
手把手教你使用Python网络爬虫获取基金信息
- Go语言进阶学习转载
- 2023-07-24 14:53:20996浏览
一、前言
前几天有个粉丝找我获取基金信息,这里拿出来分享一下,感兴趣的小伙伴们,也可以积极尝试。
二、数据获取
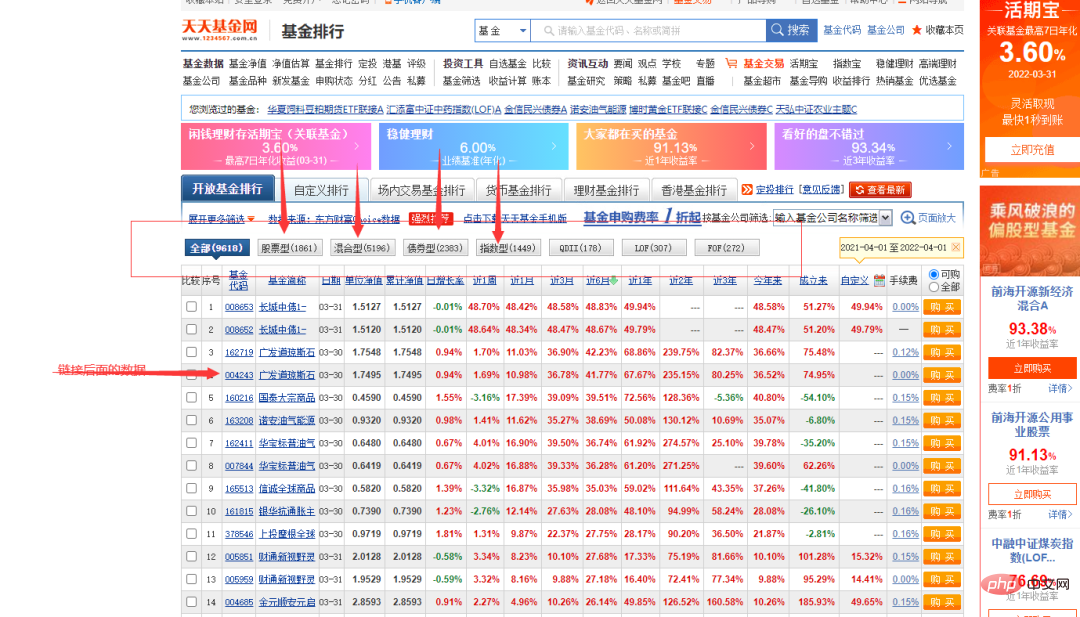
这里我们的目标网站是某基金官网,需要抓取的数据如下图所示。
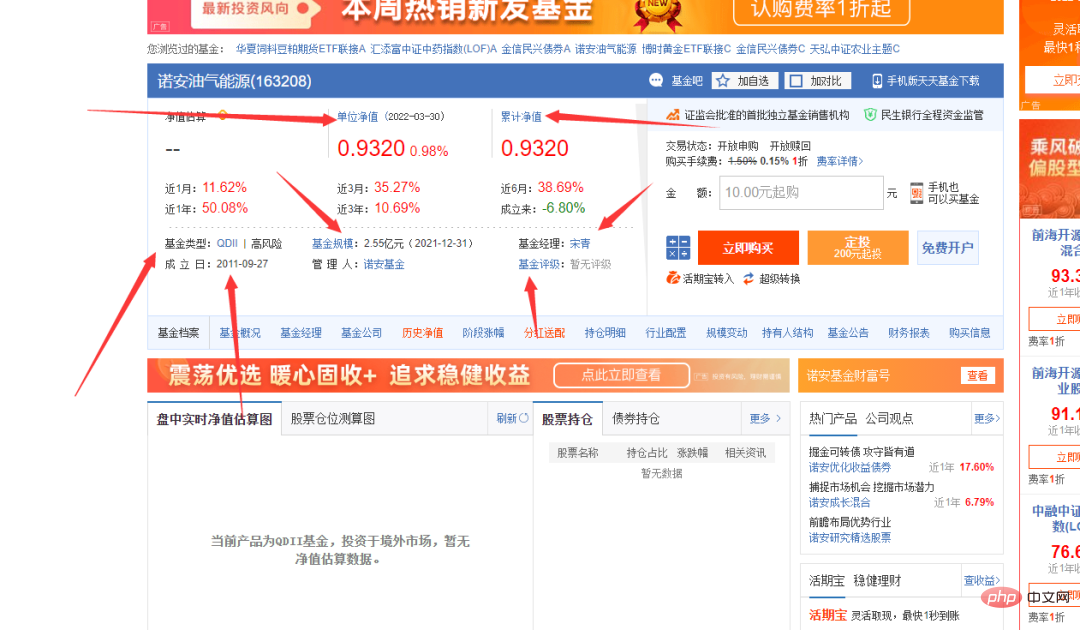 可以看到上图中基金代码那一列,有不同的数字,随机点击一个,可以进入到基金详情页,链接也非常有规律,以基金代码作为标志的。
可以看到上图中基金代码那一列,有不同的数字,随机点击一个,可以进入到基金详情页,链接也非常有规律,以基金代码作为标志的。
其实这个网站倒是不难,数据什么的,都没有加密,网页上的信息,在源码中都可以直接看到。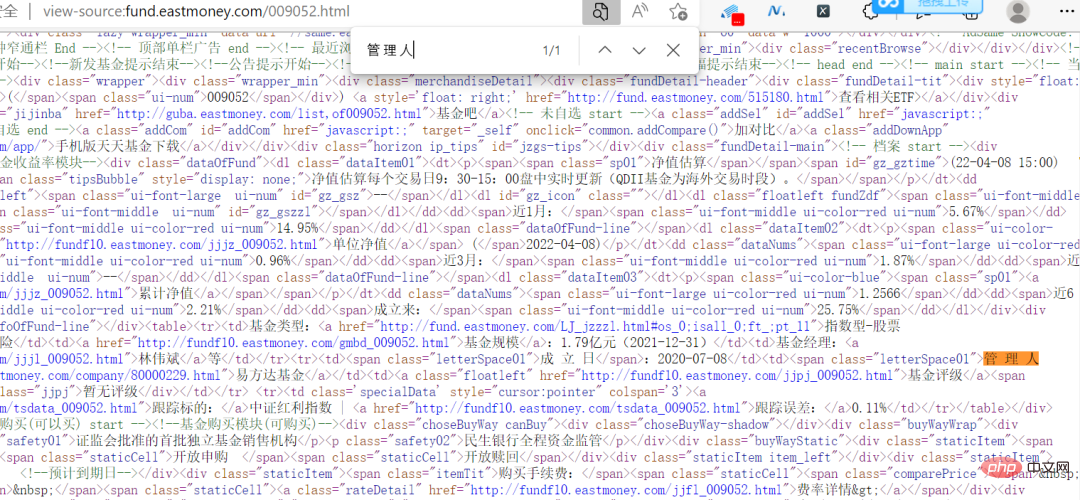
