
面试必问:从输入url到页面展示到底发生了什么
- Java学习指南转载
- 2023-07-26 17:01:372333浏览
刚开始写这篇文章还是挺纠结的,因为网上搜索“从输入url到页面展示到底发生了什么”,你可以搜到一大堆的资料。而且面试这道题基本是必考题,二月份面试的时候,虽然知道这个过程发生了什么,不过当面试官一步步追问下去的,很多细节就不太清楚了。
本文的目的是通过输入url之后发生的事情来做知识的总结和扩展。所以文章可能会很杂。
总的过程大概如下:
1、输入地址
当我们开始在浏览器中输入网址的时候,浏览器其实就已经在智能的匹配可能得 url 了,他会从历史记录,书签等地方,找到已经输入的字符串可能对应的 url,然后给出智能提示,让你可以补全url地址。对于 google的chrome 的浏览器,他甚至会直接从缓存中把网页展示出来,就是说,你还没有按下 enter,页面就出来了。
2、浏览器查找域名的 IP 地址
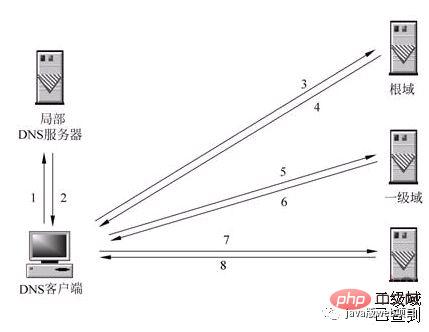
1、请求一旦发起,浏览器首先要做的事情就是解析这个域名,一般来说,浏览器会首先查看本地硬盘的 hosts 文件,看看其中有没有和这个域名对应的规则,如果有的话就直接使用 hosts 文件里面的 ip 地址。
2、如果在本地的 hosts 文件没有能够找到对应的 ip 地址,浏览器会发出一个 DNS请求到本地DNS服务器 。本地DNS服务器一般都是你的网络接入服务器商提供,比如中国电信,中国移动。
3、查询你输入的网址的DNS请求到达本地DNS服务器之后,本地DNS服务器会首先查询它的缓存记录,如果缓存中有此条记录,就可以直接返回结果,此过程是递归的方式进行查询。如果没有,本地DNS服务器还要向DNS根服务器进行查询。
4、根DNS服务器没有记录具体的域名和IP地址的对应关系,而是告诉本地DNS服务器,你可以到域服务器上去继续查询,并给出域服务器的地址。这种过程是迭代的过程。
5、本地DNS服务器继续向域服务器发出请求,在这个例子中,请求的对象是.com域服务器。.com域服务器收到请求之后,也不会直接返回域名和IP地址的对应关系,而是告诉本地DNS服务器,你的域名的解析服务器的地址。
6、最后,本地DNS服务器向域名的解析服务器发出请求,这时就能收到一个域名和IP地址对应关系,本地DNS服务器不仅要把IP地址返回给用户电脑,还要把这个对应关系保存在缓存中,以备下次别的用户查询时,可以直接返回结果,加快网络访问。
下面这张图很完美的解释了这一过程:

知识扩展:
1)什么是DNS?
