




背景介绍
实时音视频通信 RTC 在成为人们生活和工作中不可或缺的基础设施后,其中所涉及的各类技术也在不断演进以应对处理复杂多场景问题,比如音频场景中,如何在多设备、多人、多噪音场景下,为用户提供听得清、听得真的体验。
作为语音信号处理研究领域的旗舰国际会议,ICASSP (International Conference on Acoustics, Speech and Signal Processing) 一直代表着声学领域技术最前沿的研究方向。ICASSP 2023 收录了多篇和音频信号语音增强算法相关的文章,其中,火山引擎 RTC 音频团队共有 4 篇研究论文被大会接收,论文方向包括特定说话人语音增强、回声消除、多通道语音增强、音质修复主题。本文将介绍这 4 篇论文解决的核心场景问题和技术方案,分享火山引擎 RTC 音频团队在语音降噪、回声消除、干扰人声消除领域的思考与实践。
《基于频带分割循环神经网络的特定说话人增强》
论文地址:
https://www.php.cn/link/73740ea85c4ec25f00f9acbd859f861d
实时特定说话人语音增强任务有许多问题亟待解决。首先,采集声音的全频带宽度提高了模型的处理难度。其次,相比非实时场景,实时场景下的模型更难定位目标说话人,如何提高说话人嵌入向量和语音增强模型的信息交互是实时处理的难点。受到人类听觉注意力的启发,火山引擎提出了一种引入说话人信息的说话人注意力模块(Speaker Attentive Module,SAM),并将其和单通道语音增强模型-频带分割循环神经网络(Band-split Recurrent Neural Network,BSRNN) 融合,构建特定人语音增强系统来作为回声消除模型的后处理模块,并对两个模型的级联进行优化。
模型框架结构
频带分割循环神经网络(BSRNN)

频带分割循环神经网络(Band-split RNN, BSRNN)是全频带语音增强和音乐分离的 SOTA 模型,其结构如上图所示。BSRNN 由三个模块组成,分别是频带分割模块(Band-Split Module)、频带序列建模模块(Band and Sequence Modeling Module)和频带合并模块(Band-Merge Module)。频带分割模块首先将频谱分割为 K 个频带,每个频带的特征通过批归一化(BN)后,被 K 个全连接层(FC)压缩到相同的特征维度 C 。随后,所有频带的特征被拼接为一个三维张量并由频带序列建模模块进一步处理,该模块使用 GRU 交替建模特征张量的时间和频带维度。经过处理的特征最后经过频带合并模块得到最后的频谱掩蔽函数作为输出,将频谱掩蔽和输入频谱相乘即可得到增强语音。为了构建特定说话人的语音增强模型,我们在每个频带序列的建模模块后都添加了说话人注意力模块。
说话人注意力机制模块 (SAM)

