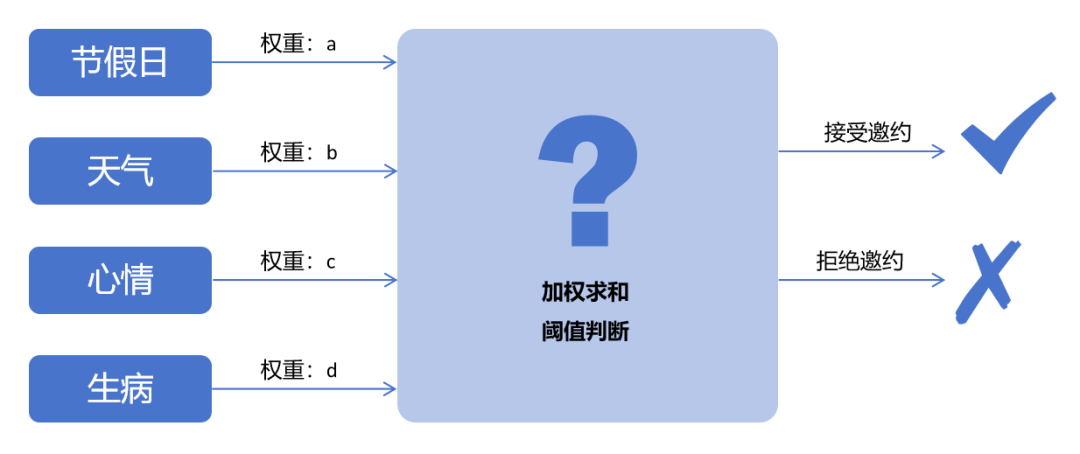 AI推理和训练有什么不同?你知道吗?Mar 26, 2024 pm 02:40 PM
AI推理和训练有什么不同?你知道吗?Mar 26, 2024 pm 02:40 PM如果要用一句话概括AI的训练和推理的不同之处,我觉得用“台上一分钟,台下十年功”最为贴切。小明和心仪已久的女神交往多年,对邀约她出门的技巧和心得颇有心得,但仍对其中的奥秘感到困惑。借助AI技术,能否实现精准预测呢?小明思考再三,总结出了可能影响女神是否接受邀请的变量:是否节假日,天气不好,太热/太冷了,心情不好,生病了,另有他约,家里来亲戚了......等等。图片将这些变量加权求和,如果大于某个阈值,女神必定接受邀约。那么,这些变量的都占多少权重,阈值又是多少呢?这是一个十分复杂的问题,很难通过
 详细讲解Python之Seaborn(数据可视化)Apr 21, 2022 pm 06:08 PM
详细讲解Python之Seaborn(数据可视化)Apr 21, 2022 pm 06:08 PM本篇文章给大家带来了关于Python的相关知识,其中主要介绍了关于Seaborn的相关问题,包括了数据可视化处理的散点图、折线图、条形图等等内容,下面一起来看一下,希望对大家有帮助。
 跨模态占据性知识的学习:使用渲染辅助蒸馏技术的RadOccJan 25, 2024 am 11:36 AM
跨模态占据性知识的学习:使用渲染辅助蒸馏技术的RadOccJan 25, 2024 am 11:36 AM原标题:Radocc:LearningCross-ModalityOccupancyKnowledgethroughRenderingAssistedDistillation论文链接:https://arxiv.org/pdf/2312.11829.pdf作者单位:FNii,CUHK-ShenzhenSSE,CUHK-Shenzhen华为诺亚方舟实验室会议:AAAI2024论文思路:3D占用预测是一项新兴任务,旨在使用多视图图像估计3D场景的占用状态和语义。然而,由于缺乏几何先验,基于图像的场景
 Microsoft 365 在 Excel 中启用 PythonSep 22, 2023 pm 10:53 PM
Microsoft 365 在 Excel 中启用 PythonSep 22, 2023 pm 10:53 PM1、在Excel中启用PythonPythoninExcel目前处于测试阶段,如果要使用这个功能,请确保是Windows版的Microsoft365,并加入Microsoft365预览体验计划,选择Beta版频道。点击Excel页面左上角的【文件】>【账户】。在页面左边可以找到以下信息:以上步骤完成后,打开空白工作薄:单击【公式】选项卡,选择【插入Python】-【Excel中的Python】。在弹出的对话框里单击【试用预览版】。接下来,我们就可以开始体验Python的妙用啦!2、
 分享10款高效的VSCode插件,总有一款能够惊艳到你!!Mar 09, 2021 am 10:15 AM
分享10款高效的VSCode插件,总有一款能够惊艳到你!!Mar 09, 2021 am 10:15 AMVS Code的确是一款非常热门、有强大用户基础的一款开发工具。本文给大家介绍一下10款高效、好用的插件,能够让原本单薄的VS Code如虎添翼,开发效率顿时提升到一个新的阶段。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

SublimeText3汉化版
中文版,非常好用

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

