




InnoDB是一种存储引擎,它可以将表中的数据存储到磁盘上,因此在重启后即使服务器已关机,我们的数据仍然可以被保留。而真正处理数据的过程是发生在内存中的,所以需要把磁盘中的数据加载到内存中,如果是处理写入或修改请求的话,还需要把内存中的内容刷新到磁盘上。而我们知道读写磁盘的速度非常慢,和内存读写差了几个数量级,所以当我们想从表中获取某些记录时,InnoDB存储引擎需要一条一条的把记录从磁盘上读出来么?
InnoDB采取的方式是:将数据划分为若干个页,以页作为磁盘和内存之间交互的基本单位,InnoDB中页的大小一般为16KB。也就是在一般情况下,一次最少从磁盘中读取16KB的内容到内存中,一次最少把内存中的16KB内容刷新到磁盘中。
mysql> show variables like '%innodb_page_size%'; +------------------+-------+ | Variable_name | Value | +------------------+-------+ | innodb_page_size | 16384 | +------------------+-------+ 1 row in set (0.00 sec)
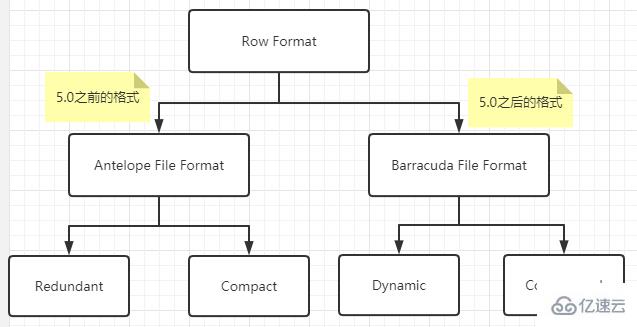
我们通常按记录为单位将数据插入表中,这些记录存储在磁盘上的方式也被称为行格式或记录格式。InnoDB存储引擎设计了4种不同类型的行格式,分别是Compact、Redundant、Dynamic和Compressed行格式。
行记录格式的分类和介绍
在早期的InnoDB版本中,由于文件格式只有一种,因此不需要为此文件格式命名。为了支持新功能,针对早期版本不兼容的情况,InnoDB引擎已经开发出了新的文件格式。为了在升级和降级情况下帮助管理系统的兼容性,以及运行不同的MySQL版本,InnoDB开始使用命名的文件格式。
在msyql 5.7.9及以后版本,默认行格式由innodb_default_row_format变量决定,它的默认值是dynamic:
mysql> show variables like "innodb_file_format"; +--------------------+-----------+ | Variable_name | Value | +--------------------+-----------+ | innodb_file_format | Barracuda | +--------------------+-----------+ 1 row in set (0.01 sec) mysql> show variables like "innodb_default_row_format"; +---------------------------+---------+ | Variable_name | Value | +---------------------------+---------+ | innodb_default_row_format | dynamic | +---------------------------+---------+ 1 row in set (0.00 sec)
查看当前表使用的行格式:
mysql> show table status like 'dept_emp'\G*************************** 1. row ***************************
Name: dept_emp Engine: InnoDB
Version: 10
Row_format: Dynamic Rows: 331570
Avg_row_length: 36
Data_length: 12075008Max_data_length: 0
Index_length: 5783552
Data_free: 0
Auto_increment: NULL
Create_time: 2021-08-11 09:04:36
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options: Comment:1 row in set (0.00 sec)指定表的行格式:
CREATE TABLE 表名(列的信息) ROW_FORMAT=行格式名称ALTER TABLE 表名 ROW_FORMAT=行格式名称;
如果要修改现有表的行模式为compressed或dynamic,必须先将文件格式设置成Barracuda:set global innodb_file_format=Barracuda;,再用ALTER TABLE tablename ROW_FORMAT=COMPRESSED;去修改才能生效。
