



随着生成式大模型的不断进步,它们生成的语料正逐步逼近人类。虽然大模型正在解放无数文书的双手,它以假乱真的强劲能力也为一些不法分子所利用,造成了一系列社会问题:



来自北大、华为的研究者们提出了一种识别各式 AI 生成语料的可靠文本检测器。根据长短文本的不同特性,提出了一种基于 PU 学习的多尺度 AI 生成文本检测器训练方法。通过对检测器训练过程的改进,在同等条件下能取得在长、短 ChatGPT 语料上检测能力的可观提升,解决了目前检测器对于短文本识别精度低的痛点。
- 论文地址:https://arxiv.org/abs/2305.18149
- 代码地址 (MindSpore):https://github.com/mindspore-lab/mindone/tree/master/examples/detect_chatgpt
- 代码地址 (PyTorch):https://github.com/YuchuanTian/AIGC_text_detector
引言
随着大语言模型的生成效果越发逼真,各行各业迫切需要一款可靠的 AI 生成文本检测器。然而,不同行业对检测语料的要求不同,例如在学术界,普遍需要对大段完整的学术文本进行检测;在社交平台上,需要对相对简短而较为支离破碎的假消息进行检测。然而,既有检测器往往无法兼顾各式需求。例如,主流的一些 AI 文本检测器对较短的语料预测能力普遍较差。
对于不同长度语料的不同检测效果,作者观察到较短的 AI 生成文本可能存在着一部分归属上的「不确定性」;或者更直白地说,由于一些 AI 生成短句同时也常常被人类使用,因而很难界定 AI 生成的短文本是否来自于人或 AI。这里列举了几个人和 AI 分别对同一问题做出回答的例子:

由这些例子可见,很难对 AI 生成的简短回答进行识别:这类语料与人的区别过小,很难严格判断其真实属性。因此,将短文本简单标注为人类 / AI 并按照传统的二分类问题进行文本检测是不合适的。
针对这个问题,本研究将人类 / AI 的二分类检测部分转化为了一个部分 PU(Positive-Unlabeled)学习问题,即在较短的句子中,人的语言为正类(Positive),机器语言为无标记类(Unlabeled),以此对训练的损失函数进行了改进。此改进可观地提升了检测器在各式语料上的分类效果。
算法细节
在传统的 PU 学习设定下,一个二分类模型只能根据正训练样本和无标记训练样本进行学习。一个常用的 PU 学习方法是通过制定 PU loss 来估计负样本对应的二分类损失:
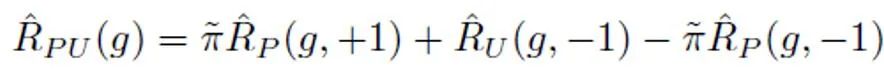
其中,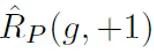 表示正样本与正标签计算的二分类损失;
表示正样本与正标签计算的二分类损失;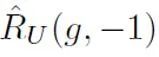 表示将无标记样本全部假定为负标签计算的二分类损失;
表示将无标记样本全部假定为负标签计算的二分类损失;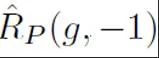 表示将正样本假定为负标签计算的二分类损失;
表示将正样本假定为负标签计算的二分类损失;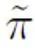 表示的是先验正样本概率,即正样本在全部 PU 样本中的预估占比。在传统的 PU 学习中,通常将先验设置为一个固定的超参数。然而在文本检测的场景中,检测器需要处理各式长度不同的文本;而对于不同长度的文本而言,其正样本在所有和该样本相同长度的 PU 样本中的预估占比也是不同的。因此,本研究对 PU Loss 进行了改进,提出了长度敏感的多尺度 PU(MPU)loss 损失函数。
表示的是先验正样本概率,即正样本在全部 PU 样本中的预估占比。在传统的 PU 学习中,通常将先验设置为一个固定的超参数。然而在文本检测的场景中,检测器需要处理各式长度不同的文本;而对于不同长度的文本而言,其正样本在所有和该样本相同长度的 PU 样本中的预估占比也是不同的。因此,本研究对 PU Loss 进行了改进,提出了长度敏感的多尺度 PU(MPU)loss 损失函数。
具体地,本研究提出了一个抽象的循环模型对较短文本检测进行建模。传统的 NLP 模型在处理序列时,通常是一个马尔可夫链的结构,如 RNN、LSTM 等。此类循环模型的这个过程通常可以理解为一个逐渐迭代的过程,即每个 token 输出的预测,都是由上一个 token 及之前序列的预测结果和该 token 的预测结果经过变换、融合得到的。即以下过程:
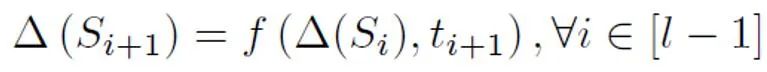
为了根据这个抽象的模型进行先验概率的估计,需要假定该模型的输出为某个句子为正类(Positive)的置信度,即判定为人说出的样本的概率。假设每个 token 的贡献大小为句子 token 长度的反比,是非正(Positive)即无标记(Unlabeled)的,且为无标记的概率远远大于为正的概率。因为随着大模型的词汇量逐渐逼近人类,绝大部分词汇会同时出现在 AI 和人类语料中。根据这个简化后的模型和设定好的正 token 概率,通过求出不同输入情况下模型输出置信度的总期望,来得到最终的先验估计。
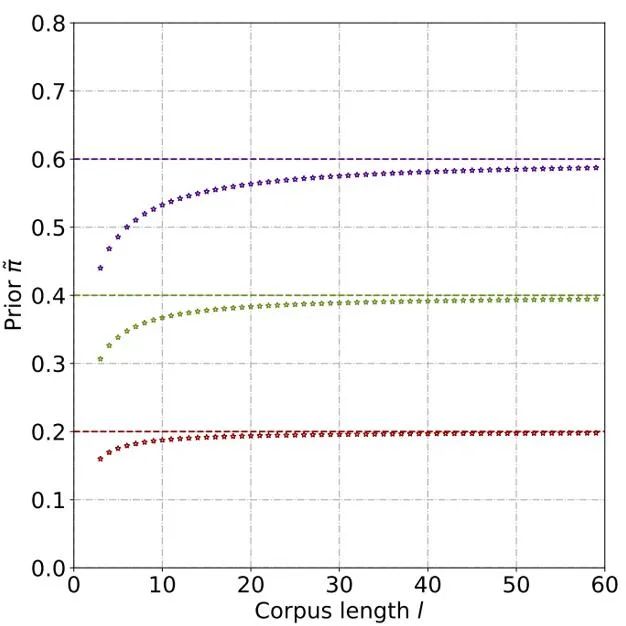
通过理论推导和实验,估计得到先验概率随着文本长度的上升而上升,最终逐渐稳定。这种现象也符合预期,因为随着文本变长,检测器可以捕捉的信息更多,文本的 「来源不确定性」也逐渐减弱:
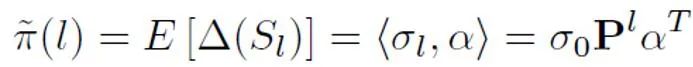
之后,对于每个正样本,根据其样本长度得到的独特先验对 PU loss 进行计算。最后,由于较短文本仅有部分 “不确定性”(即较短文本也会含有一些人或者 AI 的文本特征),可以对二分类 loss 和 MPU loss 进行加权相加,作为最终的优化目标:
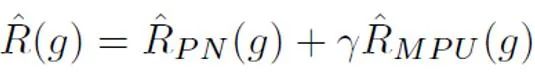
此外需要注意的是,MPU loss 适配的是长度较为多样的训练语料。倘若既有的训练数据单质化明显,大部分语料为大段冗长的文本,则无法全面发挥 MPU 方法的功效。为了使得训练语料的长度更多样化,本研究还引入了一个在句子层面进行多尺度化的模块。该模块随机遮盖训练语料中的部分句子,并对余下句子在保留原有顺序的前提下进行重组。经过训练语料的多尺度化操作,训练文本得到了长度上的极大丰富,从而充分利用了 PU 学习进行 AI 文本检测器训练。
实验结果

