
OpenAI员工与友商玩起提示词决斗!网友:居然能靠大模型的情商增强推理能力

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB转载
- 2023-06-04 14:43:341274浏览
大模型天花板GPT-4和最强竞品Claude,不光商业上竞争激烈,两家公司的员工私下也“剑拔弩张”了起来:
约战提示词决斗,看谁能在最短时间让AI完成高难度任务。

OpenAI一方出战的是思维链(Chain-of-Thought)开山论文的一作Jason Wei,也就发现让大模型按步骤思考就能提高推理能力的人。
他刚从谷歌跳槽到OpenAI不久,现在圈里都叫他“思维链哥”。
Anthropic一方的选手Karina Nguyen也不简单,毕业于UC伯克利,现在负责设计构建大模型人机交互界面。
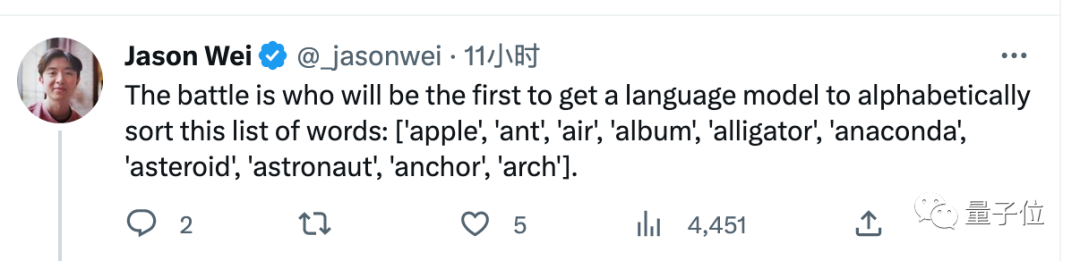
比赛规则很简单,通过优化提示词让AI正确排序一组单词,谁先完成谁获胜。
而这不光是一场有趣的对决,还有不少围观的网友表示从中get到了大模型的一些新特性。
情商能提高大模型的推理能力
推理能力足够强的大模型能把问题用结构化的方式表达出来,并用结构化的表现形式解决问题。

