



一切都要从 ChatGPT 的横空出世说起......
曾经一片祥和的 NLP 社区,被这个突如其来的 “怪物” 吓到了!一夜之间,整个 NLP 圈发生了巨大的变化,工业界迅速跟进,资本 “狂飙”,开始了复刻 ChatGPT 之路;学术界突然陷入了一片迷茫的状态......大家慢慢开始相信 “NLP is solved!”
然而,从最近依然活跃的 NLP 学术圈和层出不穷的优秀工作来看,事实并非如此,甚至可以说 “NLP just got real!”
这几个月,北航、Mila、香港科技大学、苏黎世联邦理工学院(ETH)、滑铁卢大学、达特茅斯学院、谢菲尔德大学、中科院等多家机构,经过系统、全面的调研之后,打磨出一篇 110 页的论文,系统阐述了后 ChatGPT 时代的技术链:交互。

- 论文地址:https://arxiv.org/abs/2305.13246
- 项目资源:https://github.com/InteractiveNLP-Team
与传统的 “人在环路(HITL)”、“写作助手” 等类型的交互不同,本文所讨论的交互,有着更高、更全面的视角:
-
对工业界:如果大模型有事实性、时效性等难以解决的问题,那 ChatGPT+X 能否解决呢?甚至就像 ChatGPT Plugins 那样,让它和工具交互帮我们一步到位订票、订餐、画图!也就是说,我们可以通过一些系统化的技术框架缓解当下大模型的一些局限。
- 对学术界:什么是真正的 AGI?其实早在 2020 年,深度学习三巨头、图灵奖获得者 Yoshua Bengio 就描绘了交互型语言模型的蓝图 [1]:一个可以和环境交互,甚至可以和其他智能体进行社会交互的语言模型,才能有最为全面的语言语义表示。在某种程度上,与环境、与人的交互造就了人类智慧。
因此,让语言模型(LM)与外部实体以及自我进行交互,不仅仅可以帮助弥合大模型的固有缺陷,还可能是通往 AGI 的终极理想的一个重要的里程碑!
什么是交互?
其实 “交互” 的概念并不是作者们臆想的。自从 ChatGPT 问世之后,诞生了很多关于 NLP 界新问题的论文,比如:
- Tool Learning with Foundation Models 阐述了让语言模型使用工具进行推理或者执行现实操作 [2];
- Foundation Models for Decision Making: Problems, Methods, and Opportunities 阐述了如何使用语言模型执行决策任务 (decision making)[3];
- ChatGPT for Robotics: Design Principles and Model Abilities 阐述了如何使用 ChatGPT 赋能机器人 [4];
- Augmented Language Models: a Survey 阐述了如何使用思维链 (Chain of Thought)、工具使用(Tool-use)等增强语言模型,并指出了语言模型使用工具可以给外部世界产生实际的影响(即 act)[5];
- Sparks of Artificial General Intelligence: Early experiments with GPT-4 阐述了如何使用 GPT-4 执行各种类型的任务,其中包括了与人、环境、工具等交互的案例 [6]。
可见,NLP 学界的关注点,逐渐从 “怎么打造模型”,过渡到了 “怎么打造框架”,也就是将更多的实体纳入到语言模型训练、推理的过程当中。最为典型的例子就是大家所熟知的 Reinforcement Learning from Human Feedback (RLHF), 基本原理就是让语言模型从与人的交互(反馈)中进行学习 [7],这一思想成为了 ChatGPT 画龙点睛的一笔。
因此可以说,“交互” 这个特性,是 ChatGPT 之后,NLP 最为主流的技术发展路径之一!作者们的论文首次定义并系统解构了 “交互式 NLP”,并主要基于交互对象的维度,尽可能全面地讨论了各种技术方案的优劣以及应用上的考虑,包括:

- LM 与人类交互,以更好地理解和满足用户需求,个性化回应,与人类价值观对齐 (alignment),并改善整体用户体验;
- LM 与知识库交互,以丰富语言表达的事实知识,增强回应的知识背景相关性,并动态利用外部信息生成更准确的回应;
- LM 与模型和工具交互,以有效分解和解决复杂推理任务,利用特定知识处理特定子任务,并促进智能体社会行为的涌现;