说话人注意力模块(Speaker Attentive Module)的结构如上图。其核心思想是使用说话人嵌入向量 e 作为语音增强模型中间特征的吸引子,计算其和中间特征所有时间和频带上的相关度 s,称作注意力值。该注意力值将被用于对中间特征 h 进行缩放规整。其具体公式如下:
首先通过全连接和卷积将 e 和 h 变换为 k 和 q:
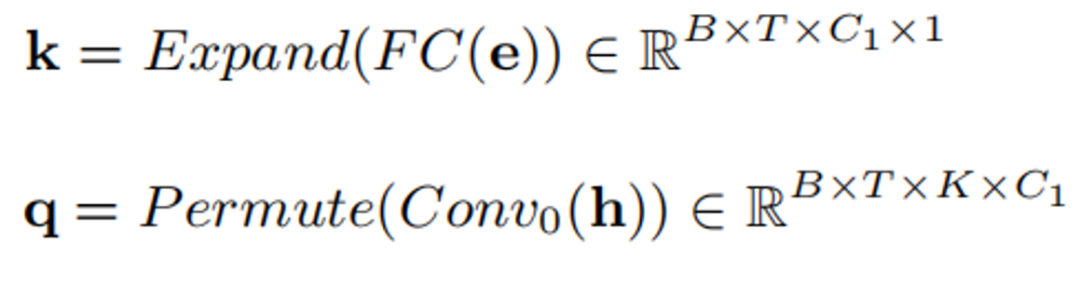
k 和 q 相乘得到注意力值:
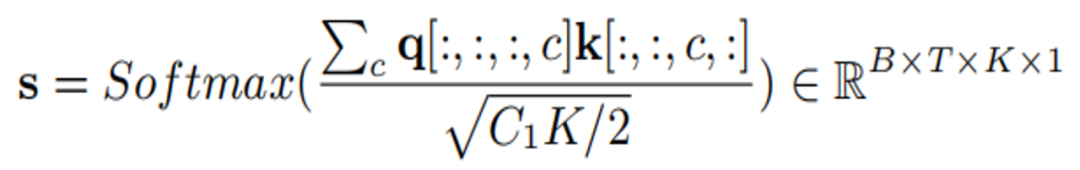
最后通过该注意力值缩放原始特征:
模型训练数据
关于模型训练数据,我们采用了第五届 DNS 特定说话人语音增强赛道的数据以及 DiDispeech 的高质量语音数据,通过数据清洗,得到约 3500 个说话人的清晰语音数据。在数据清洗方面,我们使用了基于 ECAPA-TDNN[1]说话人识别的预训练模型来去除语音数据中残留的干扰说话人语音,同时使用第四届 DNS 挑战赛第一名的预训练模型来去除语音数据中的残留噪声。在训练阶段,我们生成了超过 10 万条 4s 的语音数据,对这些音频添加混响以模拟不同信道,并随机和噪声、干扰人声混合,设置成一种噪声、两种噪声、噪声和干扰说话人以及仅有干扰说话人 4 种干扰场景。同时,含噪语音和目标语音的电平将随机缩放,以便模拟不同大小的输入。
《融合特定说话人提取与回声消除技术方案》
论文地址:
https://www.php.cn/link/7c7077ca5231fd6ad758b9d49a2a1eeb
回声消除一直是外放场景中一个极其复杂且至关重要的问题。为了能够提取出高质量的近端干净语音信号,火山引擎提出了一种结合信号处理与深度学习技术的轻量化回声消除系统。在特定说话人降噪(Personalized Deep Noise Suppression, pDNS ) 基础上,我们进一步构建了特定说话人回声消除(Personalized Acoustic Echo Cancellation, pAEC)系统,其包括一个基于数字信号处理的前处理模块、一个基于深度神经网络的两阶段模型和一个基于 BSRNN 和 SAM 的特定说话人语音提取模块。

特定说话人回声消除总体框架
基于数字信号处理线性回声消除的前处理模块
前处理模块主要包含两部分:时延补偿(TDC)和线性回声消除(LAEC),该模块均在子带特征上进行。

基于信号处理子带线性回声消除算法框架
时延补偿
TDC 基于子带互相关,其首先分别在每个子带中估计出一个时延,然后使用投票方法来确定最终时间延迟。
线性回声消除
LAEC 是一种基于 NLMS 的子带自适应滤波方法,由两个滤波器组成:前置滤波器(Pre-filter)和后置滤波器(Post-filter),后置滤波器使用动态步长进行自适应更新参数,前置滤波器是状态稳定的后置滤波器的备份。根据前置滤波器和后置滤波器输出的残余能量进行比较,最终决定选用哪一个误差信号。

