



没想到时至今日,ChatGPT竟还会犯低级错误?
吴恩达大神最新开课就指出来了:
ChatGPT不会反转单词!
比如让它反转下lollipop这个词,输出是pilollol,完全混乱。

哦豁,这确实有点大跌眼镜啊。
以至于听课网友在Reddit上发帖后,立马引来大量围观,帖子热度火速冲到6k。
而且这不是偶然bug,网友们发现ChatGPT确实无法完成这个任务,我们亲测结果也同样如此。

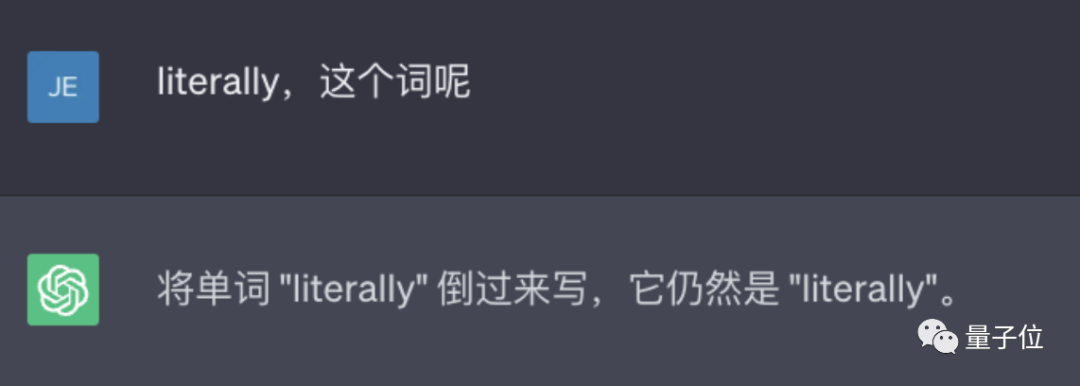
△实测ChatGPT(GPT-3.5)
甚至包括Bard、Bing、文心一言在内等一众产品都不行。
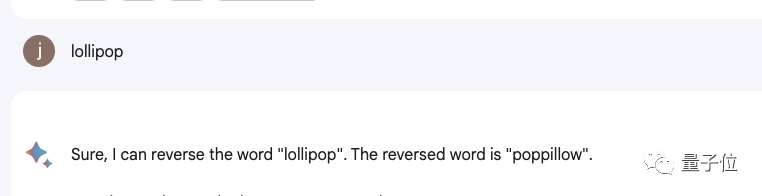
△实测Bard

△实测文心一言
还有人紧跟着吐槽, ChatGPT在处理这些简单的单词任务就是很糟糕。
比如玩此前曾爆火的文字游戏Wordle简直就是一场灾难,从来没有做对过。
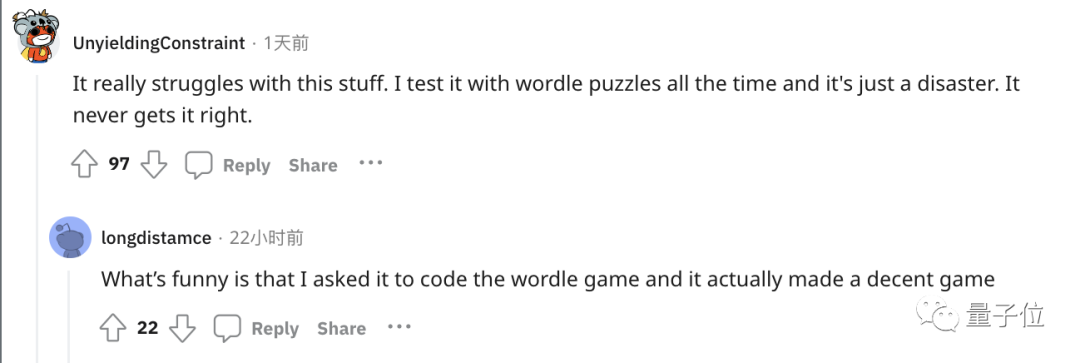
诶?这到底是为啥?
关键在于token
之所以有这样的现象,关键在于token。大型模型通常使用token来处理文本,因为token是文本中最常见的字符序列。
它可以是整个单词,也可以是单词一个片段。大型模型熟悉这些 Token 之间的统计关系,并能够熟练地生成下一个 Token。
因此在处理单词反转这个小任务时,它可能只是将每个token翻转过来,而不是字母。

