



如何使用PHP开发网页爬虫功能
引言:
随着互联网的迅猛发展,很多网站提供的数据已经越来越庞大,人工手动获取这些数据已经越来越困难。而使用Web爬虫技术则成为一种高效的解决方案。本文将介绍如何利用PHP语言开发一个简单的网页爬虫功能,并附有相应的代码示例。
一、准备工作
在开始编写网页爬虫之前,我们需要安装PHP运行环境和相应的扩展,常用的扩展有Simple HTML DOM和cURL。前者用于解析HTML,后者用于发送HTTP请求。
安装PHP运行环境和扩展可参考相关资料。
二、分析目标网站
在编写代码之前,我们需要分析目标网站的页面结构,了解需要爬取的数据所在的位置以及其所在的HTML标签等。这一步是非常关键的,可以通过浏览器的开发者工具来进行分析。
三、编写爬虫代码
以下是一个示例的PHP爬虫代码:
<?php
// 引入Simple HTML DOM库
include('simple_html_dom.php');
// 定义目标网站的URL
$targetUrl = 'https://example.com';
// 创建一个cURL资源
$ch = curl_init();
// 设置cURL参数
curl_setopt($ch, CURLOPT_URL, $targetUrl);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
// 执行HTTP请求,获取响应内容
$response = curl_exec($ch);
// 关闭cURL资源
curl_close($ch);
// 创建一个HTML DOM对象
$html = new simple_html_dom();
$html->load($response);
// 查找并提取需要的数据
$data = $html->find('.target-class');
// 遍历数据并输出
foreach ($data as $item) {
echo $item->plaintext;
}以上代码首先使用cURL发送HTTP请求获取目标网站的内容,然后使用HTML DOM库解析HTML内容,并通过查找指定的HTML标签或类名来提取需要的数据。最后,遍历数据并输出。
四、调试与优化
在实际编写爬虫代码时,可能会遇到各种问题,如页面结构变动、网络连接失败等。因此,我们需要进行调试和优化,确保程序的稳定性和准确性。
以下是一些常见的调试和优化技巧:
- 使用日志功能记录程序运行过程和错误信息,以便排查问题。
- 对于大量数据的爬取,可以考虑使用多线程或分布式爬虫,提高效率。
- 遵循网站的爬虫规则,设置合理的爬取间隔,避免给目标网站造成过大的压力。
结语:
本文介绍了如何使用PHP开发一个简单的网页爬虫功能,并附有相应的代码示例。通过学习和实践,我们可以更好地理解和掌握网页爬虫的原理和技术,从而更高效地获取互联网上的数据,为我们的工作和生活带来便利和效益。
以上是如何使用PHP开发网页爬虫功能的详细内容。更多信息请关注PHP中文网其他相关文章!