行格式
COMPACT
变长字段列表
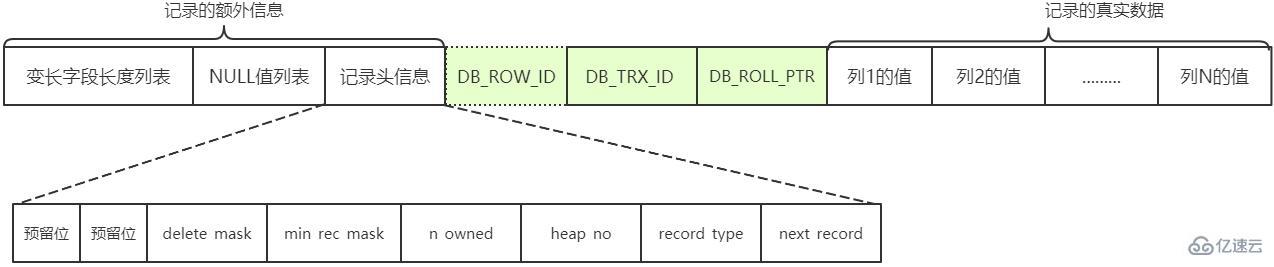
MySQL支持一些变长的数据类型,比如VARCHAR(M)、VARBINARY(M)、各种TEXT类型,各种BLOB类型,我们也可以把拥有这些数据类型的列称为变长字段,变长字段中存储多少字节的数据是不固定的,所以我们在存储真实数据的时候需要顺便把这些数据占用的字节数也存起来。如果该可变字段允许存储的最大字节数(M×W)超过255字节并且真实存储的字节数(L)超过127字节,则使用2个字节记录,否则使用1个字节记录。
问题一:那么为什么用128作为分界线呢? 一个字节可以最多表示255,但是MySQL设计长度表示时,为了区分是否是一个字节表示长度,规定,如果最高位为1,那么就是两个字节表示长度,否则就是一个字节。例如,01111111,这个就代表长度为127,而如果长度是128,就需要两个字节,就是10000000 10000000,首个字节的最高位为1,那么这就是两个字节表示长度的开头,第二个字节可以用所有位表示长度,并且需要注意的是,MySQL采取Little Endian的计数方式,低位在前,高位在后,所以129就是10000001 10000000。这种标识方法的最大长度为32767,即32KB。
问题二:如果两个字节也不够表示的长度,该怎么办? innoDB页大小默认为16KB,对于一些占用字节数非常多的字段,比方说某个字段长度大于了16KB,那么如果该记录在单个页面中无法存储时,InnoDB会把一部分数据存放到所谓的溢出页中,在变长字段长度列表处只存储留在本页面中的长度,所以使用两个字节也可以存放下来。这个溢出页机制参考后面的数据溢出。
NULL值列表
表中的某些列可能存储NULL值,如果把这些NULL值都放到记录的真实数据中存储会很占地方,所以Compact行格式把这些值为NULL的列统一管理起来,存储到NULL值列表。对于每个可以存储NULL的列,都会有一个对应的二进制位,当该二进制位的值为1时,表示该列的值为NULL。二进制位的值为0时,代表该列的值不为NULL。
记录头信息
用于描述记录的记录头信息,它是由固定的5个字节组成。5个字节也就是40个二进制位,不同的位代表不同的意思。
| 字段 | 长度(bit) | 说明 |
|---|---|---|
| 预留位1 | 1 | 没有使用 |
| 预留位2 | 1 | 没有使用 |
| delete_mask | 1 | 标记该记录是否被删除 |
| min_rec_mask | 1 | B+树的每层非叶子节点中的最小记录都会添加该标记 |
| n_owned | 4 | 表示当前记录拥有的记录数 |
| heap_no | 13 | 表示当前记录在页的位置信息 |
| record_type | 3 | 表示当前记录的类型,0 表示普通记录,1 表示B+树非叶子节点记录,2 表示最小记录,3 表示最大记录 |
| next_record | 16 | 表示下一条记录的相对位置 |
隐藏列
记录的真实数据除了我们自己定义的列的数据以外,MySQL会为每个记录默认的添加一些列(也称为隐藏列),包括:
DB_ROW_ID(row_id):非必须,6字节,表示行ID,唯一标识一条记录
DB_TRX_ID:必须,6字节,表示事务ID
DB_ROLL_PTR:必须,7字节,表示回滚指针
InnoDB表对主键的生成策略是:优先使用用户自定义主键作为主键,如果用户没有定义主键,则选取一个Unique键作为主键,如果表中连Unique 键都没有定义的话,则InnoDB会为表默认添加一个名为row_id的隐藏列作为主键。
DB_TRX_ID(也可以称为trx_id) 和DB_ROLL_PTR(也可以称为roll_ptr) 这两个列是必有的,但是row_id是可选的(在没有自定义主键以及Unique 键的情况下才会添加该列)。
其他的行格式和Compact行格式差别不大。
Redundant行格式
Redundant行格式是MySQL5.0之前用的一种行格式,不予深究。
Dynamic行格式
MySQL5.7的默认行格式就是Dynamic,Dynamic行格式和Compact行格式挺像,只不过在处理行溢出数据时有所不同。
Compressed行格式
Compressed行格式在Dynamic行格式的基础上会采用压缩算法对页面进行压缩,以节省空间。以zlib的算法进行压缩,因此对于BLOB、TEXT、VARCHAR这类大长度数据能够进行有效的存储(减少40%,但对CPU要求更高)。