- LM 与环境交互,以学习基于语言的实体表征(language grounding),并有效地处理类似推理、规划和决策等与环境观察相关的具身任务(embodied tasks)。
因此,在交互的框架下,语言模型不再是语言模型本身,而是一个可以 “看”(observe)、可以 “动作”(act)、可以 “获取反馈”(feedback) 的基于语言的智能体。
与某个对象进行交互,作者们称之为 “XXX-in-the-loop”, 表示这个对象参与了语言模型训练或者推理的过程,并且是以一种级联、循环、反馈、或者迭代的形式参与其中的。
与人交互

让语言模型与人交互可以分为三种方式:
- 使用提示进行交流
- 使用反馈进行学习
- 使用配置进行调节
另外,为了保证可规模化的部署,往往采用模型或者程序模拟人类的行为或者偏好,即从人类模拟中学习。
总的来说,与人交互要解决的核心问题是对齐问题 (alignment), 也就是如何让语言模型的响应更加符合用户的需要,更加有帮助、无害且有理有据,能让用户有更好的使用体验等。
“使用提示进行交流” 主要着重于交互的实时性和持续性,也就是强调连续性质的多轮对话。这一点和 Conversational AI [8] 的思想是一脉相承的。也就是,通过多轮对话的方式,让用户连续地问下去,让语言模型的响应在对话中慢慢地对齐于用户偏好。这种方式通常在交互中不需要模型参数的调整。
“使用反馈进行学习” 是当前进行 alignment 的主要方式,也就是让用户给语言模型的响应一个反馈,这种反馈可以是描述偏好的 “好 / 坏” 的标注,也可以是自然语言形式的更为详细的反馈。模型需要被训练,以让这些反馈尽可能地高。比较典型的例子就是 InstructGPT 所使用的 RLHF [7],首先使用用户标注的对模型响应的偏好反馈数据训练奖励模型,然后使用这个奖励模型以某种 RL 算法训练语言模型以最大化奖励(如下图)。
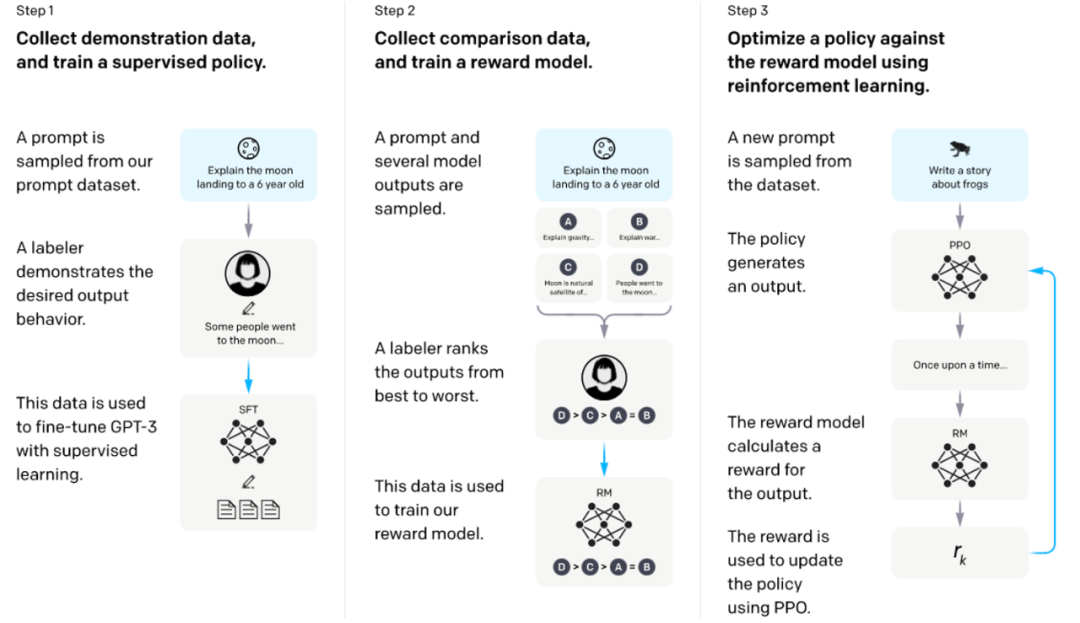
Training language models to follow instructions with human feedback [7]
“使用配置进行调节” 是一种比较特殊的交互方式,允许用户直接调整语言模型的超参数(比如 temperature)、或者语言模型的级联方式等。典型的例子比如谷歌的 AI Chains [9], 带有不同预设 prompt 的语言模型互相连接构成了一个用于处理流程化任务的推理链条,用户可以通过一个 UI 拖拽调整这个链条的节点连接方式。
“从人类模拟中学习” 可以促进上述三种方式的规模化部署,因为尤其在训练过程,使用真实的用户是不现实的。比如 RLHF 通常需要使用一个 reward model 来模拟用户的偏好。另一个例子是微软研究院的 ITG [10], 通过一个 oracle model 来模拟用户的编辑行为。
最近,斯坦福 Percy Liang 教授等人构建了一个非常系统化的 Human-LM 交互的评测方案:Evaluating Human-Language Model Interaction [11], 感兴趣的读者可以参考本论文或者原文。
与知识库交互

语言模型与知识库交互存在三个步骤:
- 确定补充知识的来源:Knowledge Source
- 检索知识:Knowledge Retrieval
- 使用知识进行增强:详细请参阅本论文 Interaction Message Fusion 部分,这里不多做介绍。
总的来说,与知识库进行交互可以减轻语言模型的 “幻觉” 现象 (hallucination), 即提升其输出的事实性、准确性等,还能帮助改善语言模型的时效性问题,帮助补充语言模型的知识能力(如下图)等。
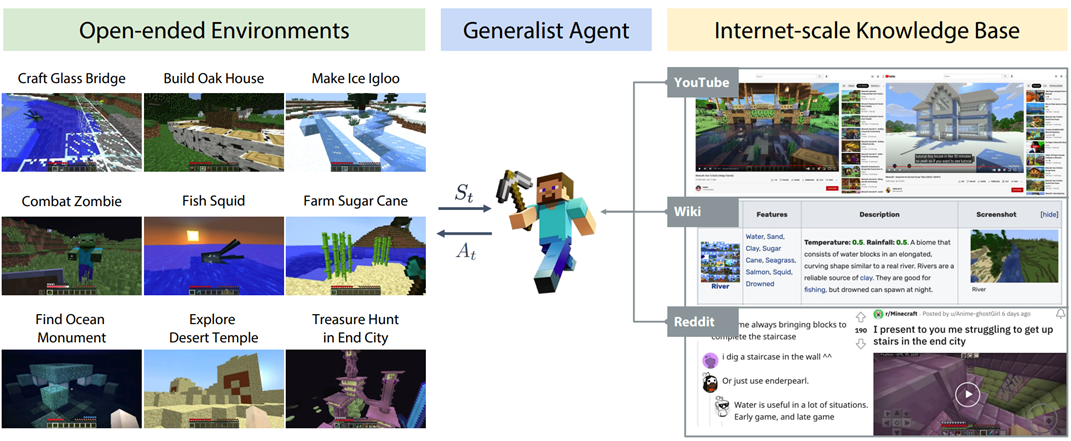
MineDojo [16]:当一个语言模型智能体遇到不会的任务,可以从知识库中查找学习资料,然后在资料的帮助下,完成这个任务。
“Knowledge Source” 分为两种,一种是封闭的语料知识 (Corpus Knowledge), 如 WikiText 等 [15];另一种是开放的网络知识 (Internet Knowledge), 比如使用搜索引擎可以得到的知识 [14]。
“Knowledge Retrieval” 分为四种方式:
- 基于语言的稀疏表示以及 lexical matching 的稀疏检索 (sparse retrieval):如 n-gram 匹配,BM25 等。