DNS(Domain Name System,域名系统),因特网上作为域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。通过主机名,最终得到该主机名对应的IP地址的过程叫做域名解析(或主机名解析)。
通俗的讲,我们更习惯于记住一个网站的名字,比如www.baidu.com,而不是记住它的ip地址,比如:167.23.10.2。而计算机更擅长记住网站的ip地址,而不是像www.baidu.com等链接。因为,DNS就相当于一个电话本,比如你要找www.baidu.com这个域名,那我翻一翻我的电话本,我就知道,哦,它的电话(ip)是167.23.10.2。
2)DNS查询的两种方式:递归查询和迭代查询
1、递归解析
当局部DNS服务器自己不能回答客户机的DNS查询时,它就需要向其他DNS服务器进行查询。此时有两种方式,如图所示的是递归方式。局部DNS服务器自己负责向其他DNS服务器进行查询,一般是先向该域名的根域服务器查询,再由根域名服务器一级级向下查询。最后得到的查询结果返回给局部DNS服务器,再由局部DNS服务器返回给客户端。

2、迭代解析
当局部DNS服务器自己不能回答客户机的DNS查询时,也可以通过迭代查询的方式进行解析,如图所示。局部DNS服务器不是自己向其他DNS服务器进行查询,而是把能解析该域名的其他DNS服务器的IP地址返回给客户端DNS程序,客户端DNS程序再继续向这些DNS服务器进行查询,直到得到查询结果为止。也就是说,迭代解析只是帮你找到相关的服务器而已,而不会帮你去查。比如说:baidu.com的服务器ip地址在192.168.4.5这里,你自己去查吧,本人比较忙,只能帮你到这里了。
3)DNS域名称空间的组织方式
我们在前面有说到根DNS服务器,域DNS服务器,这些都是DNS域名称空间的组织方式。按其功能命名空间中用来描述 DNS 域名称的五个类别的介绍详见下表中,以及与每个名称类型的示例
 (盗图)
(盗图)
4)DNS负载均衡
当一个网站有足够多的用户的时候,假如每次请求的资源都位于同一台机器上面,那么这台机器随时可能会蹦掉。处理办法就是用DNS负载均衡技术,它的原理是在DNS服务器中为同一个主机名配置多个IP地址,在应答DNS查询时,DNS服务器对每个查询将以DNS文件中主机记录的IP地址按顺序返回不同的解析结果,将客户端的访问引导到不同的机器上去,使得不同的客户端访问不同的服务器,从而达到负载均衡的目的。例如可以根据每台机器的负载量,该机器离用户地理位置的距离等等。
3、浏览器向 web 服务器发送一个 HTTP 请求
拿到域名对应的IP地址之后,浏览器会以一个随机端口(1024f8ae686db1f35f7683a9303aa0c45575 构建render树 -> 布局render树 -> 绘制render树
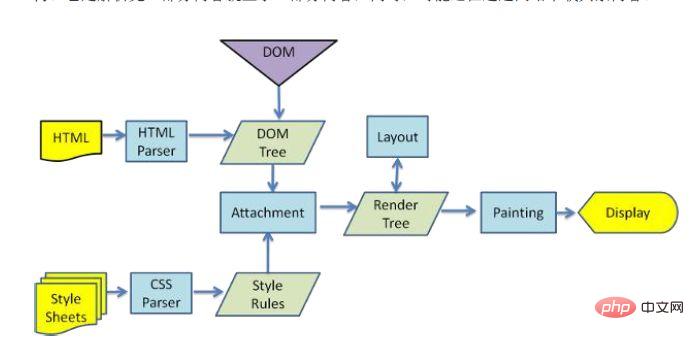
浏览器在解析html文件时,会”自上而下“加载,并在加载过程中进行解析渲染。在解析过程中,如果遇到请求外部资源时,如图片、外链的CSS、iconfont等,请求过程是异步的,并不会影响html文档进行加载。
解析过程中,浏览器首先会解析HTML文件构建DOM树,然后解析CSS文件构建渲染树,等到渲染树构建完成后,浏览器开始布局渲染树并将其绘制到屏幕上。这个过程比较复杂,涉及到两个概念: reflow(回流)和repain(重绘)。