数据溢出
如果我们定义一个表,表中只有一个VARCHAR字段,如下:
CREATE TABLE test_varchar( c VARCHAR(60000))
然后往这个字段插入60000个字符,会发生什么?前边说过,MySQL中磁盘和内存交互的基本单位是页,也就是说MySQL是以页为基本单位来管理存储空间的,我们的记录都会被分配到某个页中存储。而一个页的大小一般是16KB,也就是16384字节,而一个VARCHAR(M)类型的列就最多可以存储65532个字节,这样就可能造成一个页存放不了一条记录的情况。
在Compact和Redundant行格式中,对于占用存储空间非常大的列,在记录的真实数据处只会存储该列的该列的前768个字节的数据,然后把剩余的数据分散存储在几个其他的页中,记录的真实数据处用20个字节(768字节后20个字节)存储指向这些页的地址。这个过程也叫做行溢出,存储超出768字节的那些页面也被称为溢出页。
Dynamic和Compressed行格式,不会在记录的真实数据处存储字段真实数据的前768个字节,而是把所有的字节都存储到其他页面中,只在记录的真实数据处存储其他页面的地址。
实战分析行格式
准备表及数据:
create table row_test ( t1 varchar(10), t2 varchar(10), t3 char(10), t4 varchar(10) ) engine=innodb charset=latin1 row_format=compact; insert into row_test values('a','bb','bb','ccc'); insert into row_test values('d','ee','ee','fff'); insert into row_test values('d',NULL,NULL,'fff');
在Linux环境下,使用hexdump -C -v mytest.ibd>mytest.txt,打开mytest.txt文件,找到如下内容:
0000c070 73 75 70 72 65 6d 75 6d 03 02 01 00 00 00 10 00 |supremum........| 0000c080 2c 00 00 00 00 02 00 00 00 00 00 0f 61 c8 00 00 |,...........a...| 0000c090 01 d4 01 10 61 62 62 62 62 20 20 20 20 20 20 20 |....abbbb | 0000c0a0 20 63 63 63 03 02 01 00 00 00 18 00 2b 00 00 00 | ccc........+...| 0000c0b0 00 02 01 00 00 00 00 0f 62 c9 00 00 01 b2 01 10 |........b.......| 0000c0c0 64 65 65 65 65 20 20 20 20 20 20 20 20 66 66 66 |deeee fff| 0000c0d0 03 01 06 00 00 20 ff 98 00 00 00 00 02 02 00 00 |..... ..........| 0000c0e0 00 00 0f 67 cc 00 00 01 b6 01 10 64 66 66 66 00 |...g.......dfff.|
该行记录从0000c078开始,第一行整理如下:
03 02 01 // 变长字段长度列表,逆序,t4列长度为3,t2列长度为2,t1列长度为1 00 // NULL标志位,第一行没有NULL值 00 00 10 00 2c // 记录头信息,固定5字节长度 00 00 00 2b 68 00 // RowID我们建的表没有主键,因此会有RowID,固定6字节长度 00 00 00 00 06 05 // 事务ID,固定6个字节80 00 00 00 32 01 10 // 回滚指针,固定7个字节61 // t1数据'a'62 62 // t2'bb'62 62 20 20 20 20 20 20 20 20 // t3数据'bb'63 63 63 // t4数据'ccc'
第二行整理如下:
03 02 01 // 变长字段长度列表,逆序,t4列长度为3,t2列长度为2,t1列长度为1 00 // NULL标志位,第二行没有NULL值 00 00 18 00 2b // 记录头信息,固定5字节长度 00 00 00 00 02 01 // RowID我们建的表没有主键,因此会有RowID,固定6字节长度 00 00 00 00 0f 62 // 事务ID,固定6个字节 c9 00 00 01 b2 01 10 // 回滚指针,固定7个字节64 // t1数据'd'65 65 // t2数据'ee'65 65 20 20 20 20 20 20 20 20 // t3数据'ee'66 66 66 // t4数据'fff'
