



大模型时代,什么最重要?
LeCun曾经给出的答案是:开源。
当Meta的LLaMA的代码在GitHub上被泄露时,全球的开发者们都可以访问这个第一个达到GPT水平的LLM。
接下来,各种各样的LLM给AI模型开源赋予了各种各样的角度。
LLaMA给斯坦福的Alpac和Vicuna等模型铺设了道路,搭好了舞台,让他们成为了开源的领头羊。
而就在此时,猎鹰「Falcon」又杀出了重围。
Falcon 猎鹰
「Falcon」由阿联酋阿布扎比的技术创新研究所(TII)开发,从性能上看,Falcon比LLaMA的表现更好。
目前,「Falcon」有三个版本——1B、7B和40B。
TII表示,Falcon迄今为止最强大的开源语言模型。其最大的版本,Falcon 40B,拥有400亿参数,相对于拥有650亿参数的LLaMA来说,规模上还是小了一点。
规模虽小,性能能打。
先进技术研究委员会(ATRC)秘书长Faisal Al Bannai认为,「Falcon」的发布将打破LLM的获取方式,并让研究人员和创业者能够以此提出最具创新性的使用案例。
FalconLM的两个版本,Falcon 40B Instruct和Falcon 40B在Hugging Face OpenLLM排行榜上位列前两名,而Meta的LLaMA位于第三。
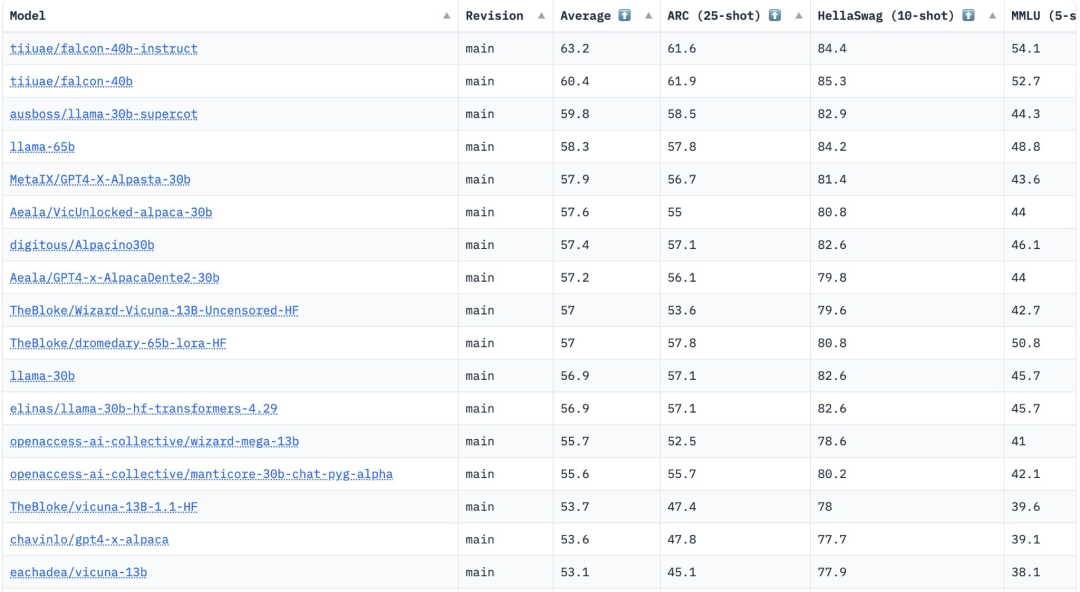
值得一提的是,Hugging Face是通过四个当前比较流形的基准——AI2 Reasoning Challenge,HellaSwag,MMLU和TruthfulQA对这些模型进行评估的。
尽管「Falcon」的论文目前还没公开发布,但Falcon 40B已经在经过精心筛选的1万亿token网络数据集的上进行了大量训练。
研究人员透露,「Falcon」在训练过程非常重视在大规模数据上实现高性能的重要性。
我们都知道的是,LLM对训练数据的质量非常敏感,这就是为什么研究人员会花大量的精力构建一个能够在数万个CPU核心上进行高效处理的数据管道。
目的就是,在过滤和去重的基础上从网络中提取高质量的内容。
目前,TII已经发布了精炼的网络数据集,这是一个经过精心过滤和去重的数据集。实践证明,非常有效。
仅用这个数据集训练的模型可以和其它LLM打个平手,甚至在性能上超过他们。这展示出了「Falcon」卓越的质量和影响力。