如上表所示,作者先在较短的 AI 生成语料数据集 Tweep-Fake 上检验 MPU loss 的效果。该数据集中的语料均为推特上较为短小的语段。作者又在传统的语言模型微调基础上将传统二分类 loss 替换为含有 MPU loss 的优化目标。改进之后的语言模型检测器效果较为突出,超过了其它基线算法。
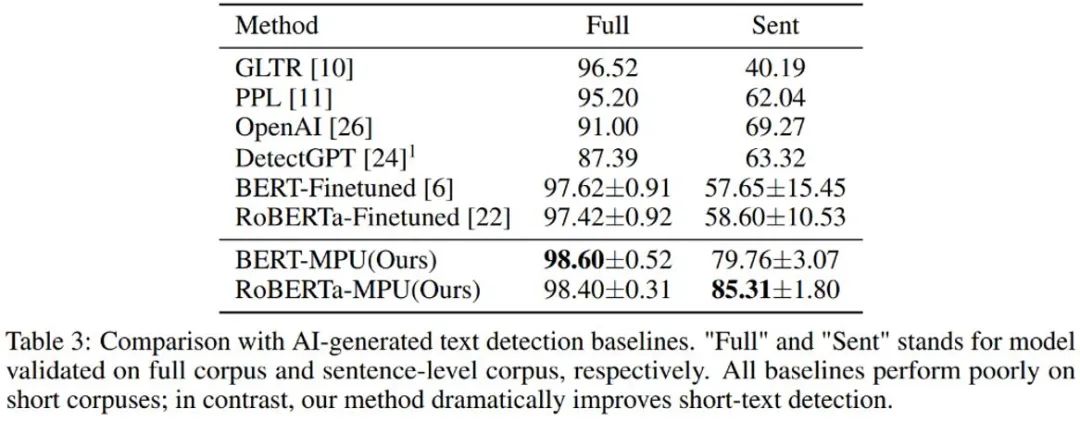
作者又对 chatGPT 生成文本进行了检测,经过传统微调得到的语言模型检测器在短句上表现较差;经过 MPU 方式在同等条件下训练得到的检测器在短句上表现良好,且同时能够在完整语料上取得可观的效果提升,F1-score 提升了 1%,超越了 OpenAI 和 DetectGPT 等 SOTA 算法。
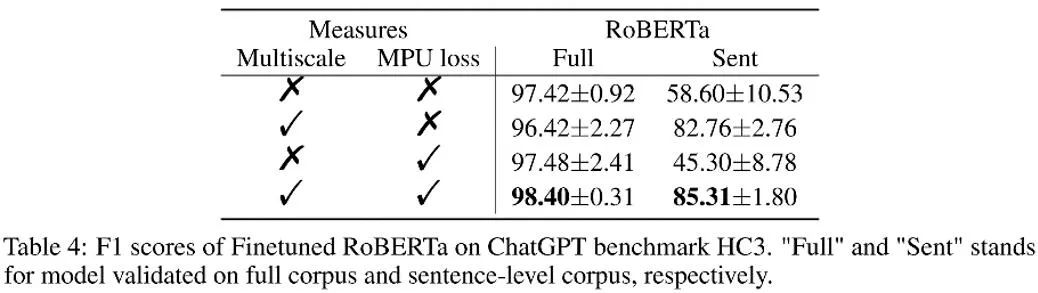
如上表所示,作者在消融实验中观察了每个部分带来的效果增益。MPU loss 加强了长、短语料的分类效果。

作者还对比了传统 PU 和 Multiscale PU(MPU)。由上表可见 MPU 效果更胜一筹,能更好地适配 AI 多尺度文本检测的任务。
总结
作者通过提出基于多尺度 PU 学习的方案,解决了文本检测器对于短句识别的难题,随着未来 AIGC 生成模型的泛滥,对于这类内容的检测将会越来越重要。这项研究在 AI 文本检测的问题上迈出了坚实的一步,希望未来会有更多类似的研究,把 AIGC 内容进行更好的管控,防止 AI 生成内容的滥用。
以上是识别「ChatGPT造假」,效果超越OpenAI:北大、华为的AI生成检测器来了的详细内容。更多信息请关注PHP中文网其他相关文章!

