
轻量级视觉网络新主干:高效的傅里叶算子Token混合器

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB转载
- 2023-08-17 17:57:081576浏览
1. 背景
这些年来,Transformer、Large-kernel CNN和MLP这三种视觉主干网络在广泛的计算机视觉任务中取得了巨大的成功,这主要归功于它们在全局范围内高效地融合信息的能力
Transformer、CNN和MLP是当前三种主流的神经网络,它们分别采用不同的方式来实现全局范围的Token融合。在Transformer网络中,自注意力机制利用查询-键对的相关性作为Token融合的权重。CNN通过扩大卷积核的尺寸来实现与Transformer相似的性能。而MLP则通过全连接在所有令牌之间实现另一种强大的范式。尽管这些方法都是有效的,但它们的计算复杂度较高(O(N^2)),难以在存储和计算能力有限的设备上部署,从而限制了很多模型的应用范围
2. AFF Token Mixer: 轻量、全局、自适应
为了解决计算昂贵的问题,研究人员开发了一种名为自适应傅里叶滤波器(Adaptive Fourier Filter,AFF)的高效全局Token融合算法。该算法利用傅里叶变换将Token集合转换到频域,并在频域学习到一个能够自适应内容的滤波掩膜,以对转换到频域空间中的Token集合进行自适应滤波操作
Adaptive Frequency Filters: Efficient Global Token Mixers

点击此链接可访问原文:https://arxiv.org/abs/2307.14008
根据频域卷积定理,AFF Token Mixer 的数学等价操作是在原始域中进行的卷积操作,相当于在傅里叶域中进行的Hadamard乘积操作。这意味着AFF Token Mixer 可以通过在原始域中使用一个动态卷积核,其空间分辨率与Token集合大小相同,来实现内容自适应的全局Token融合(如下图右子图所示)