此外,Falcon模型也具有多语言的能力。
它理解英语、德语、西班牙语和法语,并且在荷兰语、意大利语、罗马尼亚语、葡萄牙语、捷克语、波兰语和瑞典语等一些欧洲小语种上也懂得不少。
Falcon 40B还是继H2O.ai模型发布后,第二个真正开源的模型。然而,由于H2O.ai并未在此排行榜上与其他模型进行基准对比,所以这两个模型还没上过擂台。
而回过头看LLaMA,尽管它的代码在GitHub上可以获取,但它的权重(weights)从未开源。
这意味着该模型的商业使用受到了一定程度的限制。
而且,LLaMA的所有版本都依赖于原始的LLaMA许可证,这就使得LLaMA不适合小规模的商业应用。
在这一点上,「Falcon」又拔得了头筹。
唯一免费的商用大模型!
Falcon是目前唯一的可以免费商用的开源模型。
在早期,TII要求,商业用途使用Falcon,如果产生了超过100万美元以上的可归因收入,将会收取10%的「使用税」。
可是财大气粗的中东土豪们没过多长时间就取消了这个限制。
至少到目前为止,所有对Falcon的商业化使用和微调都不会收取任何费用。
土豪们表示,现在暂时不需要通过这个模型挣钱。
而且,TII还在全球征集商用化方案。
对于有潜力的科研和商业化方案,他们还会提供更多的「训练算力支持」,或者提供进一步的商业化机会。