 Nuitka简介:编译和分发Python的更好方法Apr 13, 2023 pm 12:55 PM
Nuitka简介:编译和分发Python的更好方法Apr 13, 2023 pm 12:55 PM译者 | 李睿审校 | 孙淑娟随着Python越来越受欢迎,其局限性也越来越明显。一方面,编写Python应用程序并将其分发给没有安装Python的人员可能非常困难。解决这一问题的最常见方法是将程序与其所有支持库和文件以及Python运行时打包在一起。有一些工具可以做到这一点,例如PyInstaller,但它们需要大量的缓存才能正常工作。更重要的是,通常可以从生成的包中提取Python程序的源代码。在某些情况下,这会破坏交易。第三方项目Nuitka提供了一个激进的解决方案。它将Python程序编
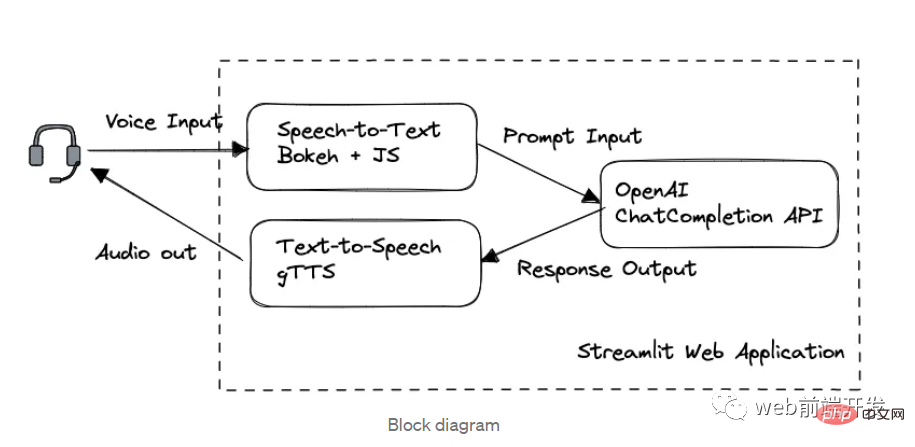 我创建了一个由 ChatGPT API 提供支持的语音聊天机器人,方法请收下Apr 07, 2023 pm 11:01 PM
我创建了一个由 ChatGPT API 提供支持的语音聊天机器人,方法请收下Apr 07, 2023 pm 11:01 PM今天这篇文章的重点是使用 ChatGPT API 创建私人语音 Chatbot Web 应用程序。目的是探索和发现人工智能的更多潜在用例和商业机会。我将逐步指导您完成开发过程,以确保您理解并可以复制自己的过程。为什么需要不是每个人都欢迎基于打字的服务,想象一下仍在学习写作技巧的孩子或无法在屏幕上正确看到单词的老年人。基于语音的 AI Chatbot 是解决这个问题的方法,就像它如何帮助我的孩子要求他的语音 Chatbot 给他读睡前故事一样。鉴于现有可用的助手选项,例如,苹果的 Siri 和亚马
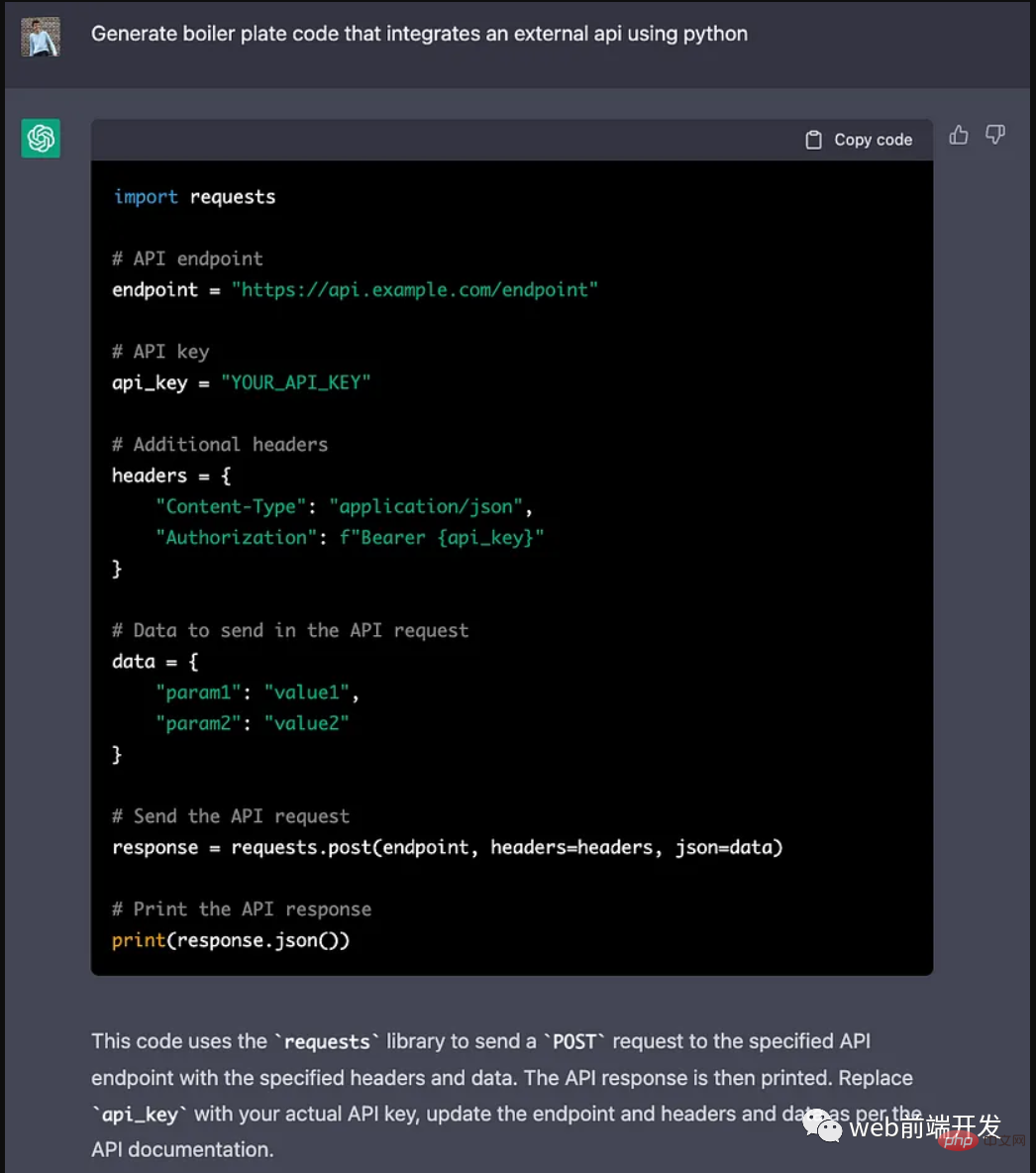 ChatGPT 的五大功能可以帮助你提高代码质量Apr 14, 2023 pm 02:58 PM
ChatGPT 的五大功能可以帮助你提高代码质量Apr 14, 2023 pm 02:58 PMChatGPT 目前彻底改变了开发代码的方式,然而,大多数软件开发人员和数据专家仍然没有使用 ChatGPT 来改进和简化他们的工作。这就是为什么我在这里概述 5 个不同的功能,以提高我们的日常工作速度和质量。我们可以在日常工作中使用它们。现在,我们一起来了解一下吧。注意:切勿在 ChatGPT 中使用关键代码或信息。01.生成项目代码的框架从头开始构建新项目时,ChatGPT 是我的秘密武器。只需几个提示,它就可以生成我需要的代码框架,包括我选择的技术、框架和版本。它不仅为我节省了至少一个小时
 解决Batch Norm层等短板的开放环境解决方案Apr 26, 2023 am 10:01 AM
解决Batch Norm层等短板的开放环境解决方案Apr 26, 2023 am 10:01 AM测试时自适应(Test-TimeAdaptation,TTA)方法在测试阶段指导模型进行快速无监督/自监督学习,是当前用于提升深度模型分布外泛化能力的一种强有效工具。然而在动态开放场景中,稳定性不足仍是现有TTA方法的一大短板,严重阻碍了其实际部署。为此,来自华南理工大学、腾讯AILab及新加坡国立大学的研究团队,从统一的角度对现有TTA方法在动态场景下不稳定原因进行分析,指出依赖于Batch的归一化层是导致不稳定的关键原因之一,另外测试数据流中某些具有噪声/大规模梯度的样本
 摔倒检测-完全用ChatGPT开发,分享如何正确地向ChatGPT提问Apr 07, 2023 pm 03:06 PM