 使用Langchain Text Splitters -Analytics Vidhya拆分数据的7种方法Apr 19, 2025 am 10:11 AM
使用Langchain Text Splitters -Analytics Vidhya拆分数据的7种方法Apr 19, 2025 am 10:11 AMLangchain文本拆分器:优化LLM输入以提高效率和准确性 我们上一篇文章介绍了Langchain的文档加载程序。 但是,LLM具有上下文窗口大小的限制(以代币测量)。 超过此限制会截断数据,comp
 免费生成的AI课程:开创创新的未来Apr 19, 2025 am 10:01 AM
免费生成的AI课程:开创创新的未来Apr 19, 2025 am 10:01 AM生成的AI:革命性的创造力和创新 生成的AI通过按下按钮来创建文本,图像,音乐和虚拟世界来改变行业。 它的影响跨越视频编辑,音乐制作,艺术,娱乐,HEA
 使用通用句子编码器和Wikiqa创建QA模型Apr 19, 2025 am 10:00 AM
使用通用句子编码器和Wikiqa创建QA模型Apr 19, 2025 am 10:00 AM利用嵌入模型的力量来回答高级问题 在当今信息丰富的世界中,立即获得精确答案的能力至关重要。 本文展示了使用强大的提问(QA)模型
 前十名必须阅读机器学习研究论文Apr 19, 2025 am 09:53 AM
前十名必须阅读机器学习研究论文Apr 19, 2025 am 09:53 AM本文探讨了十个彻底改变人工智能(AI)和机器学习(ML)的开创性出版物。 我们将研究神经网络和算法的最新突破,并解释驱动现代AI的核心概念。 Th
 替换SEO机构的11个AI工具 - 分析VidhyaApr 19, 2025 am 09:49 AM
替换SEO机构的11个AI工具 - 分析VidhyaApr 19, 2025 am 09:49 AMAI在SEO中的崛起:超过SEO代理商的前11个工具 AI的快速发展已深刻地重塑了SEO景观。 旨在提高顶级搜索引擎排名的企业正在利用AI优化其在线策略的能力。 来自AU
 前10个免费的AI游乐场供您在2025年尝试-Analytics VidhyaApr 19, 2025 am 09:45 AM
前10个免费的AI游乐场供您在2025年尝试-Analytics VidhyaApr 19, 2025 am 09:45 AM探索2024年最好的免费AI游乐场:综合指南 访问正确的工具和平台是在不断发展的人工智能(AI)领域学习和创新的关键。 AI游乐场提供了绝佳的机会
 矢量数据库中索引算法的详细指南Apr 19, 2025 am 09:41 AM
矢量数据库中索引算法的详细指南Apr 19, 2025 am 09:41 AM介绍 向量数据库是专门的数据库,旨在有效地存储和检索高维矢量数据。 这些向量代表数据点的特征或属性,范围从数十到数千个维度,具体取决于
 反向扩散过程是什么? - 分析VidhyaApr 19, 2025 am 09:40 AM
反向扩散过程是什么? - 分析VidhyaApr 19, 2025 am 09:40 AM稳定的扩散:揭示反向扩散的魔力 稳定的扩散是一种强大的生成模型,能够从噪声中产生高质量的图像。此过程涉及两个关键步骤:正向扩散过程(在上一个A中详细介绍


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

SublimeText3汉化版
中文版,非常好用

Dreamweaver Mac版
视觉化网页开发工具

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

