
把大模型装进摄像机,需要怎样的AI芯片?爱芯元智的答案是AX650N

- 王林转载
- 2023-06-03 10:33:21919浏览

芯东西(公众号:aichip001)
作者 | ZeR0
编辑 | 漠影
一种重写方式是:AI大模型竞赛正掀起前所未有的热潮,据5月30日芯东西报道,ChatGPT的崛起是此次竞赛的关键驱动力。在这场竞赛中,速度是抢得先发优势的关键,从模型训练到落地部署,都对更高性能的AI芯片提出迫切需求。
今年3月,AI视觉感知芯片研发及基础算力平台公司爱芯元智推出了第三代高算力、高能效比的SoC芯片AX650N。爱芯元智联合创始人、副总裁刘建伟在近日接受芯东西等媒体采访时谈道,AX650N芯片在跑Transformer时优势明显,而Transformer是当前大模型普遍采用的结构。
Transformer最初被用于处理自然语言处理领域的任务,逐渐向计算机视觉领域拓展,并展现出在越来越多视觉任务中取代传统主流计算机视觉算法CNN的潜能。如何在端侧、边缘侧高效部署Transformer,随之成为越来越多有大模型部署需求的用户选择平台的核心考量要素。
相比在云端使用GPU部署Transformer大模型,爱芯元智认为,在边缘侧、端侧部署Transformer的最大挑战来自功耗,这使得爱芯元智兼具高性能和低功耗的混合精度NPU成为端侧和边缘侧部署Transformer的首选平台。
数据显示,在爱芯元智AX650N平台上运行主流的视觉模型Swin Transformer(SwinT),性能高达361FPS,精度高达80.45%,而功耗低至199FPS/W,这在落地部署中很有竞争力。
一、兼具高算力与高能效比,已适配多种Transformer模型
AX650N芯片是继AX620、AX630系列后,爱芯元智推出的又一款高性能智能视觉芯片。
这款SoC采用异构多核设计,集成了8核A55 CPU、43.2TOPs@INT4或10.8TOPs@INT8高算力的NPU、支持8K@30fps的ISP,以及H.264、H.265编解码的VPU。
接口方面,AX650N支持64bit LPDDR4x,多路MIPI输入,千兆Ethernet、USB以及HDMI 2.0b输出,并支持32路1080p@30fps解码。
针对大模型在边缘侧、端侧的部署,AX650N具有高性能、高精度、低功耗、易部署的优势。
具体来看,爱芯元智AX650N在运行SwinT时,361帧的高性能可媲美汽车自动驾驶领域基于GPU的高端域控SoC;80.45%的高精度高于市面平均水平;199FPS/W速度反映出低功耗,比目前基于GPU的高端域控SoC有着数倍的优势。

爱芯元智解释说,早期边缘侧、端侧客户比较看重算力有多少T,但这是一个间接数据,用户最终关心的是在实际业务中模型能跑得多快,以及部署成本和使用成本有多低。
对此,AX650N支持低比特混合精度,用户如果采用INT4,则可以极大地减少内存和带宽占用率,有效控制端侧边缘侧部署的成本。
目前AX650N已适配ViT/DeiT、Swin/SwinV2、DETR等Transformer模型,在DINOv2也能跑到30帧以上,这使得用户进行检测、分类、分割等操作更加方便。AX650N-based products have already been applied in important computer vision scenarios such as smart cities, smart education, and intelligent manufacturing.。

