
华人科学团队推出「思维链集」,全面测评大模型复杂推理能力

- 王林转载
- 2023-06-05 13:22:29920浏览
大模型能力涌现,参数规模越大越好?
然而,越来越多的研究人员声称,小于10B的模型也可以实现与GPT-3.5相当的性能。
真是如此吗?
OpenAI发布GPT-4的博客中,曾提到:
在随意的对话中,GPT-3.5与GPT-4间的差别或许非常细微。当任务的复杂性达到足够阈值时,差异就会出现——GPT-4比GPT-3.5更可靠、更有创意,并且能够处理更细微的指令。
谷歌的开发者对PaLM模型也进行了类似的观察,他们发现,大模型的思维链推理能力明显强于小模型。
这些观察都表明,执行复杂任务的能力,才是体现大模型能力的关键。
就像那句老话,模型和程序员一样,「废话少说,show me the reasoning」。

来自爱丁堡大学、华盛顿大学、艾伦AI研究所的研究人员认为,复杂推理能力是大模型在未来进一步朝着更加智能化工具发展的基础。
基本的文字总结归纳能力,大模型执行起来确实属于「杀鸡用牛刀」。
针对这些基础能力的测评,对于研究大模型未来发展似乎是有些不务正业。
论文地址:https://arxiv.org/pdf/2305.17306.pdf
大模型推理能力哪家强?
这也就是为什么研究人员编制了一个复杂推理任务列表Chain-of-Thought Hub,来衡量模型在具有挑战性的推理任务中的表现。
测试项目包括,数学(GSM8K)),科学(MATH,定理 QA),符号(BBH) ,知识(MMLU,C-Eval),编码(HumanEval)。
这些测试项目或者数据集都是针对大模型的复杂推理能力下手,没有那种谁来都能答得八九不离十的简单任务。
研究人员依然采用思维链提示(COT Prompt)的方式来对模型的推理能力进行测评。
对于推理能力的测试,研究人员只采用最终答案的表现作为唯一的衡量标准,而中间的推理步骤不作为评判的依据。
如下图所示,当前主流模型在不同推理任务上的表现。
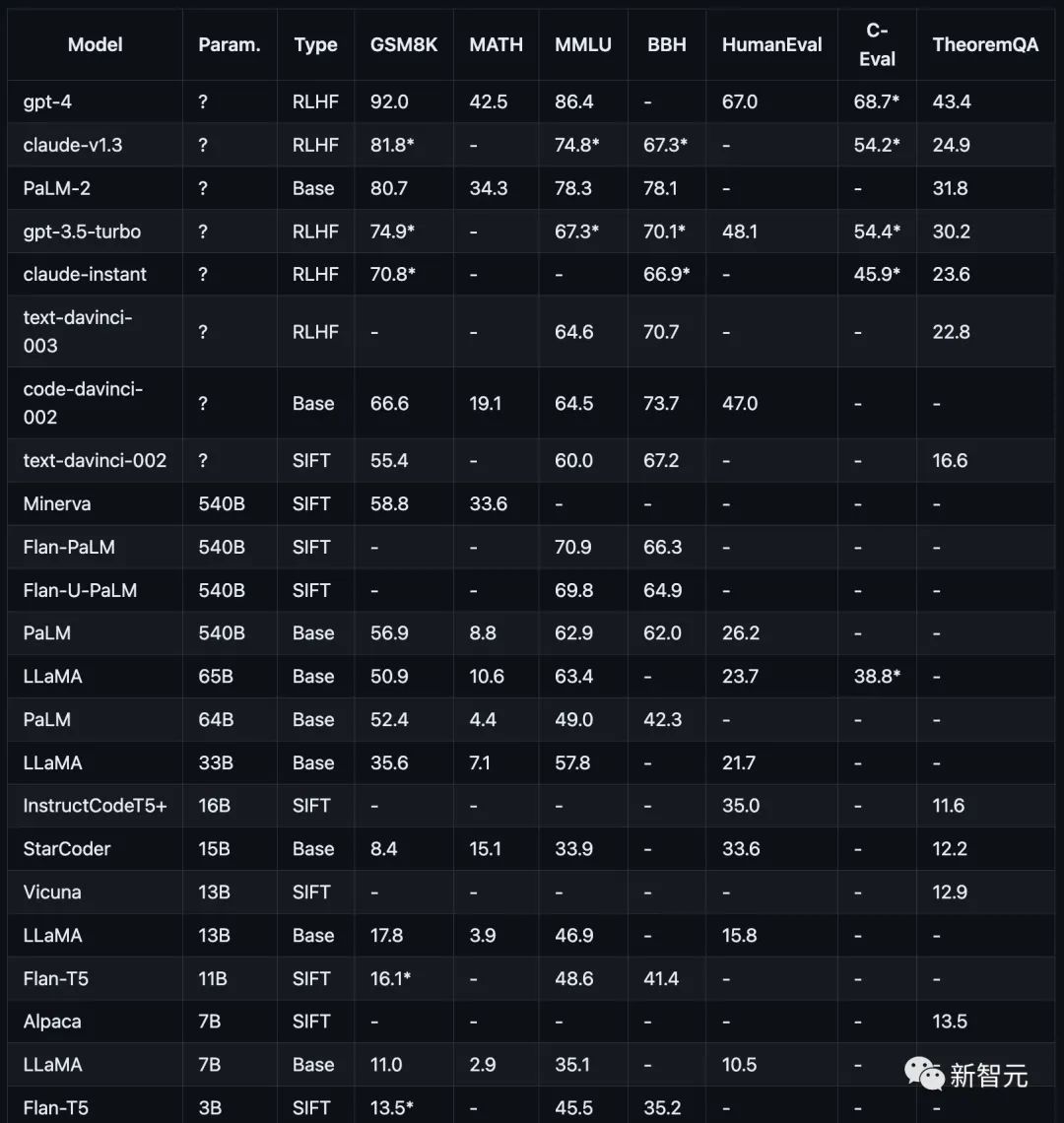
测试结果:模型越大推理能力越强
研究人员的研究专注于当前流行模型,包括GPT、Claude、PaLM、LLaMA和T5模型家族,具体而言:
OpenAI GPT包括GPT-4(目前最强)、GPT3.5-Turbo(更快,但能力较弱)、text-davinci-003、text-davinci-002和code-davinci-002(Turbo之前的重要版本)。