第三行整理如下:
03 01 // 变长字段长度列表,逆序,t4列长度为3,t1列长度为1 06 // 00000110 NULL标志位,t2和t3列为空 00 00 20 ff 98 // 记录头信息,固定5字节长度 00 00 00 00 02 02 // RowID我们建的表没有主键,因此会有RowID,固定6字节长度 00 00 00 00 0f 67 // 事务ID,固定6个字节 cc 00 00 01 b6 01 10 // 回滚指针,固定7个字节64 // t1数据'd'66 66 66 // t4数据'fff'
接下来更新下数据:
mysql> update row_test set t2=null where t1='a'; Query OK, 1 row affected (0.02 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> delete from row_test where t2='ee'; Query OK, 1 row affected (0.01 sec)
查看二进制内容(需要等一会,有可能只写入了缓存,磁盘上的文件并没有更新):
0000c070 73 75 70 72 65 6d 75 6d 03 01 02 00 00 10 00 58 |supremum.......X| 0000c080 00 00 00 00 02 00 00 00 00 00 0f 68 4d 00 00 01 |...........hM...| 0000c090 9e 04 a9 61 62 62 20 20 20 20 20 20 20 20 63 63 |...abb cc| 0000c0a0 63 63 63 63 03 02 01 00 20 00 18 00 00 00 00 00 |cccc.... .......| 0000c0b0 00 02 01 00 00 00 00 0f 6a 4e 00 00 01 9f 10 c0 |........jN......| 0000c0c0 64 65 65 65 65 20 20 20 20 20 20 20 20 66 66 66 |deeee fff| 0000c0d0 03 01 06 00 00 20 ff 98 00 00 00 00 02 02 00 00 |..... ..........| 0000c0e0 00 00 0f 67 cc 00 00 01 b6 01 10 64 66 66 66 00 |...g.......dfff.|
该行记录从0000c078开始,第一行整理如下:
03 01 // 变长字段长度列表,逆序,t4列长度为3,t1列长度为1 02 // 0000 0010 NULL标志位,表示t2为null 00 00 10 00 58 // 记录头信息,固定5字节长度 00 00 00 00 02 00 // RowID我们建的表没有主键,因此会有RowID,固定6字节长度 00 00 00 00 0f 68 // 事务ID,固定6个字节 4d 00 00 01 9e 04 a9 // 回滚指针,固定7个字节61 // t1数据'a'62 62 20 20 20 20 20 20 20 20 // t3数据'bb'63 63 63 // t4数据'ccc'
第二行整理如下:
03 02 01 // 变长字段长度列表,逆序,t4列长度为3,t2列长度为2,t1列长度为1 00 // NULL标志位,第二行没有NULL值20 00 18 00 00 // 0010 delete_mask=1 标记该记录是否被删除 记录头信息,固定5字节长度 00 00 00 00 02 01 // RowID我们建的表没有主键,因此会有RowID,固定6字节长度 00 00 00 00 0f 6a // 事务ID,固定6个字节 4e 00 00 01 9f 10 c0 // 回滚指针,固定7个字节64 // t1数据'd'65 65 // t2数据'ee'65 65 20 20 20 20 20 20 20 20 // t3数据'ee'66 66 66 // t4数据'fff'
第三行数据未发生变化。
以上是MySQL如何从二进制内容看InnoDB行格式的详细内容。更多信息请关注PHP中文网其他相关文章!