LAEC 处理流程图
基于多级卷积-循环卷积神经网络(CRN)的两阶段模型
我们建议将 pAEC 任务进行解耦,拆分成“回声抑制”和“特定说话人提取”两个任务,以减轻模型建模压力。因此,后处理网络主要由两个神经网路模块组成:用于初步回声消除和噪声抑制的基于 CRN 的轻量级模块,以及用于更好的近端语音信号重建的基于 pDNS 的后处理模块。
第一阶段:基于CRN的轻量级模块
基于 CRN 的轻量级模块由一个频带压缩模块、一个编码器、两个双路径 GRU、一个解码器和一个频带分解模块组成。同时,我们还引入了一个语音活动检测(Voice Activity Detection, VAD)模块用于多任务学习,有助于提高对近端语音的感知。CRN 取压缩幅度为输入,输出初步的目标信号的复数理想比掩码(cIRM)和近场 VAD 概率。
第二阶段:基于pDNS的后处理模块
这个阶段的 pDNS 模块包括了上述介绍的频带分割循环神经网络 BSRNN 和说话人注意力机制模块 SAM,级联模块以串联的方式接在轻量级 CRN 模块之后。由于我们的 pDNS 系统在特性说话人语音增强任务上达到了较为优异的性能,我们将一个预训练好的 pDNS 模型参数作为模型的第二阶段初始化参数,对前一阶段的输出进一步处理。
级联系统训练优化损失函数
我们通过级联优化的方式来改进两阶段模型,使其在第一阶段能够预测近端语音,在第二阶段能够预测特定说话人的近端语音。我们还加入了一个靠近讲话者的语音活动检测罚项,以增强模型对近距离说话的识别能力。具体损失函数定义如下:

其中,
分别对应模型第一阶段和第二阶段预测的 STFT 特征, 分别表示近端语音和近端特定说话人语音的 STFT 特征,
分别表示模型预测和目标 VAD 状态。
模型训练数据
为了使回声消除系统可以处理多设备,多混响,多噪音采集场景的回声,我们通过混合回声和干净语音,得到 2000+ 小时的训练数据,其中,回声数据使用 AEC Challenge 2023 远端单讲数据,干净语音来自 DNS Challenge 2023 和 LibriSpeech,用于模拟近端混响的 RIR 集合来自 DNS Challenge。由于 AEC Challenge 2023 远端单讲数据中的回声存在少量噪声数据,直接用这些数据作为回声容易导致近端语音失真,为了缓解这个问题,我们采用了一种简单但有效的数据清理策略,使用预训练的一个 AEC 模型处理远端单讲数据,将具有较高残余能量的数据识别为噪声数据,并反复迭代下图清洗流程。
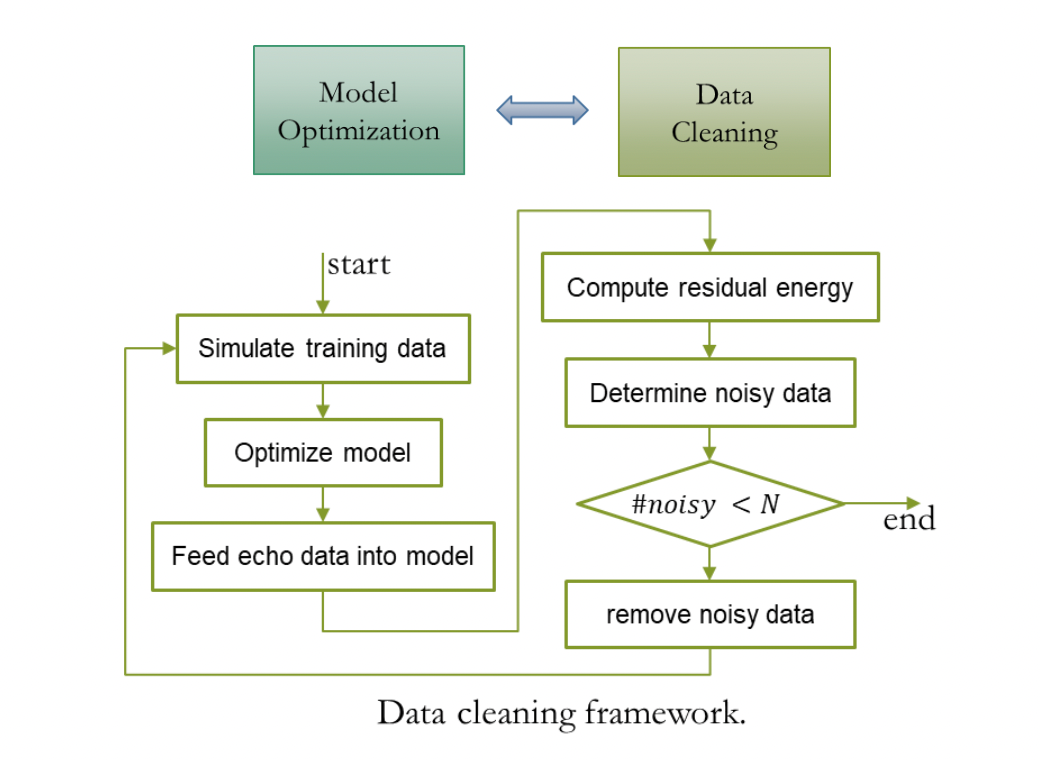
级联优化方案系统效果
这样的一套基于融合回声消除与特定说话人提取的语音增强系统在 ICASSP 2023 AEC Challenge 盲测试集 [2] 上验证了它在主客观指标上的优势——取得了 4.44 的主观意见分(Subjective-MOS)和 82.2%的语音识别准确率(WAcc)。