二、部署大模型易上手,可运行GitHub原版模型
爱芯元智还打造了新一代AI工具链Pulsar2。该工具链包含模型转换、离线量化、模型编译、异构调度四合一功能,进一步强化了网络模型高效部署的需求,在针对NPU架构进行了深度优化的同时,也扩展了算子&模型支持的能力及范围,以及对Transformer结构网络的支持。
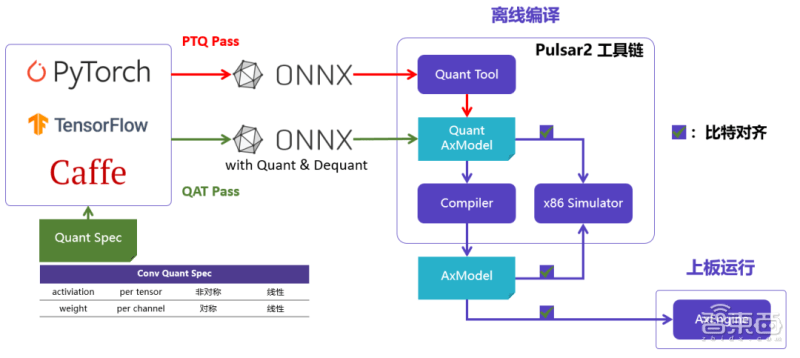
爱芯元智在实践中发现,市面上宣传芯片能跑SwinT的公司,通常需要对模型做一些修改,修改后可能会引发一系列问题,给用户带来更多的不便。
此前类似于SwinT的视觉类Transformer模型大多数部署在云端服务器上,原因是GPU对于MHA结构计算支持更友好,反而边缘侧/端侧AI芯片由于其架构限制,为了保证CNN结构的模型效率更好,基本上没有对MHA结构做过多性能优化,甚至需要修改网络结构才能勉强部署。
而AX650N具有部署方便的特点。您可以在爱芯元智平台上高效运行GitHub上的原版模型,无需对其进行修改,也不需要进行QAT重新训练。
“我们的用户反馈,我们的平台是目前看到对Transformer支持最好的一个平台,也看到在我们这个平台来落地大模型的可能性。”刘建伟谈道,客户能够体会到AX650N作为AI算力平台,最终落地效果更好用、更易用,对场景的适应性较强,上手速度也比较快,大幅提升了用户的效率,缩短量产周期。
爱芯元智收集到的客户反馈显示,拿到爱芯元智的开发板和文档后,基本上1小时就能完成demo的复现以及运行私有网络模型。
AX650N芯片能够迅速适应新出现的网络结构,这要归功于在硬件和软件设计方面的一定灵活性和可编程性的保持。接下来,爱芯元智AX650N将针对Transformer结构进行持续优化,探索多模态大模型等更多的Transformer大模型。
爱芯元智还将基于AX650N推出AXera-Pi Pro开发板,并在GitHub放上更丰富的资料及AI示例,以便开发者快速探索更丰富的产品应用。
三、视觉类应用场景已对Transformer模型产生迫切需求
在爱芯元智看来,在边缘侧或端侧部署视觉大模型,有助于解决长尾场景下AI智能应用投入太高的问题。
以前的河道垃圾监测方式是发现河道上的垃圾后,需要先进行数据采集、标注,然后进行模型训练。如果新垃圾出现在河道中,而这种垃圾之前没有被数据标注和训练模型覆盖,那么该模型就可能无法识别它。从头重新训练又费时耗力。
而Transformer大模型具备语义理解能力,拥有比传统CNN模型更强的通用性,不需要预先知道所有的复杂视觉场景,就能理解和执行更广泛的下游任务。使用无监督训练的预训练大模型,可以识别以前从未见过的新垃圾。
爱芯元智告诉芯东西,目前凡是用摄像头去捕捉画面的应用场景,都已经开始对Transformer大模型产生比较迫切的需求,具体落地速度则取决于各细分领域客户自身的研发及资源投入情况。
从芯片架构设计角度来看,要让Transformer模型更快部署在边缘侧或端侧,一方面要设法降低大模型带宽的使用情况,另一方面需针对Transformer的结构进行优化。爱芯元智相关负责人称,AX650N在实际部署中积累的工程经验将迭代到下一代芯片平台中,让Transformer模型跑得更快更好,相比其他同行有一定先发优势。
“这也是为什么说爱芯的芯片平台是Transformer落地的最佳选择,因为大家在做模型变小的过程中,一定是想看在端侧跑的效果,我们有这样的平台可以做这样闭环的试验。”他谈道。
为了进一步优化Transformer推理效果,爱芯元智将聚焦于如何让硬件高效读取离散数据,以及让配套的计算能够和数据读取匹配起来。此外,爱芯元智也在尝试用4bit来解决模型参数量大的问题,并探索对一些稀疏化或混合专家系统(MOE、Mixture of Experts)模型的支持。
结语:高性能AI芯片铸就大模型部署基石
从2020年实现首颗高性能AI视觉芯片AX630A量产,2021年点亮第二代自研边缘侧智能芯片 AX620A,再到最新发布的第三代AX650N芯片,爱芯元智通过持续推出高算力、高能效比的AI视觉芯片,满足端侧和边缘侧的AI应用需求。
爱芯元智创始人、董事长兼首席执行官仇肖莘博士说,人工智能技术发展不断催生新机遇,此前的几波技术浪潮曾推动爱芯元智在视觉处理、汽车电子等芯片技术上的进展,近期大模型的爆发则为爱芯过去几年在端侧、边缘侧的坚持探索创造了新机会。
而爱芯相关研发和落地规划都剑指一个目标,即用户或潜在用户一想到Transformer,就能想到爱芯元智,进而在爱芯元智的AI算力平台上开发更多基于Transformer模型的应用,最终加速大模型及智能应用在端侧和边缘侧落地的节奏。
反过来,更多部署经验的沉淀,也会推动爱芯元智的芯片与软件持续进化,通过提供更高性能、更好用易用的工具,助力算法工程师进一步推开Transformer模型创新应用的想象力之门。
以上是把大模型装进摄像机,需要怎样的AI芯片?爱芯元智的答案是AX650N的详细内容。更多信息请关注PHP中文网其他相关文章!