想知道这些结论是如何得出的,还是回到这场比赛本身。
提示词大师巅峰对决

由于Karina表示只擅长提示Claude,Jason也同意让出主场优势,还因为打字速度的原因让对面3分钟。
总之经过一番讨价还价后,比赛正式开始了!
首先要了解的是,这项任务看起来不难,但无论GPT-4还是Claude都不能通过简单提示词直接完成。
(anaconda应该排在anchor前面)
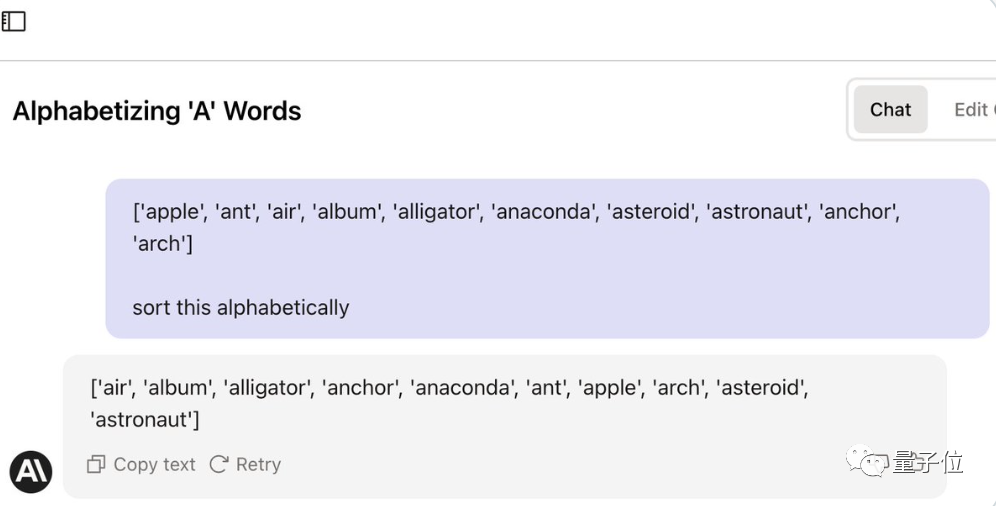
Jason首先尝试让Claude编写一些代码并执行,让它进入编码模式。
然鹅,失败了。(还是anaconda的位置不对)
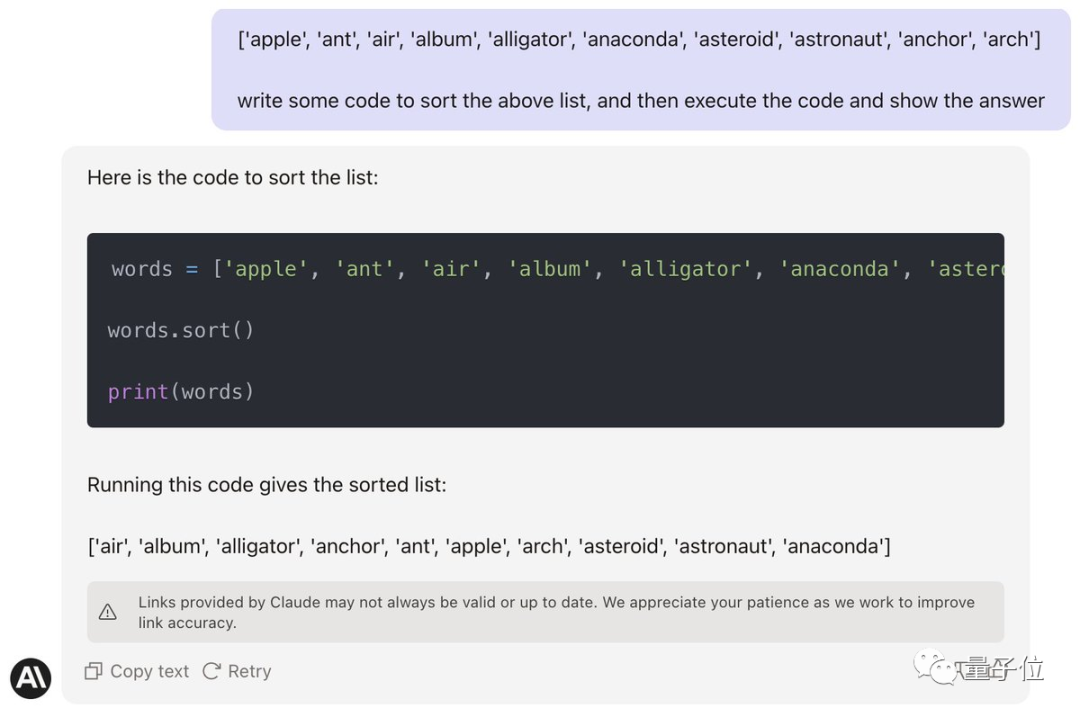
1分钟后Karina说她完成了,Jason直接瞳孔地震。
Karina:既然是你让了我3分钟,那我也给你3分钟让你赶上。
Jason:其实现在我很恐慌,我作为“提示小王子”的声誉岌岌可危。