《基于傅立叶卷积注意力机制的多通道语音增强》
论文地址:
https://www.php.cn/link/373cb8cd58cad5f1309b31c56e2d5a83
基于深度学习的波束权值估计是目前解决多通道语音增强任务的主流方法之一,即通过网络求解波束权值来对多通道信号进行滤波从而获得纯净语音。波束权值的估计中,频谱信息和空间信息的作用类似于传统的波束形成算法中求解空间协方差矩阵的原理。然而,现有许多神经波束形成器都无法对波束权值进行最优估计。为处理这一挑战,火山引擎提出了一种傅里叶卷积注意力编码器(Fourier Convolutional Attention Encoder, FCAE),该编码器能在频率特征轴上提供全局感受野,加强对频率轴上下文特征的提取。同时,我们也提出了一种基于 FCAE 的卷积循环编解码器(Convolutional Recurrent Encoder-Decoder, CRED)的结构用来从输入特征中捕捉频谱上下文特征和空间信息。
模型框架结构
波束权值估计网络

该网络借助嵌入波束网络(Embedding and Beamforming Network,EaBNet)的结构范式,将网络分为嵌入模块和波束模块两个部分,嵌入模块用来提取聚合频谱和空间信息的嵌入向量,并将该嵌入向量送入波束部分导出波束权值。这里采用一个 CRED 结构来学习嵌入张量,多通道输入信号经过 STFT 变换后,送入一个 CRED 结构提取嵌入张量,该嵌入张量类似传统波束形成中的空间协方差矩阵,包含可区分语音和噪声的特征。嵌入张量经过 LayerNorm2d 结构,再经过两层堆叠的 LSTM 网络,最后通过一个线性层导出波束权值。我们对该波束权值作用于多通道输入频谱特征上,进行滤波求和操作,最后得到纯净语音谱,经过 ISTFT 变换即可得到目标时域波形。
CRED结构
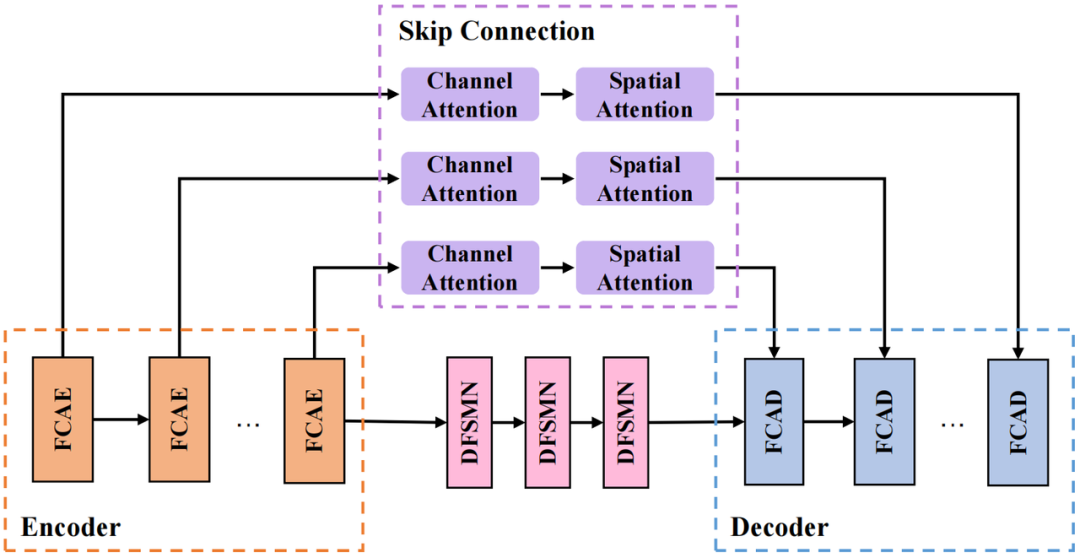
我们采用的 CRED 结构如上图所示。其中,FCAE 为傅里叶卷积注意力编码器,FCAD 为与 FCAE 对称的解码器;循环模块采用深度前馈顺序记忆网络(Deep Feedward Sequential Memory Network,DFSMN)对序列的时序依赖进行建模,在不影响模型性能的基础上减小模型尺寸;跳连接部分采用串联的通道注意力(Channel Attention)和空间注意力(Spatial Attention)模块,用来进一步提取跨通道间的空间信息,并连接深层特征与浅层特征,方便信息在网路中的传输。