- 基于语言的稠密表示以及 semantic matching 的稠密检索 (dense retrieval):如使用单塔或者双塔模型作为检索器等。
- 基于生成式检索器:属于比较新的方式,代表工作是谷歌 Tay Yi 等人的 Differentiable Search Index [12], 将知识都保存在语言模型的参数当中,给一个 query 后,直接输出对应知识的 doc id 或者 doc content. 因为语言模型,就是知识库 [13]!
- 基于强化学习:也是比较前沿的方式,代表工作比如 OpenAI 的 WebGPT [14],使用 human feedback 训练模型,以进行正确知识的检索。
与模型或者工具交互

语言模型与模型或者工具交互,主要的目的是进行复杂任务的分解,比如将复杂的推理任务分解为若干子任务,这也是 Chain of Thought [17] 的核心思想。不同的子任务可以使用具有不同能力的模型或者工具解决,比如计算任务可以使用计算器解决,检索任务可以使用检索模型解决。因此,这种类型的交互不仅可以提升语言模型的推理 (reasoning)、规划 (planning)、决策 (decision making) 能力,还能减轻语言模型的 “幻觉” (hallucination)、不准确输出等局限。特别地,当使用工具执行某种特定的子任务时,可能会对外部世界产生一定影响,比如使用 WeChat API 发了一条朋友圈等,称为 “面向工具的学习”(Tool-Oriented Learning) [2].
另外,有时候显式地分解一个复杂的任务是很困难的,这种时候,可以为不同的语言模型赋予不同的角色或者技能,然后让这些语言模型在互相协作、沟通的过程当中,隐式、自动地形成某种分工方案 (division of labor),进行任务的分解。这种类型的交互不仅仅可以简化复杂任务的解决流程,还可以对人类社会进行模拟,构造某种形式的智能体社会。
作者们将模型和工具放在一起,主要是因为模型和工具不一定是分开的两个范畴,比如一个搜索引擎工具和一个 retriever model 并没有本质的不同。这种本质,作者们使用 “任务分解后,怎样的子任务由怎样的对象来承担” 进行界定。
语言模型与模型或者工具交互时,有三种类型的操作:
- Thinking: 模型与自己本身进行交互,进行任务的分解以及推理等;
- Acting:模型调用其他的模型,或者外部工具等,帮助进行推理,或者对外部世界产生实际作用;
- Collaborating: 多个语言模型智能体互相沟通、协作,完成特定的任务,或者模拟人类的社会行为。
注意:Thinking 主要论及的是 “多阶段思维链” (Multi-Stage Chain-of-Thought),即:不同的推理步骤,对应着语言模型不同的调用 (multiple model run),而不是像 Vanilla CoT [17] 那样,跑一次模型同时输出 thought+answer (single model run).
这里部分承袭的是 ReAct [18] 的表述方式。
Thinking 的典型工作包括了 ReAct [18], Least-to-Most Prompting [19], Self-Ask [20] 等。例如,Least-to-Most Prompting [19] 首先将一个复杂问题分解为若干简单的模块子问题,然后迭代式地调用语言模型逐个击破。
Acting 的典型工作包括了 ReAct [18], HuggingGPT [21], Toolformer [22] 等。例如,Toolformer [22] 将语言模型的预训练语料处理成了带有 tool-use prompt 的形式,因此,经过训练后的语言模型,可以在生成文本的时候,自动地在正确的时机调用正确的外部工具(如搜索引擎、翻译工具、时间工具、计算器等)解决特定的子问题。
Collaborating 主要包括:
- 闭环交互:比如 Socratic Models [23] 等,通过大型语言模型、视觉语言模型、音频语言模型的闭环交互,完成特定于视觉环境的某些复杂 QA 任务。
- 心智理论 (Theory of Mind): 旨在让一个智能体能够理解并预测另一个智能体的状态,以促进彼此的高效交互。例如 EMNLP 2021 的 Outstanding Paper, MindCraft [24], 给两个不同的语言模型赋予了不同但互补的技能,让他们在交流的过程中协作完成 MineCraft 世界中的特定任务。著名教授 Graham Neubig 最近也非常关注这一条研究方向,如 [25].
