



对json数据进行查询及修改
使用 字段->'$.json属性' 进行查询条件
使用 json_extract 函数查询,json_extract(字段, "$.json属性")
根据json数组查询,用 JSON_CONTAINS(字段, JSON_OBJECT('json属性', "内容")) : [{}]查询这种形式的json数组
MySQL5.7以上支持JSON的操作,以及增加了JSON存储类型
一般数据库存储JSON类型的数据会用JSON类型或者TEXT类型
几个相关函数
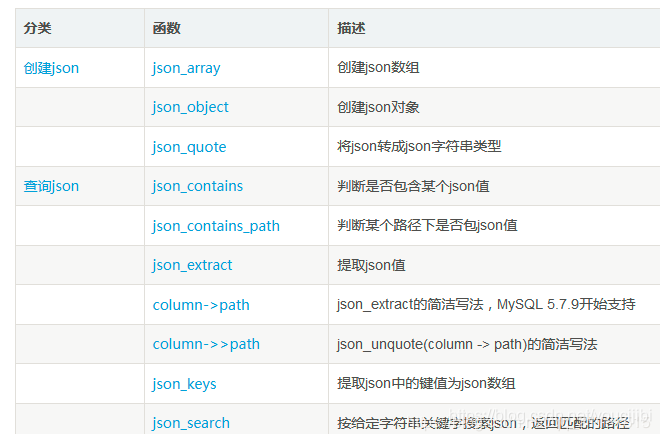
示例