DOM节点中的各个元素都是以盒模型的形式存在,这些都需要浏览器去计算其位置和大小等,这个过程称为relow;当盒模型的位置,大小以及其他属性,如颜色,字体,等确定下来之后,浏览器便开始绘制内容,这个过程称为repain。
页面在首次加载时必然会经历reflow和repain。reflow和repain过程是非常消耗性能的,尤其是在移动设备上,它会破坏用户体验,有时会造成页面卡顿。所以我们应该尽可能少的减少reflow和repain。
当文档加载过程中遇到js文件,html文档会挂起渲染(加载解析渲染同步)的线程,不仅要等待文档中js文件加载完毕,还要等待解析执行完毕,才可以恢复html文档的渲染线程。因为JS有可能会修改DOM,最为经典的document.write,这意味着,在JS执行完成前,后续所有资源的下载可能是没有必要的,这是js阻塞后续资源下载的根本原因。所以我明平时的代码中,js是放在html文档末尾的。
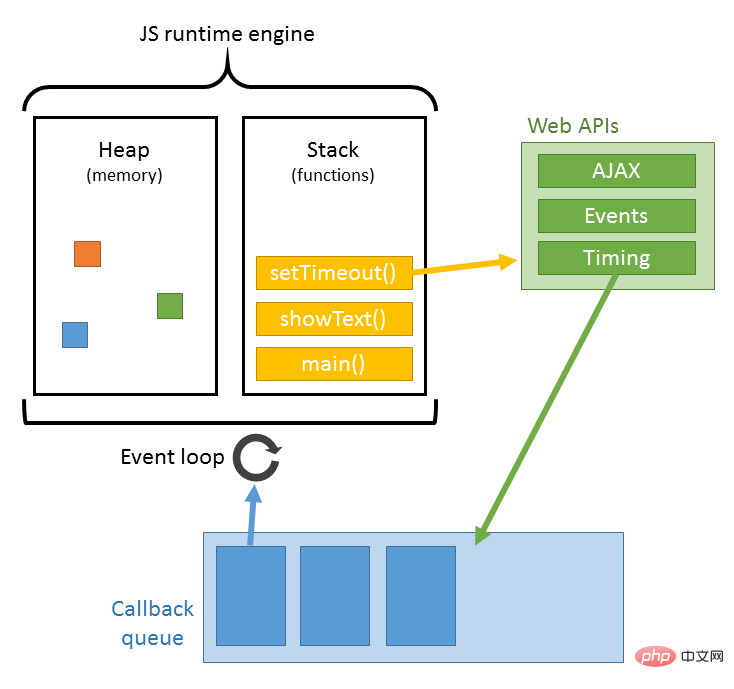
JS的解析是由浏览器中的JS解析引擎完成的,比如谷歌的是V8。JS是单线程运行,也就是说,在同一个时间内只能做一件事,所有的任务都需要排队,前一个任务结束,后一个任务才能开始。但是又存在某些任务比较耗时,如IO读写等,所以需要一种机制可以先执行排在后面的任务,这就是:同步任务(synchronous)和异步任务(asynchronous)。
JS的执行机制就可以看做是一个主线程加上一个任务队列(task queue)。同步任务就是放在主线程上执行的任务,异步任务是放在任务队列中的任务。所有的同步任务在主线程上执行,形成一个执行栈;异步任务有了运行结果就会在任务队列中放置一个事件;脚本运行时先依次运行执行栈,然后会从任务队列里提取事件,运行任务队列中的任务,这个过程是不断重复的,所以又叫做事件循环(Event loop)。具体的过程可以看我这篇文章:点击这里
9、浏览器发送请求获取嵌入在 HTML 中的资源(如图片、音频、视频、CSS、JS等等)
其实这个步骤可以并列在步骤8中,在浏览器显示HTML时,它会注意到需要获取其他地址内容的标签。这时,浏览器会发送一个获取请求来重新获得这些文件。比如我要获取外图片,CSS,JS文件等,类似于下面的链接:
图片:http://static.ak.fbcdn.net/rsrc.php/z12E0/hash/8q2anwu7.gif
CSS式样表:http://static.ak.fbcdn.net/rsrc.php/z448Z/hash/2plh8s4n.css
JavaScript 文件:http://static.ak.fbcdn.net/rsrc.php/zEMOA/hash/c8yzb6ub.js
这些地址都要经历一个和HTML读取类似的过程。所以浏览器会在DNS中查找这些域名,发送请求,重定向等等...
不像动态页面,静态文件会允许浏览器对其进行缓存。有的文件可能会不需要与服务器通讯,而从缓存中直接读取,或者可以放到CDN中
至此,从输入url到页面展示的过程终于整理完了。当然,文笔有限,有误之处,欢迎指出,本文参考了很多的文章,不过很多文章的链接不记得了,所以只列出了下面三个参考链接。
以上是面试必问:从输入url到页面展示到底发生了什么的详细内容。更多信息请关注PHP中文网其他相关文章!