- 沟通式代理 (Communicative Agents): 旨在让多个智能体能够进行彼此交流协作。最为典型的例子就是斯坦福大学最近震惊世界的 Generative Agents [26]:搭建一个沙盒环境,让好多个由大模型注入 “灵魂” 的智能体在其中自由活动,它们竟然可以自发地呈现一些类人的社会行为,比如聊天打招呼等,颇有一种 “西部世界” 的味道(如下图)。除此之外,比较出名的工作还有 DeepGCN 作者的新工作 CAMEL [27],让两个大模型赋能的智能体在彼此沟通的过程当中开发游戏,甚至炒股,而不需要人类的过多干预。作者在文章中明确提出了 “大模型社会” (LLM Society) 的概念。
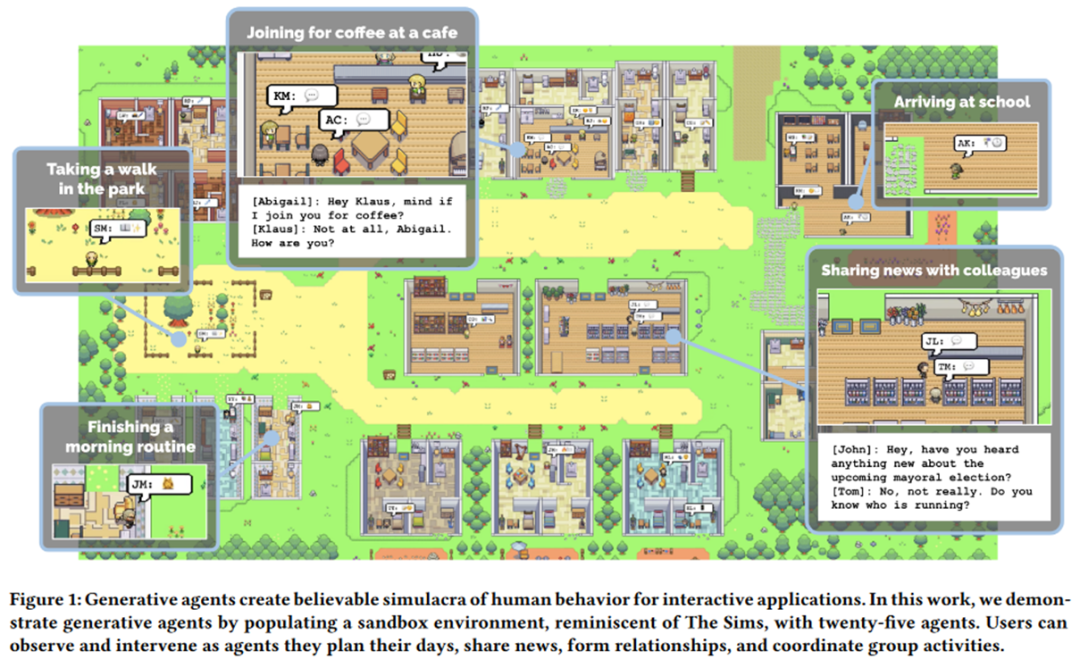
Generative Agents: Interactive Simulacra of Human Behavior, https://arxiv.org/pdf/2304.03442.pdf
与环境交互
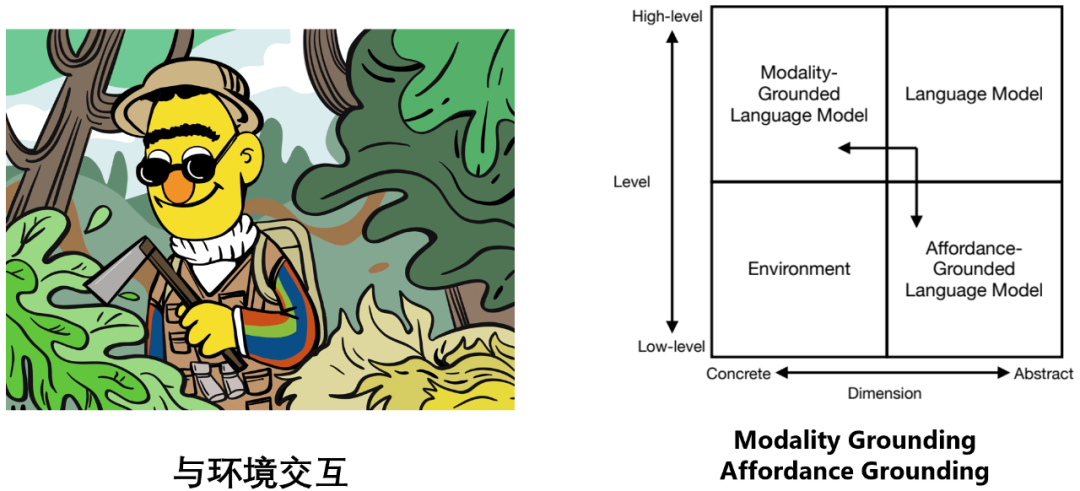
语言模型和环境属于两个不同的象限:语言模型建立在抽象的文字符号之上,擅长 high-level 的推理、规划、决策等任务;而环境建立在具体的感知信号之上(如视觉信息、听觉信息等),模拟或者自然发生一些 low-level 的任务,如提供观察 (observation)、反馈 (feedback)、状态更新 (state transition) 等(如:现实世界中一个苹果落到了地上,模拟引擎中一个 “苦力怕” 出现在了你的面前)。
因此,要让语言模型能够有效且高效地与环境进行交互,主要包括了两个方面的努力:
- Modality Grounding: 让语言模型可以处理图像、音频等多模态信息;
- Affordance Grounding: 让语言模型在环境具体场景的尺度下对可能的、恰当的对象执行可能的、恰当的动作。
对于 Modality Grounding 最为典型的就是视觉 - 语言模型。一般而言可以使用单塔模型如 OFA [28], 双塔模型如 BridgeTower [29], 或者语言模型与视觉模型的交互如 BLIP-2 [30] 来进行。这里不再多说,读者可以详看本论文。
对于 Affordance Grounding 主要有两个考虑,即:如何在给定任务的条件下进行 (1) 场景尺度的感知 (scene-scale perception), 以及 (2) 可能的动作 (possible action)。举个例子:

比如上图的场景,给定任务 “请关闭客厅里面的灯”,“场景尺度的感知” 要求我们找到全部红色框选的灯,而不要选中不在客厅而在厨房的绿色圈选的灯,“可能的动作” 要求我们确定可行的关灯方式,比如拉线灯需要使用 “拉” 的动作,而开关灯需要使用 “拨动开关” 的动作。
通常而言,Affordance Grounding 可以使用一个依附于环境的价值函数解决,如 SayCan [31] 等,也可以使用一个专门的 grounding model 如 Grounded Decoding [32] 等。甚至也可以通过与人、与模型、与工具等的交互来解决(如下图)。
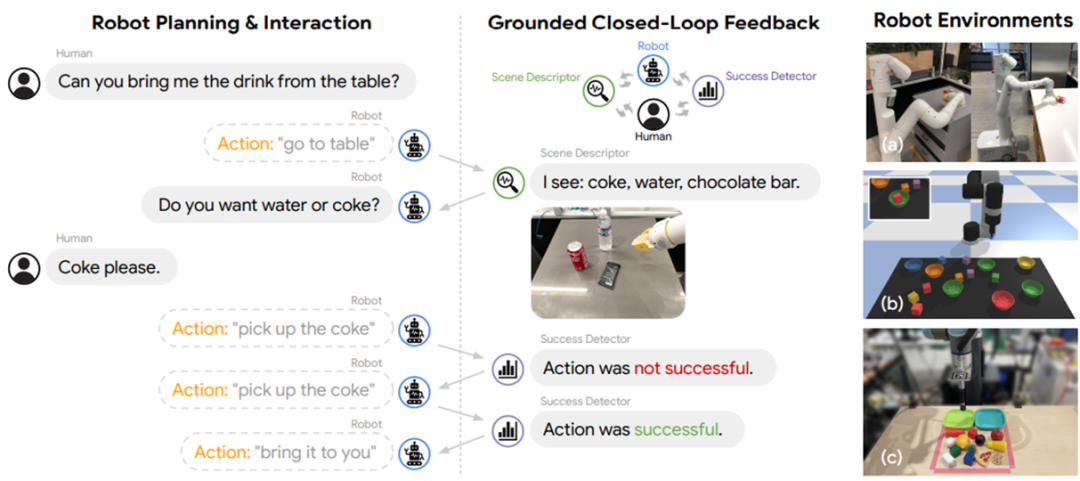
Inner Monologue [33]
用什么交互:交互接口
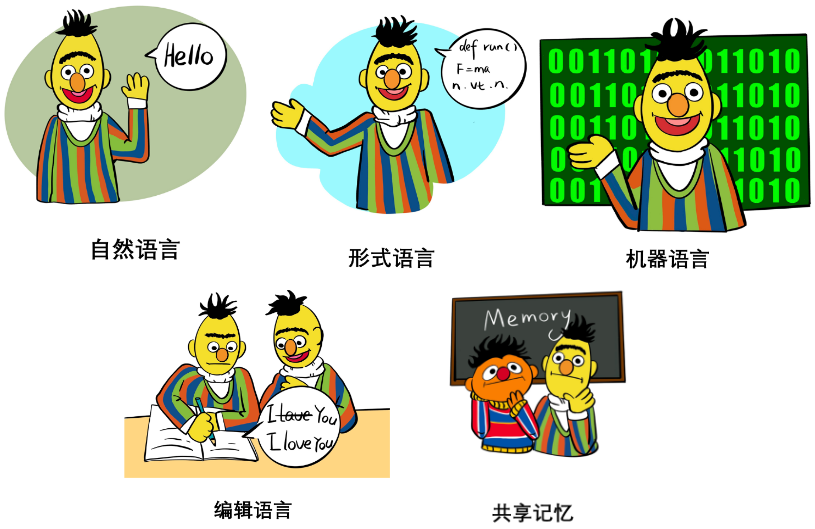
在论文 Interaction Interface 章节,作者们系统地讨论了不同交互语言、交互媒介的用法和优劣,包括:
- 自然语言:如 few-shot example, task instruction, role assignment 甚至结构化的自然语言等。主要讨论了其在泛化性、表达性上的特点及作用等。
- 形式语言:如代码、语法、数学公式等。主要讨论了其在可解析性、推理能力上的特点及作用等。
- 机器语言:如 soft prompts, 离散化的视觉 token 等。主要讨论了其在泛化性、信息瓶颈理论、交互效率上的特点及作用等。
- 编辑:主要包括了对文本进行的删除、插入、替换、保留等操作。讨论了它的原理、历史、优势以及目前存在的局限。
- 共享记忆:主要包括了 hard memory 和 soft memory. 前者将历史状态记录在一个 log 里面作为记忆,后者使用一个可读可写的记忆外置模块保存张量。论文讨论了两者的特点、作用以及存在的局限等。
怎么交互:交互方法
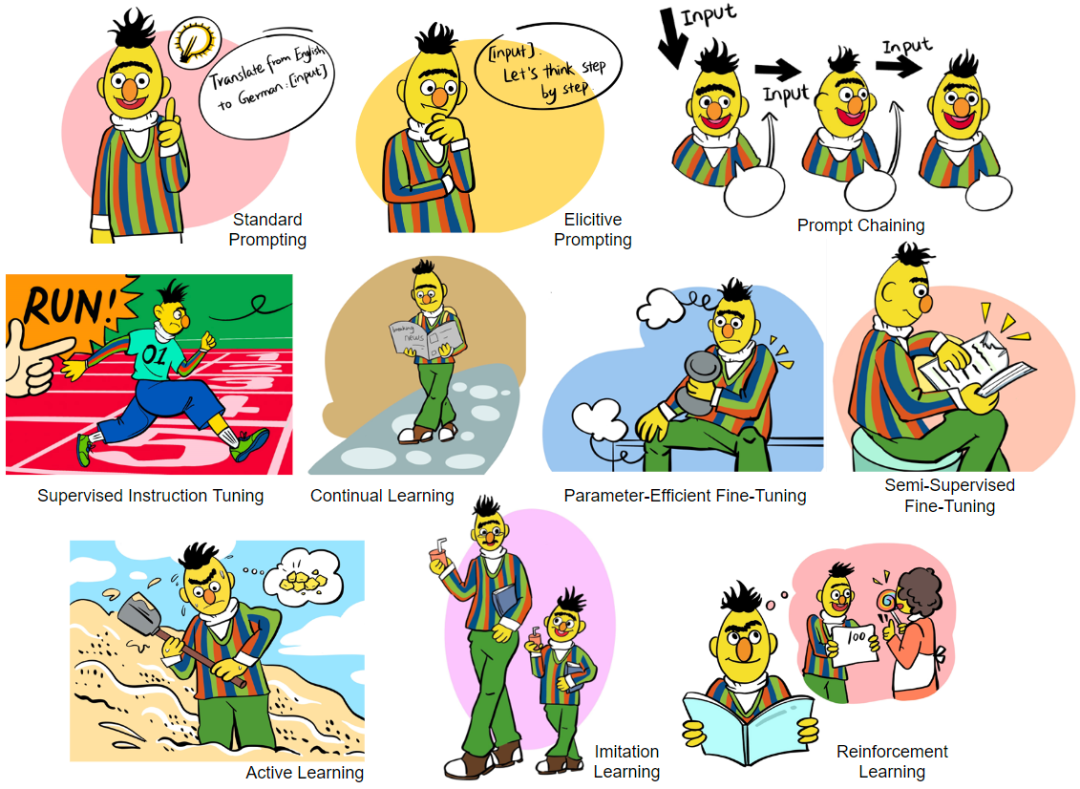
论文还全面、详细、系统地讨论了各种各样的交互方法,主要包括:
- Prompting: 不调整模型参数,仅仅通过 prompt engineering 的方式调用语言模型,涵盖了上下文学习(In-Context Learning)、思维链提示 (Chain of Thought)、工具使用提示 (Tool-use)、级联推理链 (Prompt Chaining) 等多种方法,详细讨论了各种 Prompting 技巧的原理、作用、各种 trick 和局限等,比如在可控性和鲁棒性上的考虑等。