FCAE结构
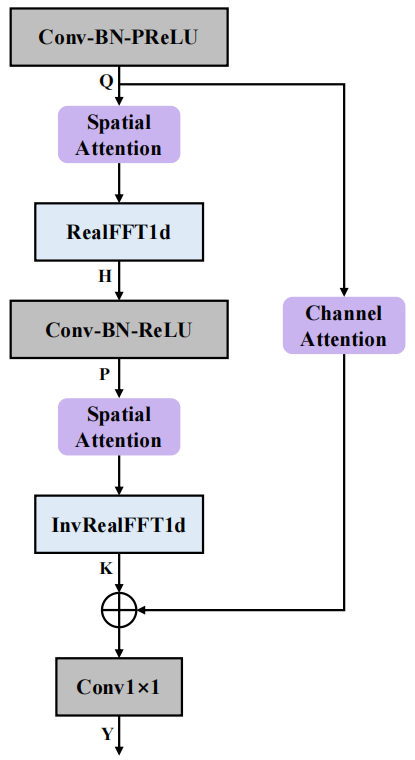
傅里叶卷积注意力编码器(FCAE)的结构如上图所示。该模块受傅里叶卷积算子[3]的启发,利用离散傅里叶变换在变换域上的任意一点的更新将会对原始域的信号产生全局影响的特点,对频率轴特征进行一维 FFT 变换,即可在频率轴上获得全局感受野,进而加强对频率轴上下文特征的提取。此外,我们引入了空间注意力模块和通道注意力模块,进一步增强卷积表达能力,提取有利的频谱-空间联合信息,增强网络对纯净语音和噪声可区分特征的学习。在最终表现上,该网络以仅 0.74M 的参数量取得了优异的多通道语音增强效果。
模型训练数据
数据集方面,我们采用了 ConferencingSpeech 2021 比赛提供的开源数据集,纯净语音数据包含 AISHELL-1、AISHELL-3、VCTK 以及 LibriSpeech(train-clean-360),挑选其中信噪比大于 15dB 的数据用于生成多通道混合语音,噪声数据集采用 MUSAN、AudioSet。同时,为了模拟实际多房间混响场景,通过模拟改变房间尺寸、混响时间、发声源,噪声源位置等方式将开源的数据与超过 5000 个房间脉冲响应进行卷积,最终生成 6 万条以上多通道训练样本。
《基于两阶段神经网络模型的音质修复系统》
论文地址:
https://www.php.cn/link/e614f646836aaed9f89ce58e837e2310
火山引擎还在音质修复方面进行了一些尝试,包括增强特定说话人的语音、消除回声和增强多通道音频。在实时通信过程中,出现的不同形式的失真都会对语音信号的质量产生影响,导致语音信号的清晰度和可理解性下降。火山引擎提出了一个两阶段模型,该模型采用分阶段的分治策略,以修复各种影响语音质量的失真。
模型框架结构
下图为两阶段模型整体框架构图,其中,第一阶段模型主要修复频谱缺失的部分,第二阶段模型则主要抑制噪声、混响以及第一阶段模型可能产生的伪影。