这点放在中文语境下体现就更为明显:一个词是一个token,也可能是一个字是一个token。

针对开头的例子,有人尝试理解了下ChatGPT的推理过程。
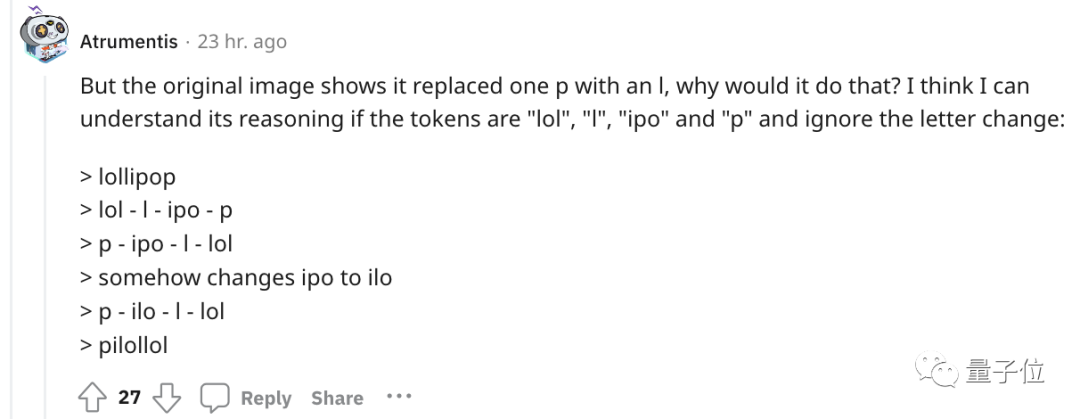
为了更直观的了解,OpenAI甚至还出了个GPT-3的Tokenizer。
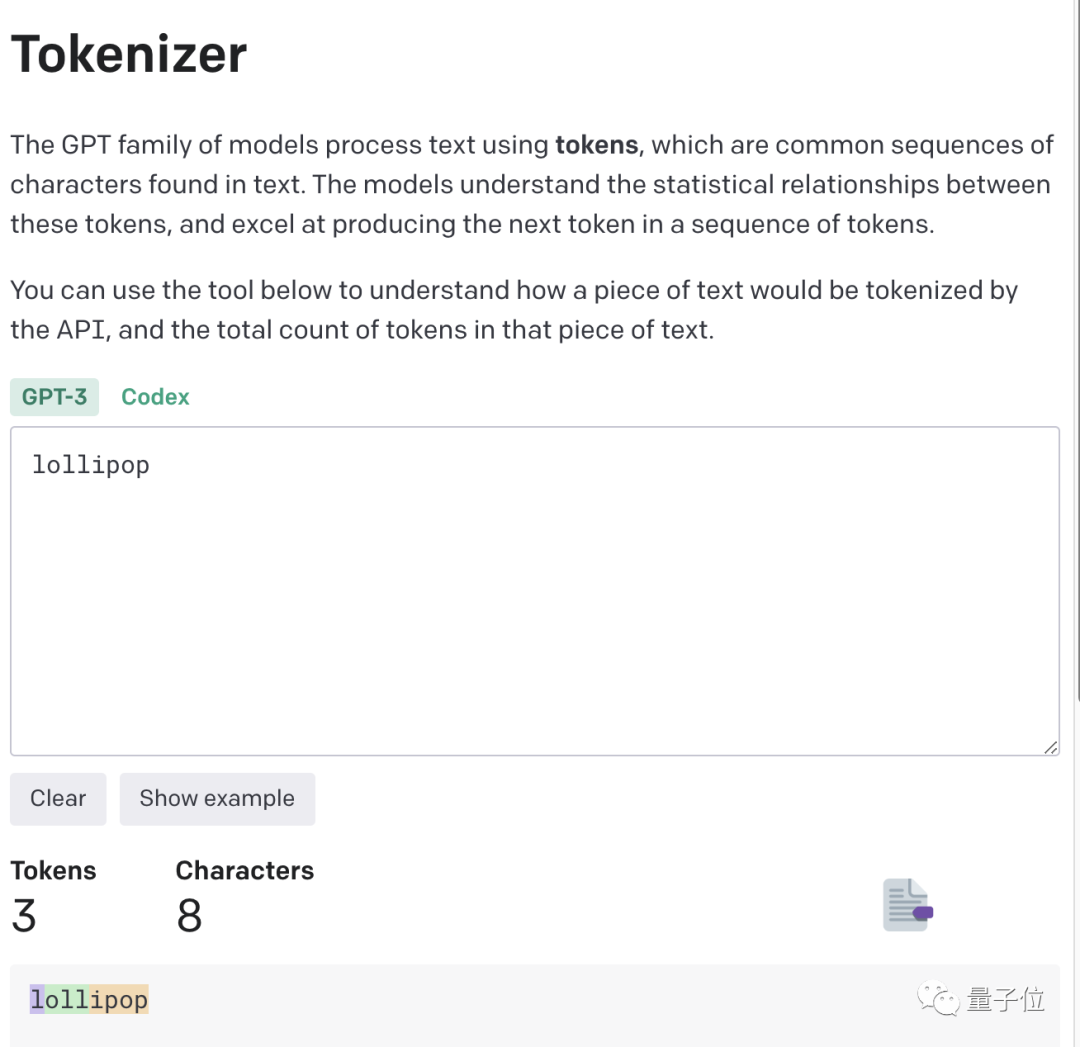
比如像lollipop这个词,GPT-3会将其理解成I、oll、ipop这三个部分。
根据经验总结,也就诞生出这样一些不成文法则。
- 1个token≈4个英文字符≈四分之三个词;
- 100个token≈75个单词;
- 1-2句话≈30个token;
- 一段话≈100个token,1500个单词≈2048个token;
单词如何划分还取决于语言。此前有人统计过,中文要用的token数是英文数量的1.2到2.7倍。