- Fine-Tuning: 进行模型参数的调整,以让模型从交互信息中进行学习更新。本节涵盖了监督指令精调 (Supervised Instruction Tuning)、参数高效精调 (Parameter-Efficient Fine-Tuning)、持续学习 (Continual Learning)、半监督学习 (Semi-Supervised Fine-Tuning) 等方法。详细讨论了这些方法的原理、作用、优势、在具体使用时的考虑、及其局限。其中还包括了部分 Knowledge Editing 的内容(即编辑模型内部的知识)。
- Active Learning: 交互式的主动学习算法框架。
- Reinforcement Learning: 交互式的强化学习算法框架,讨论了在线强化学习框架、离线强化学习框架、从人类反馈中学习(RLHF)、从环境反馈中学习(RLEF)、从 AI 反馈中学习 (RLAIF) 等多种方法。
- Imitation Learning: 交互式的模仿学习算法框架,讨论了在线模仿学习、离线模仿学习等。
- Interaction Message Fusion: 为上述所有交互方法提供了一个统一的框架,同时在这个框架中,向外扩展,讨论了不同的知识、信息融合方案,比如跨注意力融合方案 (cross-attention)、约束解码融合方案 (constrained decoding) 等。
其他讨论
囿于篇幅,本文不详细介绍其他方面的讨论,如评测、应用、伦理、安全以及未来发展方向等。但是这些内容在该论文原文中,仍然占据了 15 页的内容,因此推荐读者在原文中查看更多细节,以下为这些内容的大纲:
对交互的评测
论文中对评测的讨论主要涉及以下关键词:
交互式 NLP 的主要应用
- 可控文本生成 (Controllable Text Generation)
- 与人交互:RLHF 的思想钢印现象等
- 与知识交互:Knowledge-Aware Fine-Tuning [34] 等
- 与模型、工具交互:Classifier-Guided CTG 等
- 与环境交互:affordance grounding 等
- 交互式写作助手 (Writing Assistant)
- Content Support: 内容支持型
- Content Checking and Polishing:内容检查、润色型
- Content Enrichment:内容丰富型
- Content Co-creation:内容创作型
- 具身智能 (Embodied AI)
- Observation and Manipulation: 基础
- Navigation and Exploration: 进阶 (e.g., long-horizon embodied tasks)