项目提交邮箱:Submissions.falconllm@tii.ae
这简直就是在说:只要项目好,模型免费用!算力管够!钱不够我们还能给你凑!
对于初创企业来说,这简直就是来自中东土豪的「AI大模型创业一站式解决方案」。
高质量的训练数据
根据开发团队称,FalconLM 竞争优势的一个重要方面是训练数据的选择。
研究团队开发了一个从公共爬网数据集中提取高质量数据并删除重复数据的流程。
在彻底清理多余重复内容后,保留了 5 万亿的token——足以训练强大的语言模型。
40B的Falcon LM使用1万亿个token进行训练, 7B版本的模型训练token达到 1.5 万亿。
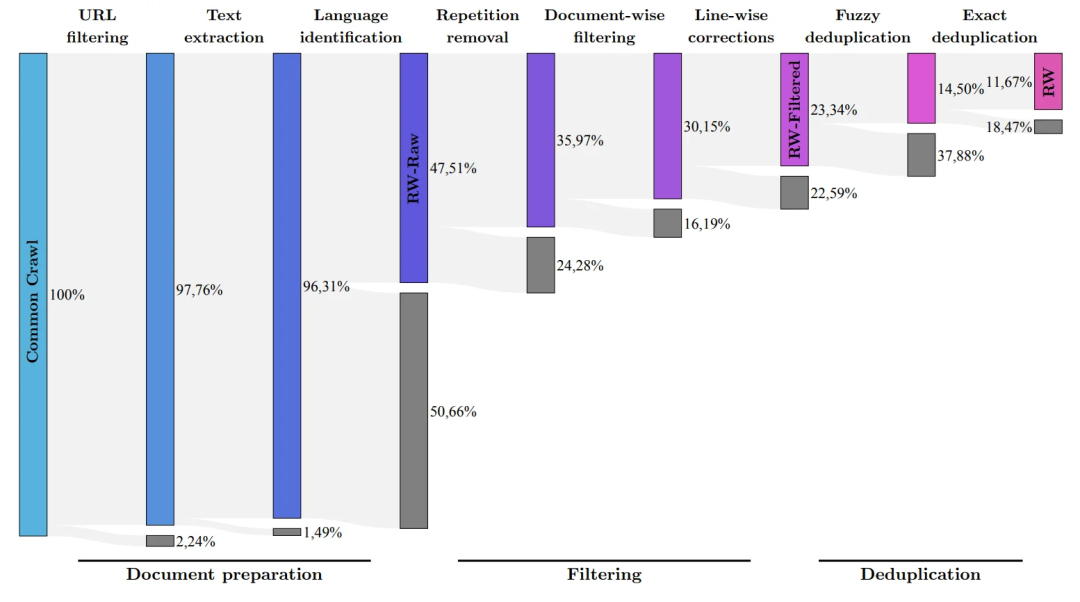
(研究团队的目标是使用RefinedWeb数据集从Common Crawl中仅过滤出质量最高的原始数据)
更加可控的训练成本
TII称,与GPT-3相比,Falcon在只使用75%的训练计算预算的情况下,就实现了显著的性能提升。
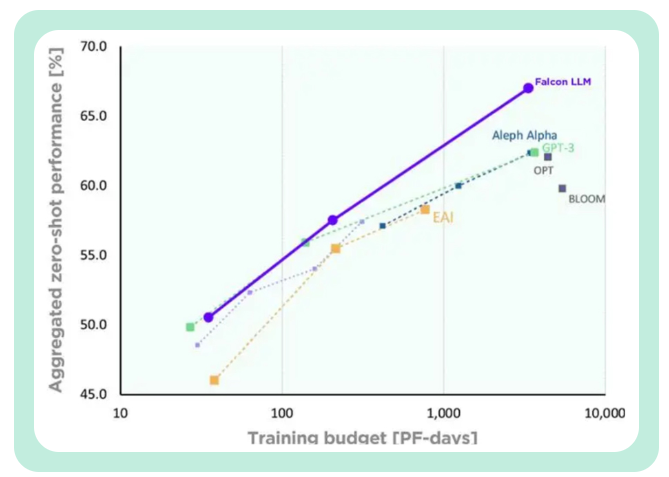
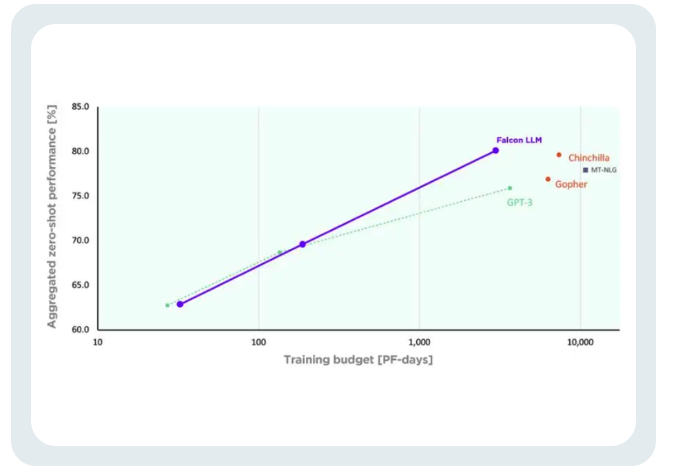
而且在推断(Inference)时只需要只需要20%的计算时间。
Falcon的训练成本,只相当于Chinchilla的40%和PaLM-62B的80% 。
成功实现了计算资源的高效利用。
以上是碾压LLaMA,「猎鹰」彻底开源!400亿参数,万亿token训练,霸榜Hugging Face的详细内容。更多信息请关注PHP中文网其他相关文章!