第一阶段模型:Repairing Net
整体采用深度复数卷积循环神经网络 (Deep Complex Convolution Recurrent Network, DCCRN)[4]架构,包括 Encoder、时序建模模块和 Decoder 三个部分。受图像修复的启发,我们引入了 Gate 复值卷积和 Gate 复值转置卷积代替 Encoder 和 Decoder 中的复值卷积和复值转置卷积。为了进一步提升音频修补部分的自然度,我们引入了 Multi-Period Discriminator和 Multi-Scale Discriminator 用于辅助训练。
第二阶段模型:Denoising Net
整体采用 S-DCCRN 架构,包括 Encoder、两个轻量级 DCCRN 子模块和 Decoder 三个部分,其中两个轻量级 DCCRN 子模块分别进行子带和全带建模。为了提升模型在时域建模方面的能力,我们将 DCCRN子 模块中的 LSTM 替换为 Squeezed Temporal Convolutional Module(STCM)。
模型训练数据
这里用来训练来音质修复的干净音频、噪声、混响均来自 2023 DNS 竞赛数据集,其中干净音频总时长为 750 小时,噪声总时长为 170 小时。在第一阶段模型的数据增广时,我们一方面利用全带音频与随机生成的滤波器进行卷积, 20ms 为窗长将音频采样点随机置零和对音频随机进行降采样来模拟频谱缺失缺陷,另一方面在音频幅度频与音频采集点上分别乘以随机尺度;在第二阶段的数据增广时,我们利用第一阶段已经生成的数据,再卷积各种类型的房间冲激响应得到不同混响程度的音频数据。
音频处理效果