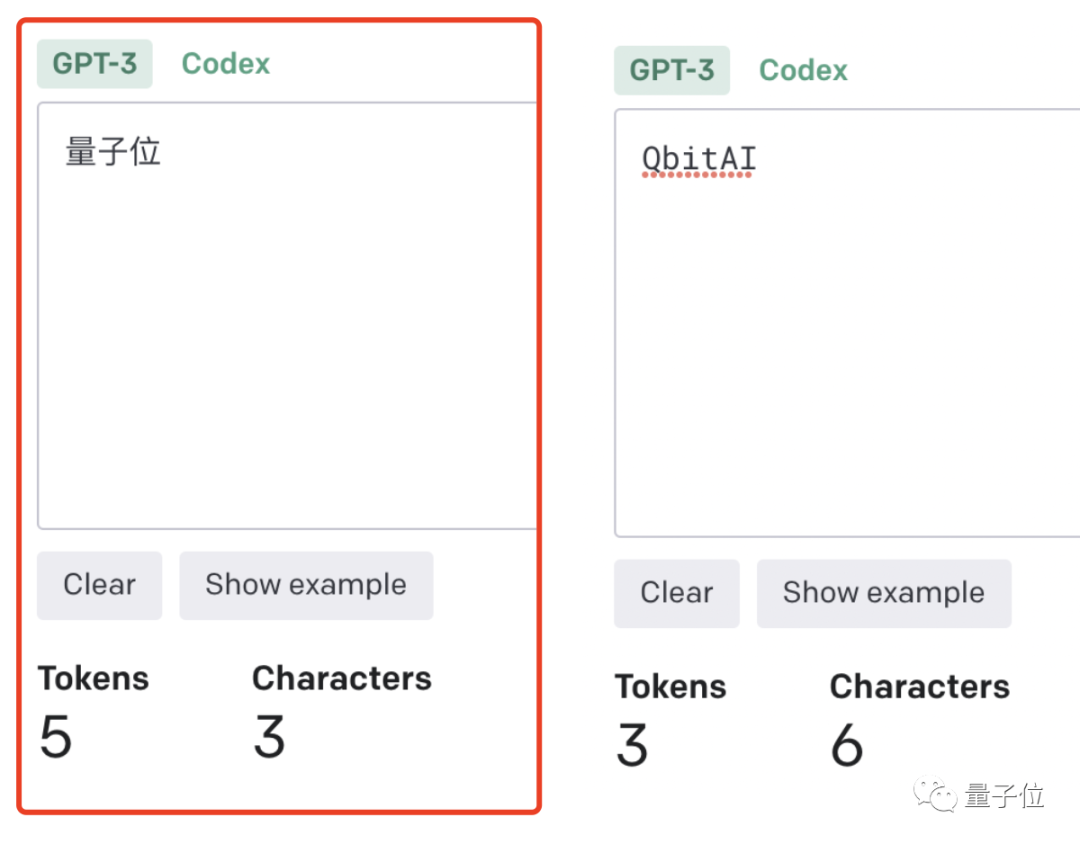
token-to-char(token到单词)比例越高,处理成本也就越高。因此处理中文tokenize要比英文更贵。
可以这样理解,token是大模型认识理解人类现实世界的方式。它非常简单,还能大大降低内存和时间复杂度。
但将单词token化存在一个问题,就会使模型很难学习到有意义的输入表示,最直观的表示就是不能理解单词的含义。
当时Transformers有做过相应优化,比如一个复杂、不常见的单词分为一个有意义的token和一个独立token。
就如同 "annoyingly" 被分成 "annoying" 和 "ly" 两个部分一样,前一个保留了其本身的意义,而后一个则更加常见。
这也成就了如今ChatGPT及其他大模型产品的惊艳效果,能很好地理解人类的语言。
至于无法处理单词反转这样一个小任务,自然也有解决之道。
最简单直接的,就是你先自己把单词给分开喽~