- Multi-Role Tasks: 高级
- 游戏 (Text Game)
- 包含文本的交互式游戏平台:Interactive Text Game Platforms
- 交互型语言模型如何玩转仅文本类型的游戏:Playing Text-Only Games
- 交互型语言模型如何赋能包含文本媒介的游戏:Powering Text-Aided Games
- 其他应用
- 领域、任务专门化(Specialization):比如如何基于交互打造特定于金融领域、医学领域等的语言模型框架。
- 个性化与人格化 (Personalization & Personality):比如如何基于交互打造特定于用户个人的、或者带有特定人格的语言模型。
- 基于模型的评测(Model-based Evaluation)
伦理与安全
讨论了交互型语言模型在教育上的影响,还针对社会偏见、隐私等伦理安全问题进行了讨论。
未来发展方向与挑战
- Alignment:语言模型的对齐问题,如何让模型的输出更加无害、更加符合人类价值观、更加有理有据等。
- Social Embodiment:语言模型的 Grounding 问题,如何进一步推动语言模型具身化和社会化。
- Plasticity:语言模型的可塑性问题,如何保证模型知识的持续更新,且不会在更新的过程中遗忘先前获得的知识。
- Speed & Efficiency:语言模型的推理速度、训练效率等问题,如何在不影响性能的情况下,加速推理,以及加速训练的效率。
- Context Length:语言模型的上下文窗口大小限制。如何扩充上下文的窗口大小,使其能够处理更长的文本。
- Long Text Generation:语言模型的长文本生成问题。如何让语言模型在极长文本的生成场景下,也能保持优良的性能。
- Accessibility:语言模型的可用性问题。如何让语言模型从闭源到开源,如何在不过度损失性能的前提下,让语言模型能够部署在边缘设备如车载系统、笔记本上等。
- Analysis:语言模型的分析、可解释性等问题。比如如何预测模型 scaling up 之后的性能,以指导大模型的研发,如何解释大模型内部的机理等。
- Creativity:语言模型的创造性问题。如何让语言模型更加具有创造性,能够更好地使用比喻、隐喻等,能够创造出新的知识等。
- Evaluation:如何更好地针对通用大模型进行评测,如何评测语言模型在交互上的特性等。
以上是NLP还能做什么?北航、ETH、港科大、中科院等多机构联合发布百页论文,系统阐述后ChatGPT技术链的详细内容。更多信息请关注PHP中文网其他相关文章!