摔倒检测-完全用ChatGPT开发,分享如何正确地向ChatGPT提问Apr 07, 2023 pm 03:06 PM哈喽,大家好。之前给大家分享过摔倒识别、打架识别,今天以摔倒识别为例,我们看看能不能完全交给ChatGPT来做。让ChatGPT来做这件事,最核心的是如何向ChatGPT提问,把问题一股脑的直接丢给ChatGPT,如:用 Python 写个摔倒检测代码 是不可取的, 而是要像挤牙膏一样,一点一点引导ChatGPT得到准确的答案,从而才能真正让ChatGPT提高我们解决问题的效率。今天分享的摔倒识别案例,与ChatGPT对话的思路清晰,代码可用度高,按照GPT返回的结果完全可以开
 17 个可以实现高效工作与在线赚钱的 AI 工具网站Apr 11, 2023 pm 04:13 PM
17 个可以实现高效工作与在线赚钱的 AI 工具网站Apr 11, 2023 pm 04:13 PM自 2020 年以来,内容开发领域已经感受到人工智能工具的存在。1.Jasper AI网址:https://www.jasper.ai在可用的 AI 文案写作工具中,Jasper 作为那些寻求通过内容生成赚钱的人来讲,它是经济实惠且高效的选择之一。该工具精通短格式和长格式内容均能完成。Jasper 拥有一系列功能,包括无需切换到模板即可快速生成内容的命令、用于创建文章的高效长格式编辑器,以及包含有助于创建各种类型内容的向导的内容工作流,例如,博客文章、销售文案和重写。Jasper Chat 是该
 为什么特斯拉的人形机器人长得并不像人?一文了解恐怖谷效应对机器人公司的影响Apr 14, 2023 pm 11:13 PM
为什么特斯拉的人形机器人长得并不像人?一文了解恐怖谷效应对机器人公司的影响Apr 14, 2023 pm 11:13 PM1970年,机器人专家森政弘(MasahiroMori)首次描述了「恐怖谷」的影响,这一概念对机器人领域产生了巨大影响。「恐怖谷」效应描述了当人类看到类似人类的物体,特别是机器人时所表现出的积极和消极反应。恐怖谷效应理论认为,机器人的外观和动作越像人,我们对它的同理心就越强。然而,在某些时候,机器人或虚拟人物变得过于逼真,但又不那么像人时,我们大脑的视觉处理系统就会被混淆。最终,我们会深深地陷入一种对机器人非常消极的情绪状态里。森政弘的假设指出:由于机器人与人类在外表、动作上相似,所以人类亦会对
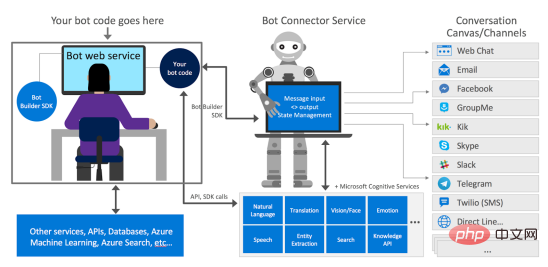 如何使用Azure Bot Services创建聊天机器人的分步说明Apr 11, 2023 pm 06:34 PM
如何使用Azure Bot Services创建聊天机器人的分步说明Apr 11, 2023 pm 06:34 PM译者 | 李睿审校 | 孙淑娟信使、网络服务和其他软件都离不开机器人(bot)。而在软件开发和应用中,机器人是一种应用程序,旨在自动执行(或根据预设脚本执行)响应用户请求创建的操作。在本文中, NIX United公司的.NET开发人员Daniil Mikhov介绍了使用微软Azure Bot Services创建聊天机器人的一个例子。本文将对想要使用该服务开发聊天机器人的开发人员有所帮助。 为什么使用Azure Bot Services? 在Azure Bot Services上开发聊


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

Dreamweaver CS6
视觉化网页开发工具

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