Anthropic Claude包括claude-v1.3(较慢但能力较强)和claude-instant-v1.0(较快但能力较弱)。
Google PaLM,包括PaLM、PaLM-2,以及它们的指令调整版本(FLan-PaLM和Flan-UPaLM),强基础和指令调整模型。

Meta LLaMA,包括7B、13B、33B和65B变体,重要的开放源码的基础模型。
GPT-4在GSM8K和MMLU上明显优于其他所有模型,而Claude是唯一一个与GPT系列相媲美的模型。
FlanT5 11B和LLaMA 7B等较小的模型掉队掉的厉害。
通过实验,研究人员发现,模型性能通常与规模相关,大致呈对数线性趋势。
不公开参数规模的模型,通常比公开规模信息的模型表现更好。
LLaMA-65B推理能力接近ChatGPT
另外,研究者指出,开源社区可能仍需要探索关于规模和RLHF的「护城河」以进一步改进。
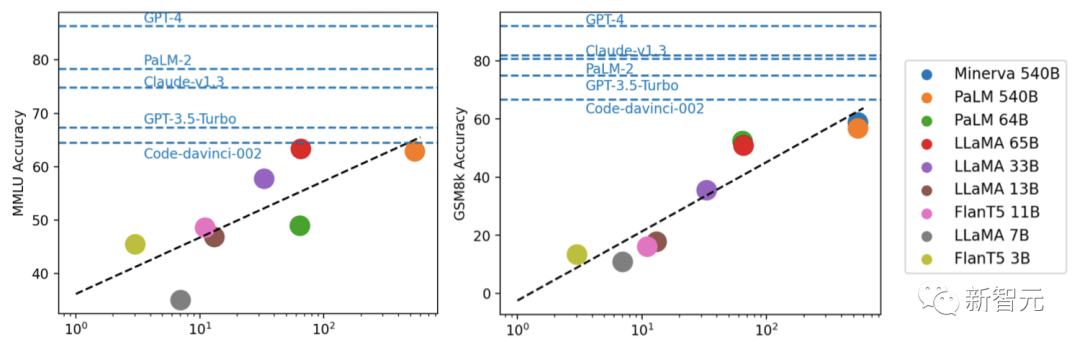
论文一作符尧总结道:
1. 开源和封闭之间存在明显的差距。
2. 大多数排名靠前的主流模型是RLHF
3. LLaMA-65B非常接近code-davinci-002,GPT-3.5的基础模型
4. 综合上述,最有希望的方向是「在LLaMA 65B上做RLHF」。

针对这个项目,作者对未来的进一步优化进行了说明:
未来会增加更多包括更精心选择的推理数据集,尤其是衡量常识推理、数学定理的数据集。
以及调用外部 API 的能力。
更重要的是要囊括更多语言模型,例如基于 LLaMA 的指令微调模型,例如 Vicuna7等等开源模型。
还可以通过 API像 Cohere 8 一样访问PaLM-2 等模型的能力。
总之,作者相信这个项目可以作为评估和指导开源大语言模型发展的一个公益设施发挥很大作用。
以上是华人科学团队推出「思维链集」,全面测评大模型复杂推理能力的详细内容。更多信息请关注PHP中文网其他相关文章!