在 ICASSP 2023 AEC Challenge中,火山引擎 RTC 音频团队,在通用回声消除 (Non-personalized AEC) 与特定说话人回声消除 (Personalized AEC) 两个赛道上荣获冠军,并在双讲回声抑制,双讲近端语音保护、近端单讲背景噪声抑制、综合主观音频质量打分及最终语音识别准确率等多项指标上显著优于其他参赛队伍,达到国际领先水平。
我们来看一下经过上述技术方案后,火山引擎 RTC 在不同场景下的语音增强处理效果。
不同信噪回声比场景下的回声消除
下面两个例子分别展示了回声消除算法在不同信号回声能量比例场景下处理前后的对比效果。
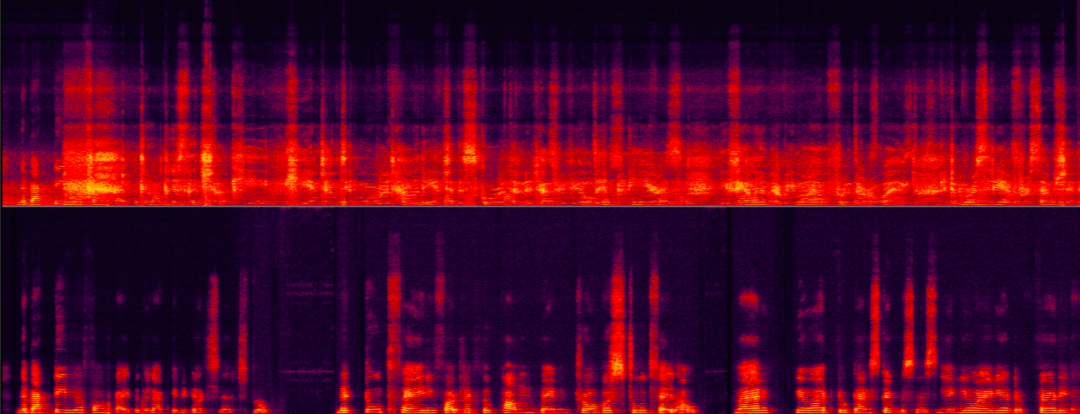
中等信回声比场景
超低信回比场景对回声消除的挑战性最大,此时我们不仅需要有效去除大能量的回声,还需要同时最大程度保留微弱的目标语音。非目标说话人语音(回声)几乎完全盖过了目标说话人(女声)的语音,使其难以识别。
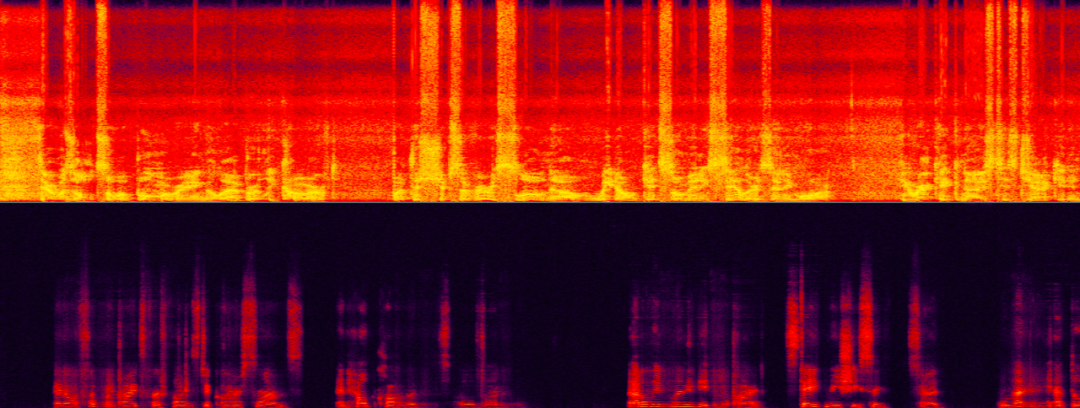
超低信回声比场景
不同背景干扰说话人场景下的说话人提取
下面两个例子分别展示了特定说话人提取算法在噪音与背景人干扰场景下处理前后的对比效果。
如下样本中,特定说话人既有类似门铃的噪声干扰,又有背景人说话噪声干扰,仅使用 AI 降噪只能去除门铃噪声,因此还需要针对特定说话人进行人声消除。
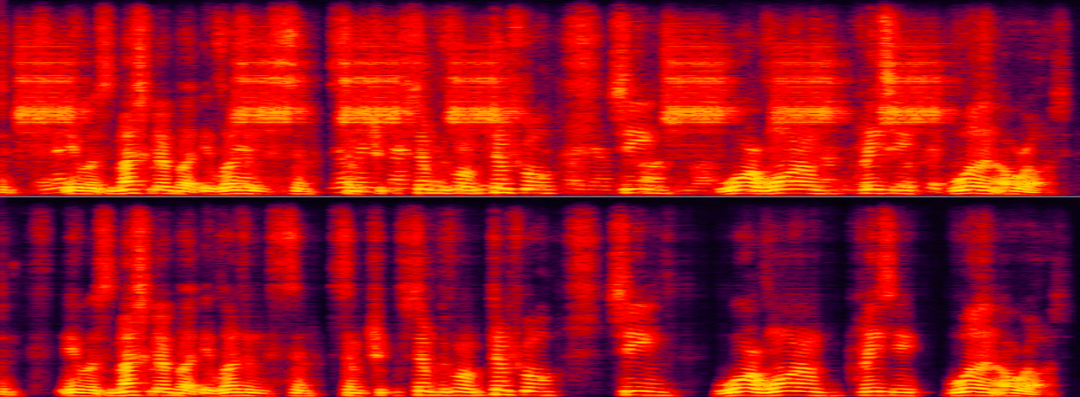
目标说话人与背景干扰人声及噪音
当目标说话人声和背景干扰人声的声纹特征很接近时,此时对于特定说话人提取算法的挑战更大,更能考验特定说话人提取算法鲁棒性。如下样本中,目标说话人和背景干扰人声是两个相似的女声。