或者也可以让ChatGPT一步一步来,先tokenize每个字母。

又或者让它写一个反转字母的程序,然后程序的结果对了。(狗头)

不过也可以使用GPT-4,实测没有这样的问题。

△实测GPT-4
总之,token就是AI理解自然语言的基石。
而作为AI理解人类自然语言的桥梁,token的重要性也越来越明显。
它已经成为AI模型性能优劣的关键决定因素,还是大模型的计费标准。
甚至有了token文学
正如前文所言,token能方便模型捕捉到更细粒度的语义信息,如词义、词序、语法结构等。在序列建模任务(如语言建模、机器翻译、文本生成等)中,位置和顺序对于模型的建立非常重要。
模型只有在准确了解每个token在序列中的位置和上下文情况,才能更好正确预测内容,给出合理输出。
因此,token的质量、数量对模型效果有直接影响。
今年开始,越来越多大模型发布时,都会着重强调token数量,比如谷歌PaLM 2曝光细节中提到,它训练用到了3.6万亿个token。
以及很多行业内大佬也纷纷表示,token真的很关键!
今年从特斯拉跳槽到OpenAI的AI科学家安德烈·卡帕斯(Andrej Karpathy)就曾在演讲中表示:
更多token能让模型更好思考。

而且他强调,模型的性能并不只由参数规模来决定。
比如LLaMA的参数规模远小于GPT-3(65B vs 175B),但由于它用更多token进行训练(1.4T vs 300B),所以LLaMA更强大。
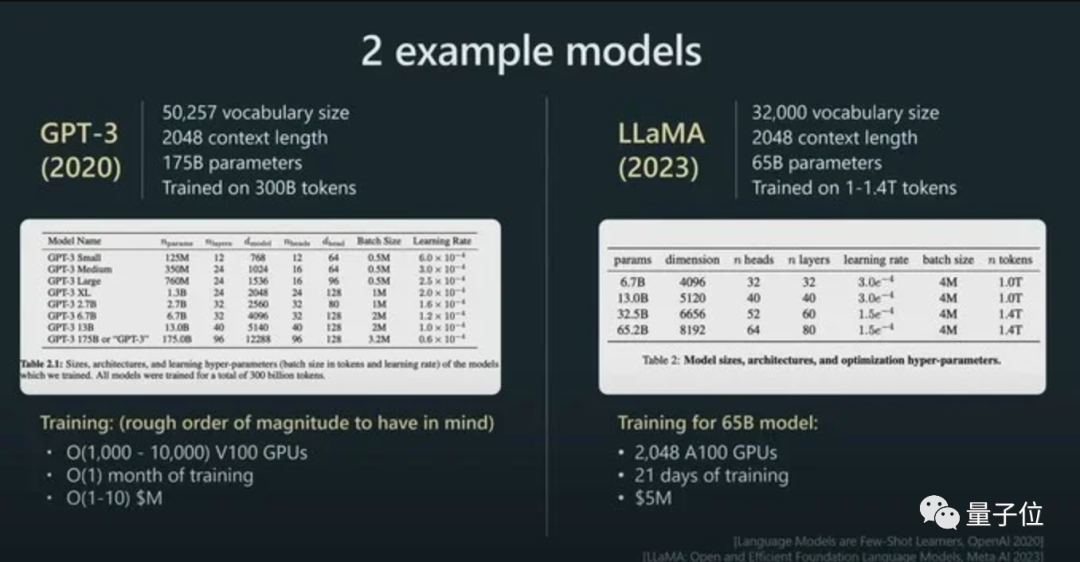
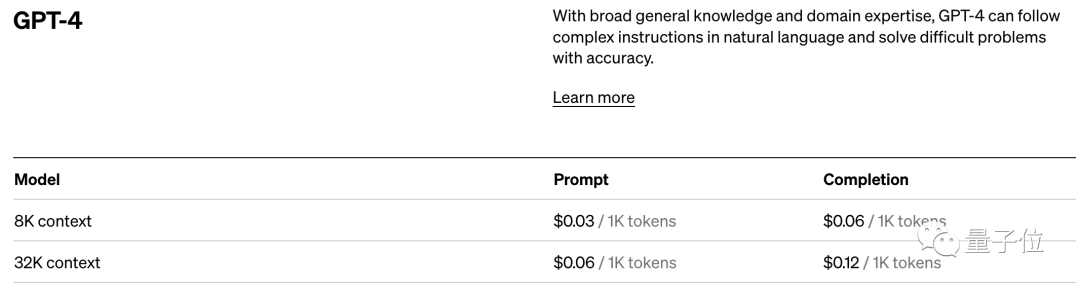
而凭借着对模型性能的直接影响,token还是AI模型的计费标准。
以OpenAI的定价标准为例,他们以1K个token为单位进行计费,不同模型、不同类型的token价格不同。
总之,踏进AI大模型领域的大门后,就会发现token是绕不开的知识点。
嗯,甚至衍生出了token文学……
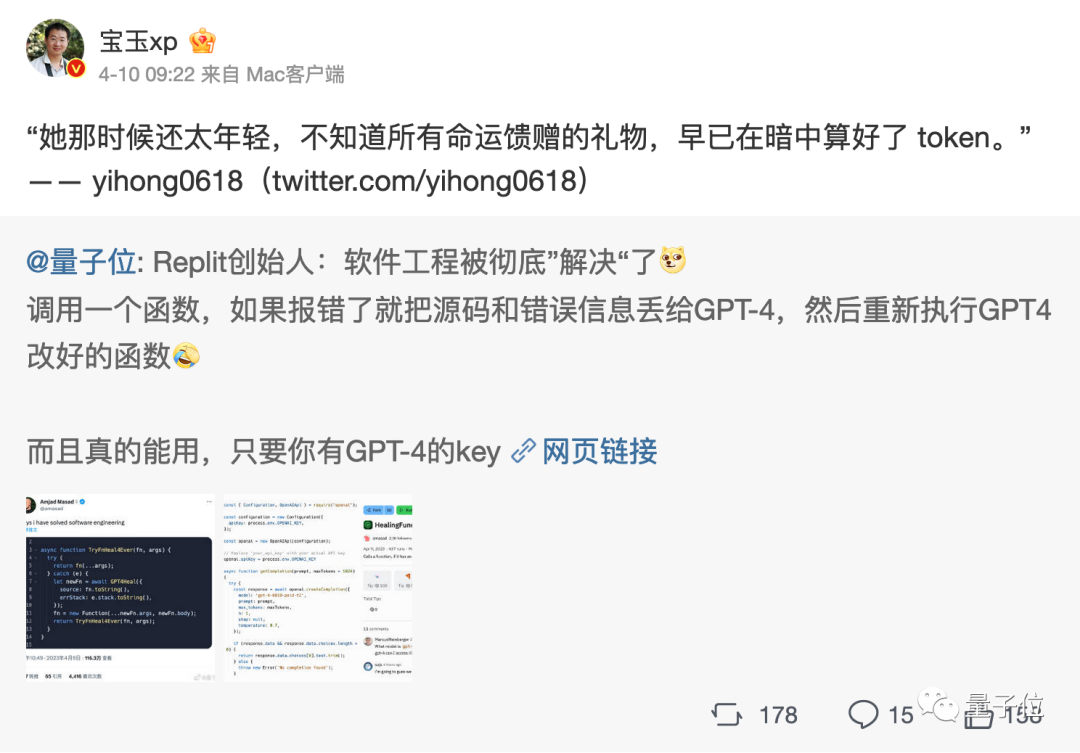
不过值得一提的是,token在中文世界里到底该翻译成啥,现在还没有完全定下来。
直译“令牌”总是有点怪怪的。
GPT-4觉得叫“词元”或“标记”比较好,你觉得呢?