 易于理解的解释如何在Chatgpt中建立两步身份验证!May 12, 2025 pm 05:37 PM
易于理解的解释如何在Chatgpt中建立两步身份验证!May 12, 2025 pm 05:37 PMCHATGPT SECURICE增强:两阶段身份验证(2FA)配置指南 需要两因素身份验证(2FA)作为在线平台的安全措施。本文将以易于理解的方式解释2FA设置过程及其在CHATGPT中的重要性。这是为那些想要安全使用chatgpt的人提供的指南。 单击此处获取OpenAI最新的AI代理OpenAi Deep Research⬇️ [chatgpt]什么是Openai深入研究?关于如何使用它和费用结构的详尽解释! 目录 chatg
![[针对企业] Chatgpt培训|对8种免费培训选项,补贴和示例进行了详尽的介绍!](https://img.php.cn/upload/article/001/242/473/174704251871181.jpg?x-oss-process=image/resize,p_40) [针对企业] Chatgpt培训|对8种免费培训选项,补贴和示例进行了详尽的介绍!May 12, 2025 pm 05:35 PM
[针对企业] Chatgpt培训|对8种免费培训选项,补贴和示例进行了详尽的介绍!May 12, 2025 pm 05:35 PM生成的AI的使用吸引了人们的关注,这是提高业务效率和创造新业务的关键。特别是,由于其多功能性和准确性,许多公司都采用了Openai的Chatgpt。但是,可以有效利用chatgpt的人员短缺是实施它的主要挑战。 在本文中,我们将解释“ ChatGpt培训”的必要性和有效性,以确保在公司中成功使用Chatgpt。我们将介绍广泛的主题,从ChatGpt的基础到业务使用,特定的培训计划以及如何选择它们。 CHATGPT培训提高员工技能
 关于如何使用Chatgpt简化您的Twitter操作的详尽解释!May 12, 2025 pm 05:34 PM
关于如何使用Chatgpt简化您的Twitter操作的详尽解释!May 12, 2025 pm 05:34 PM社交媒体运营的提高效率和质量至关重要。特别是在实时重要的平台上,例如Twitter,需要连续交付及时和引人入胜的内容。 在本文中,我们将解释如何使用具有先进自然语言处理能力的AI的Chatgpt操作Twitter。通过使用CHATGPT,您不仅可以提高实时响应功能并提高内容创建的效率,而且还可以制定符合趋势的营销策略。 此外,使用预防措施
![[对于Mac]说明如何开始以及如何使用ChatGpt桌面应用程序!](https://img.php.cn/upload/article/001/242/473/174704239752855.jpg?x-oss-process=image/resize,p_40) [对于Mac]说明如何开始以及如何使用ChatGpt桌面应用程序!May 12, 2025 pm 05:33 PM
[对于Mac]说明如何开始以及如何使用ChatGpt桌面应用程序!May 12, 2025 pm 05:33 PMCHATGPT MAC桌面应用程序详细指南:从安装到音频功能 最后,Chatgpt的Mac桌面应用程序现已可用!在本文中,我们将彻底解释从安装方法到有用的功能和将来的更新信息的所有内容。使用桌面应用程序独有的功能,例如快捷键,图像识别和语音模式,以极大地提高您的业务效率! 安装桌面应用的ChatGpt Mac版本 从浏览器访问:首先,在浏览器中访问chatgpt。
 chatgpt的角色限制是什么?解释如何避免它和模型上限May 12, 2025 pm 05:32 PM
chatgpt的角色限制是什么?解释如何避免它和模型上限May 12, 2025 pm 05:32 PM当使用chatgpt时,您是否曾经有过这样的经验,例如“输出在中途停止”或“即使我指定了字符的数量,它也无法正确输出”?该模型非常开创性,不仅允许自然对话,而且还允许创建电子邮件,摘要论文,甚至允许产生诸如小说之类的创意句子。但是,ChatGpt的弱点之一是,如果文本太长,输入和输出将无法正常工作。 Openai的最新AI代理“ Openai Deep Research”
 什么是Chatgpt的语音输入和语音对话功能?解释如何设置以及如何使用它May 12, 2025 pm 05:27 PM
什么是Chatgpt的语音输入和语音对话功能?解释如何设置以及如何使用它May 12, 2025 pm 05:27 PMChatgpt是Openai开发的创新AI聊天机器人。它不仅具有文本输入,而且还具有语音输入和语音对话功能,从而可以进行更自然的交流。 在本文中,我们将解释如何设置和使用Chatgpt的语音输入和语音对话功能。即使您不能脱身,Chatp Plans也通过与您交谈来做出回应并回应音频,这在繁忙的商业情况和英语对话练习等各种情况下都带来了很大的好处。 关于如何设置智能手机应用程序和PC的详细说明以及如何使用。
 易于理解的解释如何使用Chatgpt进行求职和寻找工作!May 12, 2025 pm 05:26 PM
易于理解的解释如何使用Chatgpt进行求职和寻找工作!May 12, 2025 pm 05:26 PM成功的快捷方式!使用chatgpt有效的工作变更策略 在当今加剧的工作变更市场中,有效的信息收集和彻底的准备是成功的关键。 诸如Chatgpt之类的高级语言模型是求职者的强大武器。在本文中,我们将解释如何有效利用Chatgpt来提高您的工作企业效率,从自我分析到申请文件和面试准备。节省时间和学习技术,以充分展示您的优势,并帮助您成功搜索工作。 目录 使用chatgpt的狩猎工作示例 自我分析的效率:聊天
 易于理解的解释如何使用ChatGpt创建和输出思维地图!May 12, 2025 pm 05:22 PM
易于理解的解释如何使用ChatGpt创建和输出思维地图!May 12, 2025 pm 05:22 PM思维地图是组织信息并提出想法的有用工具,但是创建它们可能需要时间。使用Chatgpt可以大大简化此过程。 本文将详细说明如何使用chatgpt轻松创建思维地图。此外,通过创建的实际示例,我们将介绍如何在各种主题上使用思维图。 了解如何使用Chatgpt有效地组织和可视化您的想法和信息。 Openai的最新AI代理OpenA


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

SublimeText3 Linux新版
SublimeText3 Linux最新版

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

WebStorm Mac版
好用的JavaScript开发工具

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