我这里没有创建json的字段格式,而是使用了text存储json 。
请注意:若要使用JSON类型,则列存储的数据必须是符合JSON格式,否则会导致错误。2)JSON数据类型是没有默认值的。
插入json格式的数据到这一列中:
{"age": "28", "pwd": "lisi", "name": "李四"}查询
1、
select * from `offcn_off_main` where json_extract(json_field,"$.name") = '李四'
2、
select * from `offcn_off_main` where json_field->'$.name' = '李四'
使用explain可以查看到无法使用索引。
所以需要修改:
mysql原生并不支持json列中的属性索引,但是我们可以通过mysql的虚拟列间接的为json中的某些属性创建索引,原理就是为json中的属性创建虚拟列,然后通过给虚拟列建立索引,从而间接的给属性创建了索引。
在MySQL 5.7中,支持两种Generated Column,即Virtual Generated Column和Stored Generated Column,前者只将Generated Column保存在数据字典中(表的元数据),并不会将这一列数据持久化到磁盘上;后者会将Generated Column持久化到磁盘上,而不是每次读取的时候计算所得。很明显,后者存放了可以通过已有数据计算而得的数据,需要更多的磁盘空间,与Virtual Column相比并没有优势----(其实我觉得还是有优势毕竟会少一些查询计算)
因此,MySQL 5.7中,不指定Generated Column的类型,默认是Virtual Column。
如果需要Stored Generated Golumn的话,可能在Virtual Generated Column上建立索引更加合适,一般情况下,都使用Virtual Generated Column,这也是MySQL默认的方式。
格式如下:
fieldname <type> [ GENERATED ALWAYS ] AS ( <expression> ) [ VIRTUAL|STORED ] [ UNIQUE [KEY] ] [ [PRIMARY] KEY ] [ NOT NULL ] [ COMMENT <text> ]
所以我这里:
ALTER TABLE 'off_main' `names_virtual` VARCHAR(20) GENERATED ALWAYS AS (`json_field` ->> '$.name') not null;
请注意:可以使用"»"操作符来引用JSON字段中的键(KEY)。在本例中,虚拟字段names_virtual已被定义为不可为空。在实际的工作中,一定要集合具体的情况来定。因为JSON本身是一种弱结构的数据对象。也就是说的它的结构不是固定不变的。
给虚拟字段增加索引:
CREATE INDEX `names` ON `off_main`(`names_virtual`);
注意如果虚拟字段并不是创建表是添加的,而是后面加的,增加索引时如果有的行中虚拟字段为null,但是又设置了它不能为null,那么索引无法创建成功,提示column can not be null.
增加索引后 explain看下即可看到用到了索引,并且虚拟字段的值会随着json字段的属性修改而自动变化。
来看看修改
update off_main set json_field = json_set(json_field,'$.phone', '132') WHERE id = 45 //同时修改多个 UPDATE offcn_off_main set json_field = json_set(json_field,'$.name',456,'$.age','bbb') WHERE id = 45
json_set() 方法存在的则会覆盖,不存在的会添加。
删除
UPDATE offcn_off_main set json_field = json_remove(json_field,'$.pwd','$.phone') WHERE id = 45
插入
UPDATE offcn_off_main set json_field = json_insert(json_field,'$.pwd','111') WHERE id = 45
insert与update不同之处在于insert不存在的会增加,存在的不会覆盖
Mysql处理json数据
1.如果数据量小的话,将json数据直接复制到mysql的json字段中,如果数据过大可以通过java等后台形式对json数据解析,然后写入数据库中。
查询操作
select *,json->'$.features[0].geometry.rings' as rings from JSON;
从一张表读取一部分数据存入另一张表中(一条数据)
insert into DT_village(name, border) SELECT json->'$.features[0].attributes.CJQYMC',json->'$.features[0].geometry.rings' from JSON;
读取json数据并写入数据库(此时使用的是定义函数的形式来执行方法,可以定义便量)
#清空数据库
TRUNCATE table DT_village;
#定义存储过程
delimiter //
DROP PROCEDURE IF EXISTS insert_test_val;
##num_limit 要插入数据的数量,rand_limit 最大随机的数值
CREATE PROCEDURE insert_test_val()
BEGIN
DECLARE i int default 0;
DECLARE a,b varchar(5000);
WHILE i<10 do
set a=CONCAT('$.features[',i,'].attributes.CJQYMC');
set b=CONCAT('$.features[',i,'].geometry.rings');
insert into DT_village(name, border) select
#json->'$.features[0].attributes.CJQYMC',json->'$.features[0].geometry.rings'
# (json->a),(json->b)
json_extract(json,a),json_extract(json,b)
from JSON;
set i = i + 1;
END WHILE;
END
//
#调用存储过程
call insert_test_val();调用游标的方式获取jsosn数据中的一行,并执行插入操作
delimiter //
drop procedure if exists StatisticStore;
CREATE PROCEDURE StatisticStore()
BEGIN
#创建接收游标数据的变量
declare j json;#存储json数据
DECLARE i int default 0; #创建总数变量,记录执行次数,控制循环
DECLARE a,b,c varchar(5000);#定义json数组中的某个数据的键值
#创建结束标志变量
declare done int default false;
#创建游标
declare cur cursor for select json from JSON where name = '1';
#指定游标循环结束时的返回值
declare continue HANDLER for not found set done = true;
#设置初始值
set a=CONCAT('$.features[',i,'].attributes.XZQDM');
set b=CONCAT('$.features[',i,'].attributes.XZQMC');
set c=CONCAT('$.features[',i,']');
#打开游标
open cur;
#开始循环游标里的数据
read_loop:loop
#根据游标当前指向的一条数据
fetch cur into j;
#判断游标的循环是否结束
if done then
leave read_loop;#跳出游标循环
end if;
#这里可以做任意你想做的操作
WHILE i<11 do
insert into dt_border(xzq_code,name,border) select
json_extract(j,a),json_extract(j,b),json_extract(j,c)
from JSON;
set i = i + 1;
END WHILE;
#结束游标循环
end loop;
#关闭游标
close cur;
#输出结果
select j,i;
END;
#调用存储过程
call StatisticStore();以上是Mysql怎么对json数据进行查询及修改的详细内容。更多信息请关注PHP中文网其他相关文章!