目标女声与干扰女声混合
总结与展望
上述介绍了火山引擎 RTC 音频团队基于深度学习在特定说话人降噪,回声消除,多通道语音增强等方向做出的一些方案及效果,未来场景依然面临着多个方向的挑战,如语音降噪如何自适应噪音场景,音质修复如何在更广范围对音频信号进行多类型修复以及怎么样各类终端上运行轻量低复杂度模型,这些挑战点也将会是我们后续重点的研究方向。
以上是解密实时通话中基于 AI 的一些语音增强技术的详细内容。更多信息请关注PHP中文网其他相关文章!


 优化您的组织与Genai代理商的电子邮件营销Apr 13, 2025 am 11:44 AM
优化您的组织与Genai代理商的电子邮件营销Apr 13, 2025 am 11:44 AM介绍 恭喜!您经营一家成功的业务。通过您的网页,社交媒体活动,网络研讨会,会议,免费资源和其他来源,您每天收集5000个电子邮件ID。下一个明显的步骤是
 Apache Pinot实时应用程序性能监视Apr 13, 2025 am 11:40 AM
Apache Pinot实时应用程序性能监视Apr 13, 2025 am 11:40 AM介绍 在当今快节奏的软件开发环境中,确保最佳应用程序性能至关重要。监视实时指标,例如响应时间,错误率和资源利用率可以帮助MAIN
 Chatgpt击中了10亿用户? Openai首席执行官说:'短短几周内翻了一番Apr 13, 2025 am 11:23 AM
Chatgpt击中了10亿用户? Openai首席执行官说:'短短几周内翻了一番Apr 13, 2025 am 11:23 AM“您有几个用户?”他扮演。 阿尔特曼回答说:“我认为我们上次说的是每周5亿个活跃者,而且它正在迅速增长。” “你告诉我,就像在短短几周内翻了一番,”安德森继续说道。 “我说那个私人
 pixtral -12b:Mistral AI'第一个多模型模型 - 分析VidhyaApr 13, 2025 am 11:20 AM
pixtral -12b:Mistral AI'第一个多模型模型 - 分析VidhyaApr 13, 2025 am 11:20 AM介绍 Mistral发布了其第一个多模式模型,即Pixtral-12b-2409。该模型建立在Mistral的120亿参数Nemo 12B之上。是什么设置了该模型?现在可以拍摄图像和Tex
 生成AI应用的代理框架 - 分析VidhyaApr 13, 2025 am 11:13 AM
生成AI应用的代理框架 - 分析VidhyaApr 13, 2025 am 11:13 AM想象一下,拥有一个由AI驱动的助手,不仅可以响应您的查询,还可以自主收集信息,执行任务甚至处理多种类型的数据(TEXT,图像和代码)。听起来有未来派?在这个a




热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

SublimeText3 Linux新版
SublimeText3 Linux最新版

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

记事本++7.3.1
好用且免费的代码编辑器