众所周知,动态卷积的计算成本很高,尤其是在使用大空间分辨率的动态卷积核时,对于高效 / 轻量级网络设计来说,这种成本似乎是难以接受的。然而,本文提出的 AFF Token Mixer 却能够以低功耗的等效实现方式同时满足上述要求,将复杂性从 O (N^2) 降低到 O (N log N),从而显著提高了计算效率
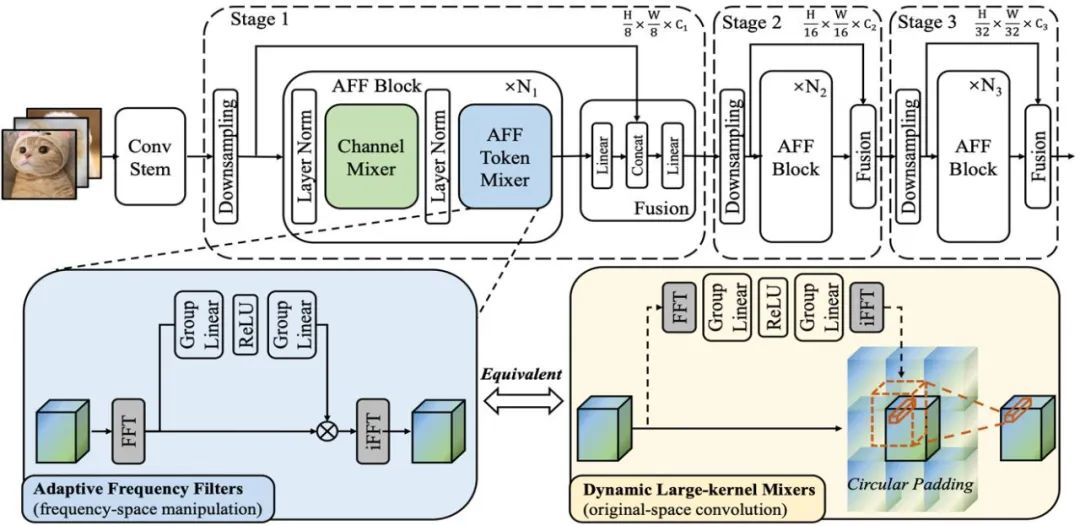
示意图 1:展示了 AFF 模块和 AFFNet 网络的结构
3. AFFNet:轻量级视觉网络新主干
通过将 AFF Token Mixer 作为主要神经网络操作算子,研究人员成功构建了一个称为 AFFNet 的轻量级神经网络。丰富的实验结果表明,AFF Token Mixer 在广泛的视觉任务中取得了卓越的准确性和效率平衡,包括视觉语义识别和密集预测任务
4. 实验结果
研究人员评估了AFF Token Mixer和AFFNet在视觉语义识别、分割、检测等多个任务上的性能,并与目前研究领域中最先进的轻量级视觉主干网络进行了比较。实验结果显示,该模型设计在广泛的视觉任务中表现出色,证实了AFF Token Mixer作为新一代轻量高效的Token融合算子的潜力
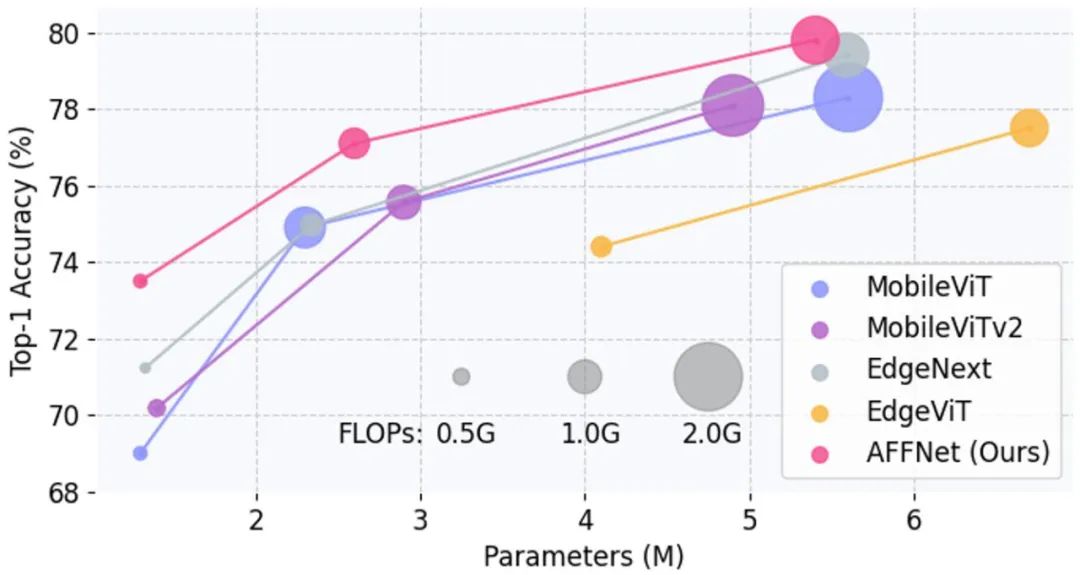
与SOTA相比,图2展示了在ImageNet-1K数据集上的Acc-Param和Acc-FLOPs曲线
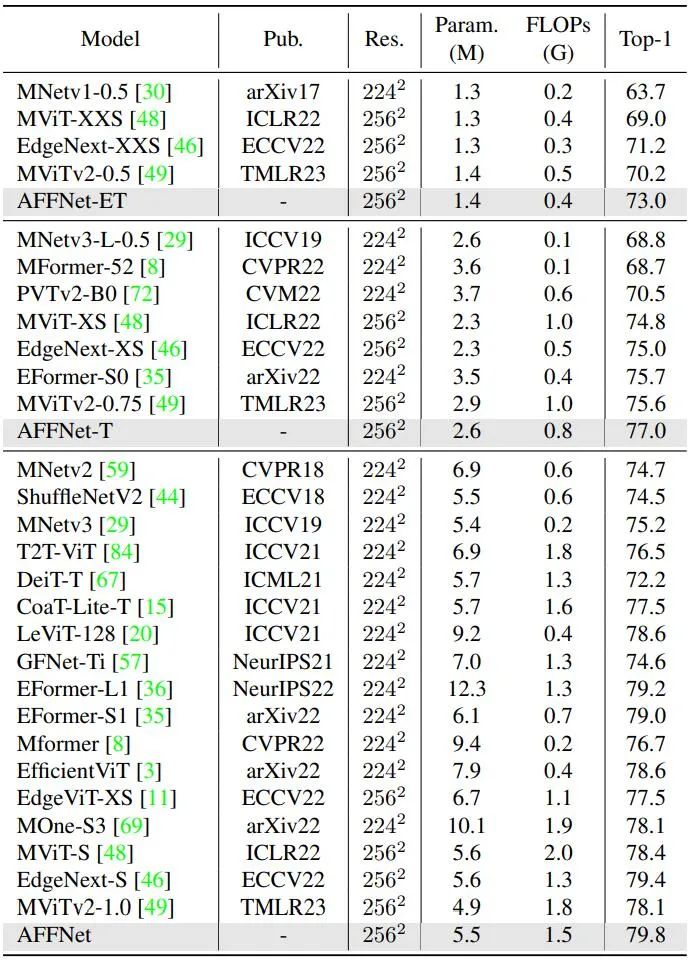
对比最先进的方法与ImageNet-1K数据集的结果,见表1
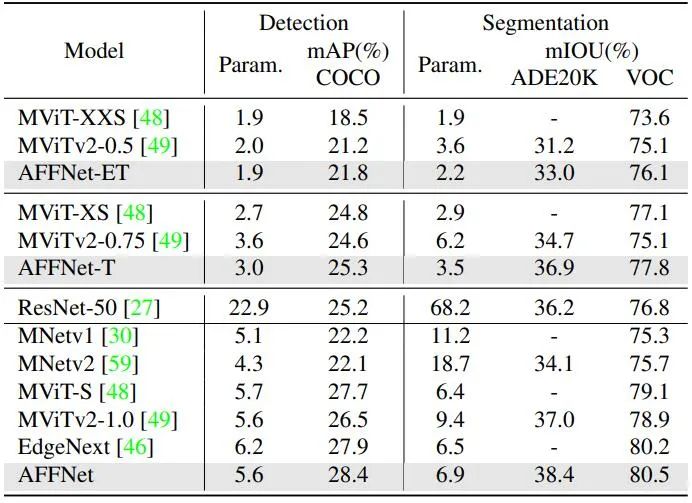
表2显示了视觉检测和分割任务与最先进技术的比较
5. 结论
这项研究证明了隐空间中的频域变换在全局自适应 Token 融合中起到了重要作用,是一种高效且低功耗的等效实现方式。它为神经网络中的 Token 融合算子设计提供了新的研究思路,并为在边缘设备上部署神经网络模型提供了新的发展空间,尤其是在存储和计算能力有限的情况下
以上是轻量级视觉网络新主干:高效的傅里叶算子Token混合器的详细内容。更多信息请关注PHP中文网其他相关文章!