 MySQL中的存储过程是什么?May 01, 2025 am 12:27 AM
MySQL中的存储过程是什么?May 01, 2025 am 12:27 AM存储过程是MySQL中的预编译SQL语句集合,用于提高性能和简化复杂操作。1.提高性能:首次编译后,后续调用无需重新编译。2.提高安全性:通过权限控制限制数据表访问。3.简化复杂操作:将多条SQL语句组合,简化应用层逻辑。
 查询缓存如何在MySQL中工作?May 01, 2025 am 12:26 AM
查询缓存如何在MySQL中工作?May 01, 2025 am 12:26 AMMySQL查询缓存的工作原理是通过存储SELECT查询的结果,当相同查询再次执行时,直接返回缓存结果。1)查询缓存提高数据库读取性能,通过哈希值查找缓存结果。2)配置简单,在MySQL配置文件中设置query_cache_type和query_cache_size。3)使用SQL_NO_CACHE关键字可以禁用特定查询的缓存。4)在高频更新环境中,查询缓存可能导致性能瓶颈,需通过监控和调整参数优化使用。
 与其他关系数据库相比,使用MySQL的优点是什么?May 01, 2025 am 12:18 AM
与其他关系数据库相比,使用MySQL的优点是什么?May 01, 2025 am 12:18 AMMySQL被广泛应用于各种项目中的原因包括:1.高性能与可扩展性,支持多种存储引擎;2.易于使用和维护,配置简单且工具丰富;3.丰富的生态系统,吸引大量社区和第三方工具支持;4.跨平台支持,适用于多种操作系统。
 您如何处理MySQL中的数据库升级?Apr 30, 2025 am 12:28 AM
您如何处理MySQL中的数据库升级?Apr 30, 2025 am 12:28 AMMySQL数据库升级的步骤包括:1.备份数据库,2.停止当前MySQL服务,3.安装新版本MySQL,4.启动新版本MySQL服务,5.恢复数据库。升级过程需注意兼容性问题,并可使用高级工具如PerconaToolkit进行测试和优化。
 您可以使用MySQL的不同备份策略是什么?Apr 30, 2025 am 12:28 AM
您可以使用MySQL的不同备份策略是什么?Apr 30, 2025 am 12:28 AMMySQL备份策略包括逻辑备份、物理备份、增量备份、基于复制的备份和云备份。1.逻辑备份使用mysqldump导出数据库结构和数据,适合小型数据库和版本迁移。2.物理备份通过复制数据文件,速度快且全面,但需数据库一致性。3.增量备份利用二进制日志记录变化,适用于大型数据库。4.基于复制的备份通过从服务器备份,减少对生产系统的影响。5.云备份如AmazonRDS提供自动化解决方案,但成本和控制需考虑。选择策略时应考虑数据库大小、停机容忍度、恢复时间和恢复点目标。
 什么是mySQL聚类?Apr 30, 2025 am 12:28 AM
什么是mySQL聚类?Apr 30, 2025 am 12:28 AMMySQLclusteringenhancesdatabaserobustnessandscalabilitybydistributingdataacrossmultiplenodes.ItusestheNDBenginefordatareplicationandfaulttolerance,ensuringhighavailability.Setupinvolvesconfiguringmanagement,data,andSQLnodes,withcarefulmonitoringandpe
 如何优化数据库架构设计以在MySQL中的性能?Apr 30, 2025 am 12:27 AM
如何优化数据库架构设计以在MySQL中的性能?Apr 30, 2025 am 12:27 AM在MySQL中优化数据库模式设计可通过以下步骤提升性能:1.索引优化:在常用查询列上创建索引,平衡查询和插入更新的开销。2.表结构优化:通过规范化或反规范化减少数据冗余,提高访问效率。3.数据类型选择:使用合适的数据类型,如INT替代VARCHAR,减少存储空间。4.分区和分表:对于大数据量,使用分区和分表分散数据,提升查询和维护效率。
 您如何优化MySQL性能?Apr 30, 2025 am 12:26 AM
您如何优化MySQL性能?Apr 30, 2025 am 12:26 AMtooptimizemysqlperformance,lofterTheSeSteps:1)inasemproperIndexingTospeedUpqueries,2)使用ExplaintplaintoAnalyzeandoptimizequeryPerformance,3)ActiveServerConfigurationStersLikeTlikeTlikeTlikeIkeLikeIkeIkeLikeIkeLikeIkeLikeIkeLikeNodb_buffer_pool_sizizeandmax_connections,4)


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

SublimeText3汉化版
中文版,非常好用

WebStorm Mac版
好用的JavaScript开发工具

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