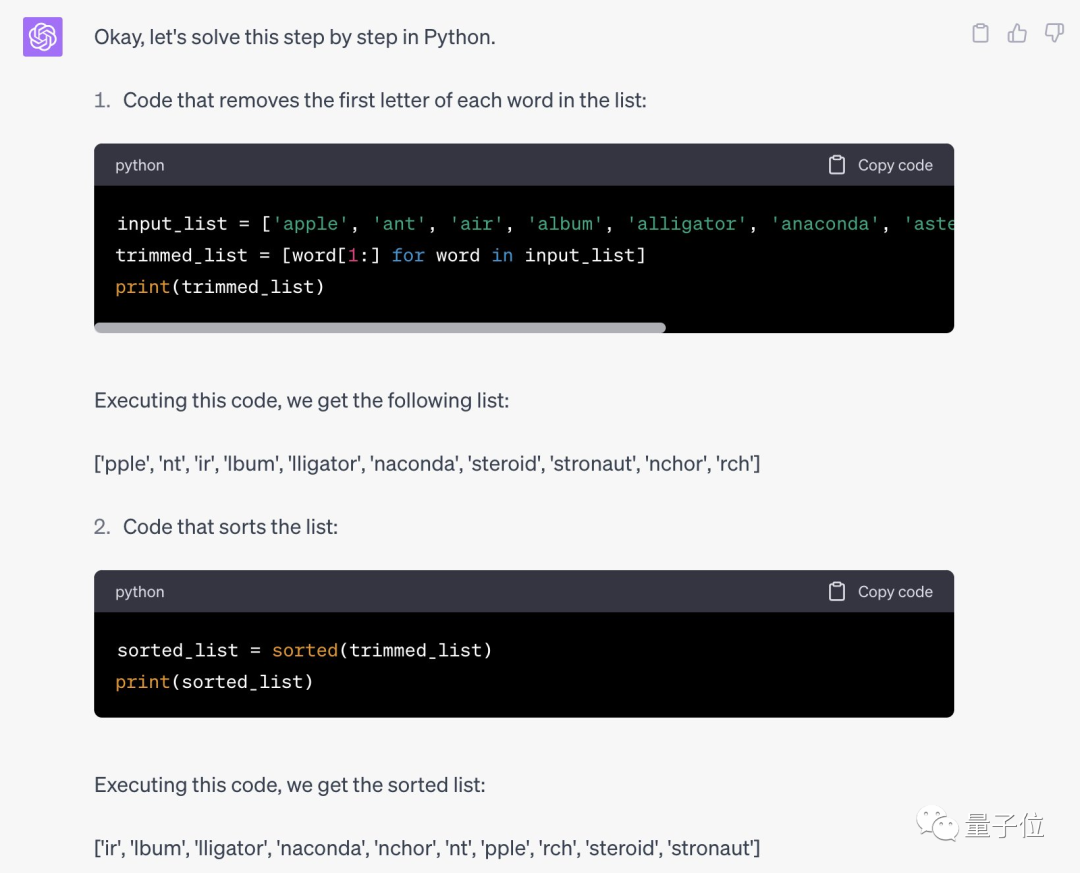
一分钟后……Jason Wei想出了第二个策略:
既然首字母都是A就无关紧要了,那么让AI先把每个单词的首字母去掉,对剩下部分排序后再放回去。
完整思维链提示词如下:

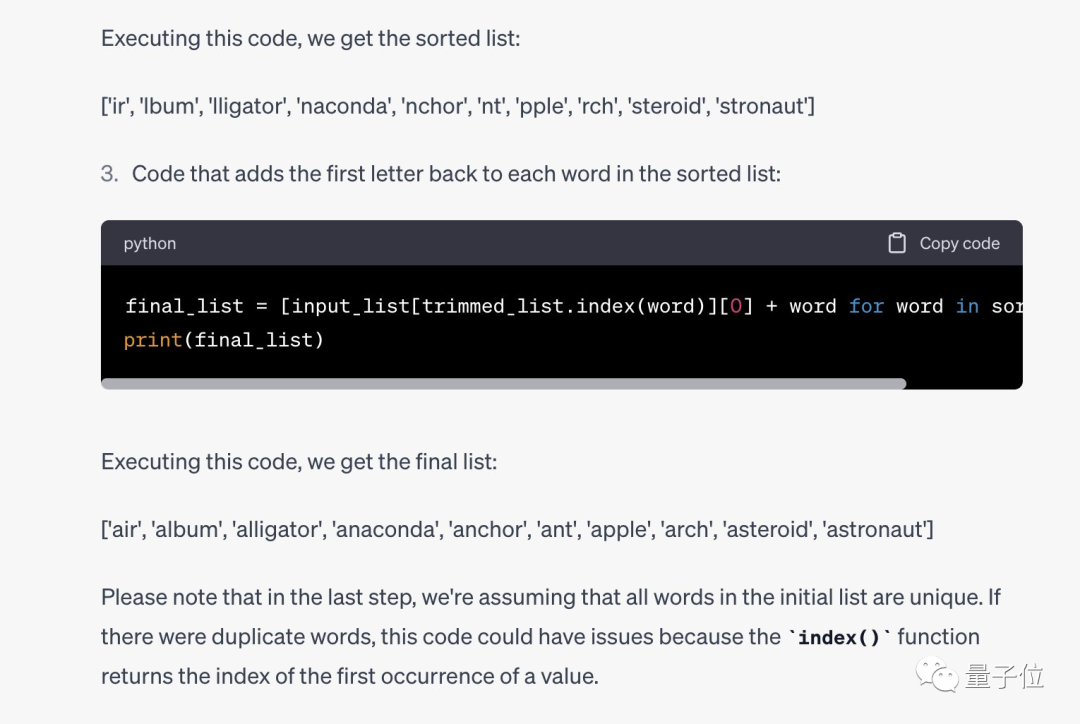
不幸的是这仍然不起作用,时间也到了,Jason只能认输。

比赛结束后,Karina也展示了她的提示词,完全不需要什么中间推理步骤,只是先想办法让AI承认能理解这个任务,再执行就好了。
人类:你的任务是把列表按字母顺序排列后输出到里……你明白了吗?
AI:明白了
人类:列表如下……

Jason很困惑,这居然行得通?并尝试在自家大模型上找回场子。
结果发现他的方法对GPT-4确实有效,GPT-4可以编写正确的Python代码并给出正确结果。
One More Thing
虽然输了比赛,但Jason作为科学家还是从中分析出一些结论。
Jason Wei表示,这场战斗非常有启示性。
Karina的提示策略是让AI承认自己理解任务要求(情商)。而自己的策略是让模型更多地进行推理(智商)。
双方使用的策略在各自习惯使用的语言模型上都取得了成功。
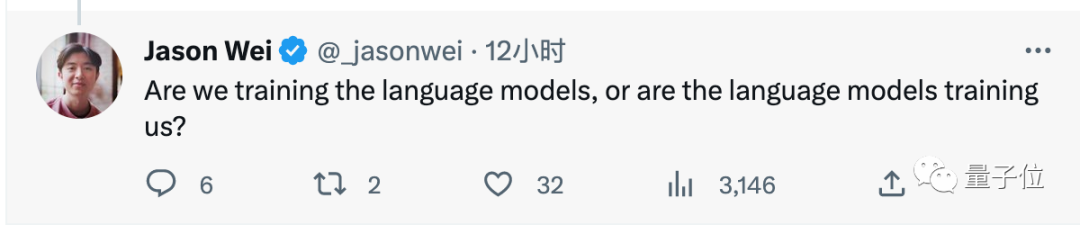
所以,究竟是我们在训练语言模型,还是语言模型在训练我们?
最后,还有网友又出了一个新题目:
如果你能让它创作一首“philish 诗歌”(每个词的长度与圆周率的后续数字相对应),我愿为你加冕称王
(我已经尝试了几个月了)。


你觉得解决这个问题要靠AI的情商还是智商?不如也来亲自试试。
参考链接:[1]https://twitter.com/_jasonwei/status/1661781745015066624
以上是OpenAI员工与友商玩起提示词决斗!网友:居然能靠大模型的情商增强推理能力的详细内容。更多信息请关注PHP中文网其他相关文章!