参考链接:
[1]https://www.reddit.com/r/ChatGPT/comments/13xxehx/chatgpt_is_unable_to_reverse_words/
[2]https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them
[3]https://openai.com/pricing
以上是吴恩达ChatGPT课爆火:AI放弃了倒写单词,但理解了整个世界的详细内容。更多信息请关注PHP中文网其他相关文章!

 微软工作趋势指数2025显示工作场所容量应变Apr 24, 2025 am 11:19 AM
微软工作趋势指数2025显示工作场所容量应变Apr 24, 2025 am 11:19 AM由于AI的快速整合而加剧了工作场所的迅速危机危机,要求战略转变以外的增量调整。 WTI的调查结果强调了这一点:68%的员工在工作量上挣扎,导致BUR
 AI可以理解吗?中国房间的论点说不,但是对吗?Apr 24, 2025 am 11:18 AM
AI可以理解吗?中国房间的论点说不,但是对吗?Apr 24, 2025 am 11:18 AM约翰·塞尔(John Searle)的中国房间论点:对AI理解的挑战 Searle的思想实验直接质疑人工智能是否可以真正理解语言或具有真正意识。 想象一个人,对下巴一无所知
 中国的'智能” AI助手回应微软召回的隐私缺陷Apr 24, 2025 am 11:17 AM
中国的'智能” AI助手回应微软召回的隐私缺陷Apr 24, 2025 am 11:17 AM与西方同行相比,中国的科技巨头在AI开发方面的课程不同。 他们不专注于技术基准和API集成,而是优先考虑“屏幕感知” AI助手 - AI T
 Docker将熟悉的容器工作流程带到AI型号和MCP工具Apr 24, 2025 am 11:16 AM
Docker将熟悉的容器工作流程带到AI型号和MCP工具Apr 24, 2025 am 11:16 AMMCP:赋能AI系统访问外部工具 模型上下文协议(MCP)让AI应用能够通过标准化接口与外部工具和数据源交互。由Anthropic开发并得到主要AI提供商的支持,MCP允许语言模型和智能体发现可用工具并使用合适的参数调用它们。然而,实施MCP服务器存在一些挑战,包括环境冲突、安全漏洞以及跨平台行为不一致。 Forbes文章《Anthropic的模型上下文协议是AI智能体发展的一大步》作者:Janakiram MSVDocker通过容器化解决了这些问题。基于Docker Hub基础设施构建的Doc
 使用6种AI街头智能策略来建立一家十亿美元的创业Apr 24, 2025 am 11:15 AM
使用6种AI街头智能策略来建立一家十亿美元的创业Apr 24, 2025 am 11:15 AM有远见的企业家采用的六种策略,他们利用尖端技术和精明的商业敏锐度来创造高利润的可扩展公司,同时保持控制权。本指南是针对有抱负的企业家的,旨在建立一个
 Google照片更新解锁了您所有图片的惊人Ultra HDRApr 24, 2025 am 11:14 AM
Google照片更新解锁了您所有图片的惊人Ultra HDRApr 24, 2025 am 11:14 AMGoogle Photos的新型Ultra HDR工具:改变图像增强的游戏规则 Google Photos推出了一个功能强大的Ultra HDR转换工具,将标准照片转换为充满活力的高动态范围图像。这种增强功能受益于摄影师
 Descope建立AI代理集成的身份验证框架Apr 24, 2025 am 11:13 AM
Descope建立AI代理集成的身份验证框架Apr 24, 2025 am 11:13 AM技术架构解决了新兴的身份验证挑战 代理身份集线器解决了许多组织仅在开始AI代理实施后发现的问题,即传统身份验证方法不是为机器设计的
 Google Cloud Next 2025以及现代工作的未来Apr 24, 2025 am 11:12 AM
Google Cloud Next 2025以及现代工作的未来Apr 24, 2025 am 11:12 AM(注意:Google是我公司的咨询客户,Moor Insights&Strateging。) AI:从实验到企业基金会 Google Cloud Next 2025展示了AI从实验功能到企业技术的核心组成部分的演变,


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

Dreamweaver CS6
视觉化网页开发工具

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