 说明InnoDB重做日志和撤消日志的作用。Apr 15, 2025 am 12:16 AM
说明InnoDB重做日志和撤消日志的作用。Apr 15, 2025 am 12:16 AMInnoDB使用redologs和undologs确保数据一致性和可靠性。1.redologs记录数据页修改,确保崩溃恢复和事务持久性。2.undologs记录数据原始值,支持事务回滚和MVCC。
 在解释输出(类型,键,行,额外)中要查找的关键指标是什么?Apr 15, 2025 am 12:15 AM
在解释输出(类型,键,行,额外)中要查找的关键指标是什么?Apr 15, 2025 am 12:15 AMEXPLAIN命令的关键指标包括type、key、rows和Extra。1)type反映查询的访问类型,值越高效率越高,如const优于ALL。2)key显示使用的索引,NULL表示无索引。3)rows预估扫描行数,影响查询性能。4)Extra提供额外信息,如Usingfilesort提示需要优化。
 在解释中使用临时状态以及如何避免它是什么?Apr 15, 2025 am 12:14 AM
在解释中使用临时状态以及如何避免它是什么?Apr 15, 2025 am 12:14 AMUsingtemporary在MySQL查询中表示需要创建临时表,常见于使用DISTINCT、GROUPBY或非索引列的ORDERBY。可以通过优化索引和重写查询避免其出现,提升查询性能。具体来说,Usingtemporary出现在EXPLAIN输出中时,意味着MySQL需要创建临时表来处理查询。这通常发生在以下情况:1)使用DISTINCT或GROUPBY时进行去重或分组;2)ORDERBY包含非索引列时进行排序;3)使用复杂的子查询或联接操作。优化方法包括:1)为ORDERBY和GROUPB
 描述不同的SQL交易隔离级别(读取未读取,读取,可重复的读取,可序列化)及其在MySQL/InnoDB中的含义。Apr 15, 2025 am 12:11 AM
描述不同的SQL交易隔离级别(读取未读取,读取,可重复的读取,可序列化)及其在MySQL/InnoDB中的含义。Apr 15, 2025 am 12:11 AMMySQL/InnoDB支持四种事务隔离级别:ReadUncommitted、ReadCommitted、RepeatableRead和Serializable。1.ReadUncommitted允许读取未提交数据,可能导致脏读。2.ReadCommitted避免脏读,但可能发生不可重复读。3.RepeatableRead是默认级别,避免脏读和不可重复读,但可能发生幻读。4.Serializable避免所有并发问题,但降低并发性。选择合适的隔离级别需平衡数据一致性和性能需求。
 MySQL与其他数据库:比较选项Apr 15, 2025 am 12:08 AM
MySQL与其他数据库:比较选项Apr 15, 2025 am 12:08 AMMySQL适合Web应用和内容管理系统,因其开源、高性能和易用性而受欢迎。1)与PostgreSQL相比,MySQL在简单查询和高并发读操作上表现更好。2)相较Oracle,MySQL因开源和低成本更受中小企业青睐。3)对比MicrosoftSQLServer,MySQL更适合跨平台应用。4)与MongoDB不同,MySQL更适用于结构化数据和事务处理。
 MySQL索引基数如何影响查询性能?Apr 14, 2025 am 12:18 AM
MySQL索引基数如何影响查询性能?Apr 14, 2025 am 12:18 AMMySQL索引基数对查询性能有显着影响:1.高基数索引能更有效地缩小数据范围,提高查询效率;2.低基数索引可能导致全表扫描,降低查询性能;3.在联合索引中,应将高基数列放在前面以优化查询。
 MySQL:新用户的资源和教程Apr 14, 2025 am 12:16 AM
MySQL:新用户的资源和教程Apr 14, 2025 am 12:16 AMMySQL学习路径包括基础知识、核心概念、使用示例和优化技巧。1)了解表、行、列、SQL查询等基础概念。2)学习MySQL的定义、工作原理和优势。3)掌握基本CRUD操作和高级用法,如索引和存储过程。4)熟悉常见错误调试和性能优化建议,如合理使用索引和优化查询。通过这些步骤,你将全面掌握MySQL的使用和优化。
 现实世界Mysql:示例和用例Apr 14, 2025 am 12:15 AM
现实世界Mysql:示例和用例Apr 14, 2025 am 12:15 AMMySQL在现实世界的应用包括基础数据库设计和复杂查询优化。1)基本用法:用于存储和管理用户数据,如插入、查询、更新和删除用户信息。2)高级用法:处理复杂业务逻辑,如电子商务平台的订单和库存管理。3)性能优化:通过合理使用索引、分区表和查询缓存来提升性能。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

Atom编辑器mac版下载
最流行的的开源编辑器

记事本++7.3.1
好用且免费的代码编辑器

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

WebStorm Mac版
好用的JavaScript开发工具