 如何使用LM Studio在本地运行LLM? - 分析VidhyaApr 19, 2025 am 11:38 AM
如何使用LM Studio在本地运行LLM? - 分析VidhyaApr 19, 2025 am 11:38 AM轻松在家运行大型语言模型:LM Studio 使用指南 近年来,软件和硬件的进步使得在个人电脑上运行大型语言模型 (LLM) 成为可能。LM Studio 就是一个让这一过程变得轻松便捷的优秀工具。本文将深入探讨如何使用 LM Studio 在本地运行 LLM,涵盖关键步骤、潜在挑战以及在本地拥有 LLM 的优势。无论您是技术爱好者还是对最新 AI 技术感到好奇,本指南都将提供宝贵的见解和实用技巧。让我们开始吧! 概述 了解在本地运行 LLM 的基本要求。 在您的电脑上设置 LM Studi
 盖伊·佩里(Guy Peri)通过数据转换帮助麦考密克的未来Apr 19, 2025 am 11:35 AM
盖伊·佩里(Guy Peri)通过数据转换帮助麦考密克的未来Apr 19, 2025 am 11:35 AM盖伊·佩里(Guy Peri)是麦考密克(McCormick)的首席信息和数字官。尽管他的角色仅七个月,但Peri正在迅速促进公司数字能力的全面转变。他的职业生涯专注于数据和分析信息
 迅速工程中的情感链是什么? - 分析VidhyaApr 19, 2025 am 11:33 AM
迅速工程中的情感链是什么? - 分析VidhyaApr 19, 2025 am 11:33 AM介绍 人工智能(AI)不仅要理解单词,而且要理解情感,从而以人的触感做出反应。 这种复杂的互动对于AI和自然语言处理的快速前进的领域至关重要。 Th
 12个最佳数据科学工作流程的AI工具-Analytics VidhyaApr 19, 2025 am 11:31 AM
12个最佳数据科学工作流程的AI工具-Analytics VidhyaApr 19, 2025 am 11:31 AM介绍 在当今以数据为中心的世界中,利用先进的AI技术对于寻求竞争优势和提高效率的企业至关重要。 一系列强大的工具使数据科学家,分析师和开发人员都能构建,Depl
 AV字节:OpenAI的GPT-4O Mini和其他AI创新Apr 19, 2025 am 11:30 AM
AV字节:OpenAI的GPT-4O Mini和其他AI创新Apr 19, 2025 am 11:30 AM本周的AI景观爆炸了,来自Openai,Mistral AI,Nvidia,Deepseek和Hugging Face等行业巨头的开创性发行。 这些新型号有望提高功率,负担能力和可访问性,这在TR的进步中推动了
 报告发现,困惑的Android应用程序有安全缺陷。Apr 19, 2025 am 11:24 AM
报告发现,困惑的Android应用程序有安全缺陷。Apr 19, 2025 am 11:24 AM但是,该公司的Android应用不仅提供搜索功能,而且还充当AI助手,并充满了许多安全问题,可以将其用户暴露于数据盗用,帐户收购和恶意攻击中
 每个人都擅长使用AI:关于氛围编码的想法Apr 19, 2025 am 11:17 AM
每个人都擅长使用AI:关于氛围编码的想法Apr 19, 2025 am 11:17 AM您可以查看会议和贸易展览中正在发生的事情。您可以询问工程师在做什么,或咨询首席执行官。 您看的任何地方,事情都以惊人的速度发生变化。 工程师和非工程师 有什么区别
 火箭发射模拟和分析使用Rocketpy -Analytics VidhyaApr 19, 2025 am 11:12 AM
火箭发射模拟和分析使用Rocketpy -Analytics VidhyaApr 19, 2025 am 11:12 AM模拟火箭发射的火箭发射:综合指南 本文指导您使用强大的Python库Rocketpy模拟高功率火箭发射。 我们将介绍从定义火箭组件到分析模拟的所有内容


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

Dreamweaver CS6
视觉化网页开发工具

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

SublimeText3汉化版
中文版,非常好用