这样就降低了抓取难度了。通过浏览器抓包的方法,可以看到具体的请求参数,而且可以看到请求参数中只有pi在变化,而这个值恰好对应的是页面,直接构造请求参数就可以了。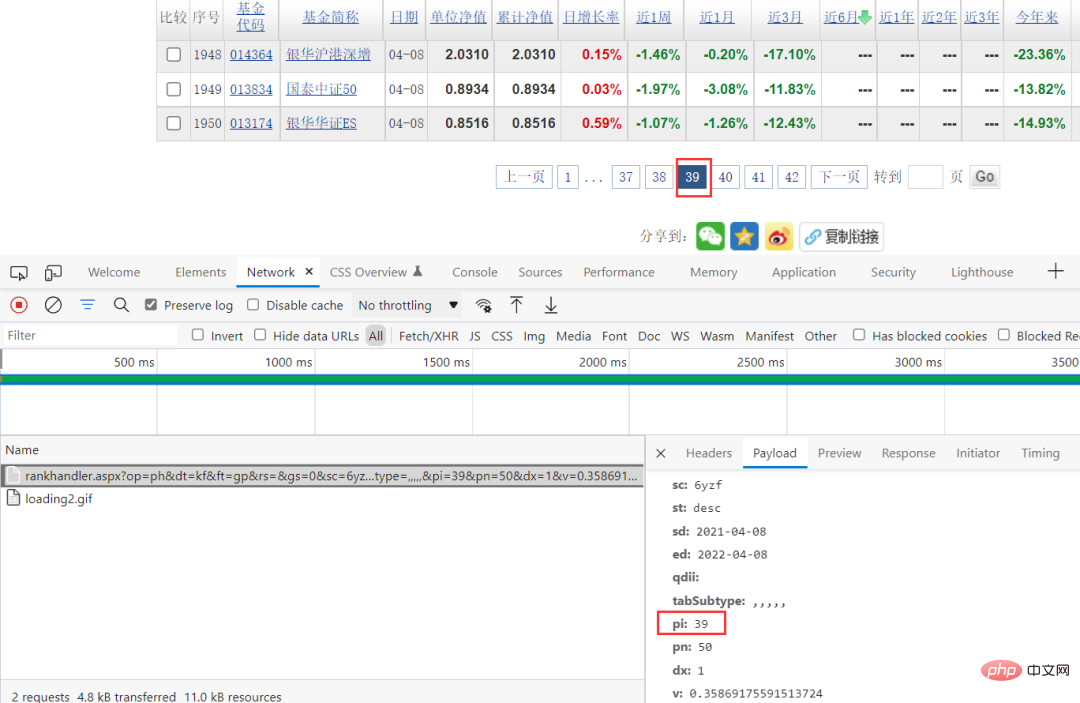
代码实现过程
找到数据源之后,接下来就是代码实现了,一起来看看吧,这里给出部分关键代码。
获取股票id数据
response = requests.get(url, headers=headers, params=params, verify=False)
pattern = re.compile(r'.*?"(?P<items>.*?)".*?', re.S)
result = re.finditer(pattern, response.text)
ids = []
for item in result:
# print(item.group('items'))
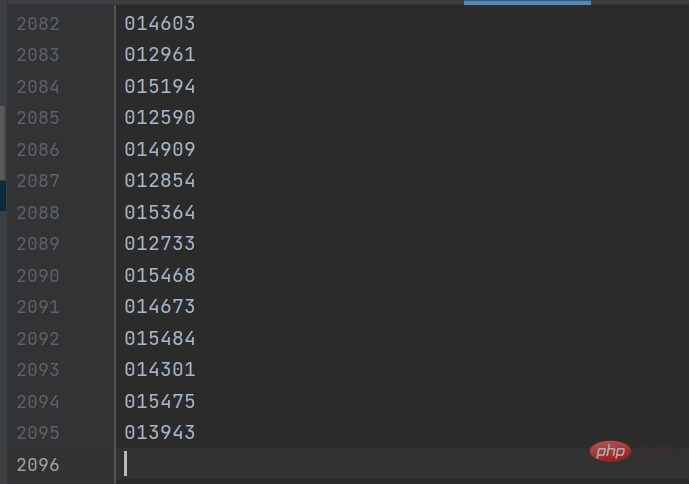
gp_id = item.group('items').split(',')[0]结果如下图所示:
之后构造详情页链接,获取详情页的基金信息,关键代码如下:
response = requests.get(url, headers=headers) response.encoding = response.apparent_encoding selectors = etree.HTML(response.text) danweijingzhi1 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[1]/text()')[0] danweijingzhi2 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[2]/text()')[0] leijijingzhi = selectors.xpath('//dl[@class="dataItem03"]/dd[1]/span/text()')[0] lst = selectors.xpath('//div[@class="infoOfFund"]/table//text()')
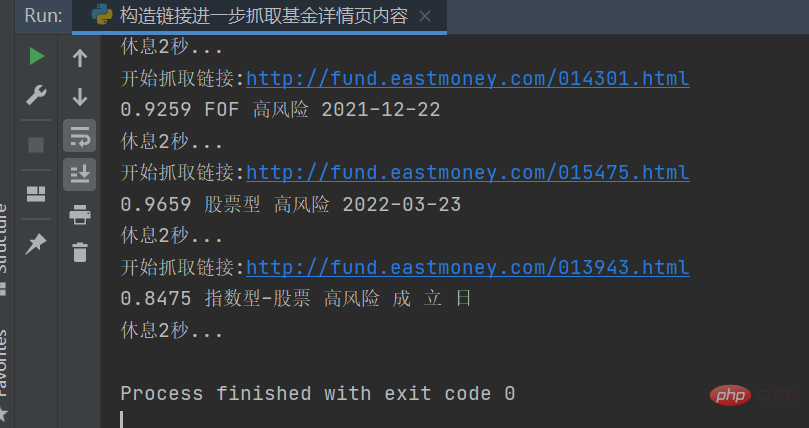
结果如下图所示:
 将具体的信息做相应的字符串处理,然后保存到
将具体的信息做相应的字符串处理,然后保存到csv文件中,结果如下图所示:
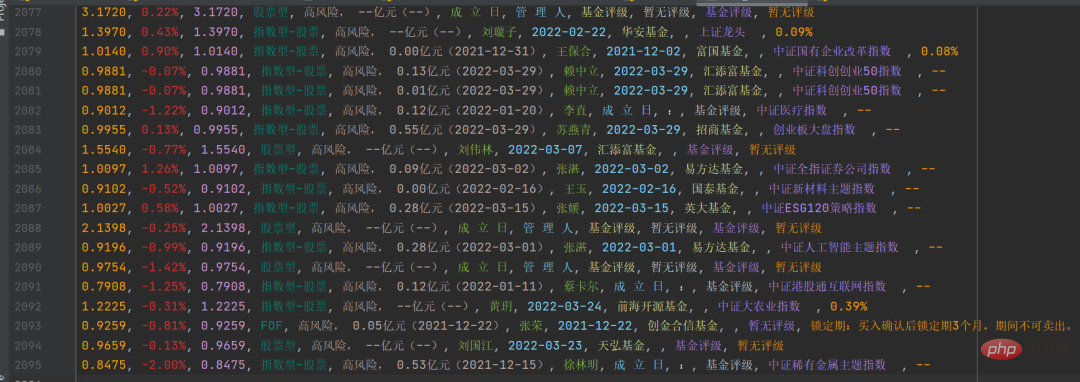 有了这个,你可以做进一步的统计和数据分析了。
有了这个,你可以做进一步的统计和数据分析了。
三、总结
大家好,我是Python进阶者。这篇文章主要分享了使用Python网络爬虫获取基金数据信息,这个项目不算太难,里边稍微有点小坑,欢迎大家积极尝试,如果有遇到问题,请添加我好友,我帮助解决。
这篇文章主要是以【股票型】的分类做了抓取,其他的类型,我就没做了,欢迎大家尝试,其实逻辑都是一样的,改下参数就可以了。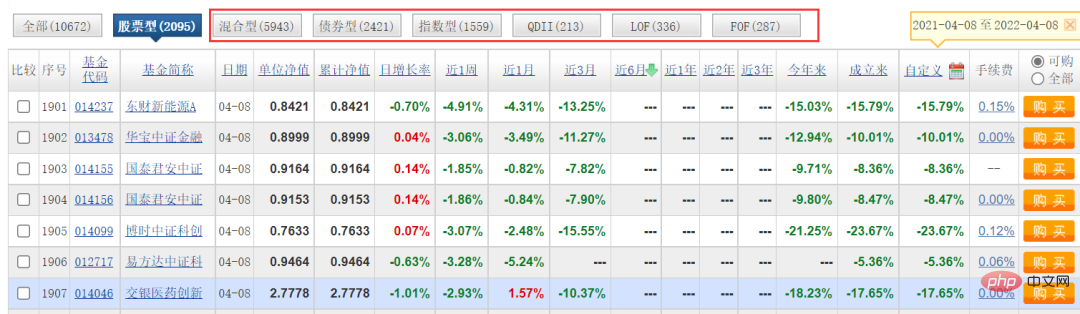
以上是手把手教你使用Python网络爬虫获取基金信息的详细内容。更多信息请关注PHP中文网其他相关文章!
声明:
本文转载于:Go语言进阶学习。如有侵权,请联系admin@php.cn删除