



intset
当set集合存储的是整数时,encoding为intset类型(小整数集合)
typedef struct intset {
int32 encoding;
int32 length;
int contents[];
}| 字段 | 描述 | 说明 |
|---|---|---|
| encoding | 决定整数位宽是16位、32位还是64位 | 枚举表示 |
| length | 元素个数 | |
| contents | 整数数组,存储元素值 |
intset按照从小到大的顺序保存元素。存储元素时,根据整数大小决定是否要将encoding升级,找到要插入元素的位置,如果不是最后一位,会将所在位置之后的元素后移一位,最后插入元素。如果插入的元素不为整数,存储形式将变成hash结构。
ziplist
如果在配置文件中满足以下条件,即hash和zset的编码类型会为ziplist(压缩列表)。
hash-max-ziplist-entries 512 # 当hash元素个数小于512时 hash-max-ziplist-value 64 # 当hash键或值长度小于64时 zset-max-ziplist-entries 128 # 当zset元素个数小于128时 zset-max-ziplist-value 64 # 当zset值小于64时
typedef struct ziplist {
int32 zlbytes;
int32 zltail_offset;
int16 zllength;
T[] entries;
int8 zlend;
}
typedef struct entry {
int<var> prevlen;
int<var> encoding;
byte[] content;
}| 字段 | 描述 | 说明 |
|---|---|---|
| zlbytes | ziplist所占字节数 | |
| zltail_offset | 最后一个元素距离压缩列表起始位置的偏移量 | 用于快速定位到最后一个节点,然后倒序遍历 |
| zllength | 元素个数 | |
| entries | 压缩元素 | |
| zlend | 标志压缩列表的结束 | 恒为FF |
| 字段 | 描述 | 说明 |
|---|---|---|
| prevlen | 前一个entry的字节长度 | 第一个entry恒为0,字节长度动态变化,当字符串长度小于254时,用一个字节,否则用五个字节 |
| encoding | 编码类型 | 编码类型根据元素内容动态变化,极为复杂,本篇不作详细描述,具体可搜索ziplist编码类型 |
| content | 元素内容,可选 |
下图是一个ziplist的demo
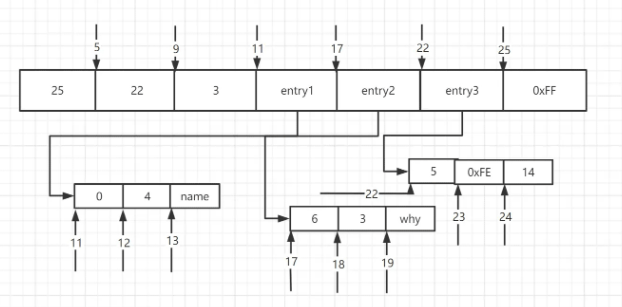
第1-4字节,zlbytes为25,说明该压缩列表共占用25个字节
第5-8字节,zltail_offset为22,说明最后一个元素从22开始
第9-10字节,zllength为3,说明共有3个元素
第11-16字节,第一个entry: 其中prevlen=0,因为它前面没有数据项;encoding=4,表示后面4byte按照字符串存储,数据的值为name
第17-21字节,第二个entry: 其中prevlen=6,表示前一个entry共占用6byte;encoding=3,表示后面3byte按照字符串存储,数据的值为why
第22-24字节,第三个entry: 其中prevlen=5,表示前一个entry共占用5byte;encoding=0xFE,表示后面1byte存储整数,数据的值为14
第25字节,zlend为FF,标志压缩列表的结束
当用ziplist存储hash结构时,将key与value分别当作一个entry存储。
可见压缩列表存储非常的紧凑,当某一个entry长度变为254时,下一个entry的prevlen将从1个字节扩展到5个字节,这就是级联更新
quicklist
quicklist(快速列表)用于存储list集合,它是ziplist与linkedlist的混合体,linkedlist与双向列表结构类似。
quicklist内部默认单个ziplist长度为8K,超过这个长度,就会另起一个node,可在配置文件中配置。
# -2表示8k,枚举类型可在配置文件中查看 list-max-ziplist-size -2
quicklist默认的压缩深度为0,也就是不压缩。如果压缩深度为1,那么就是首尾不压缩,如果压缩深度为2,那么就是首2个、尾2个不压缩,可在配置文件中配置。
list-compress-depth 0
skiplist
zset使用dict存储value与score的映射,另一方面还需要按照score提供排序功能,于是就有了skiplist(跳跃列表)
先看skiplist的一个demo
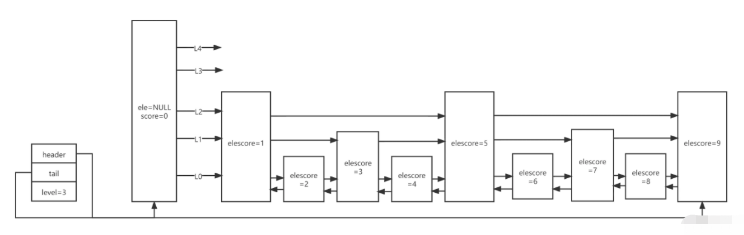
typedef struct zsl {
zslnode* header;
zslnode* tail;
int maxLevel;
}typedef struct zslnode {
sds value;
double score;
zslforward*[] forwards;
zslnode* backward;
}typedef struct zslforward {
zslnode* item;
int span;
}| 字段 | 描述 | 说明 |
|---|---|---|
| header | 指向跳跃列表的头指针 | value固定为NULL,score固定为0,backward为null |
| tail | 指向跳跃列表的尾指针 | |
| maxLevel | 当前跳跃表最大层数 | 最大为64 |
| value | 用于存储字符串类型的数据 | |
| score | 用于存储分值 | |
| backward | 回退节点 | 图中的←箭头 |
| forwards | 前进节点 | 图中的→箭头,每一层对应一个 |
| span | 跨度,存储一个节点跳到下一个节点中间跳过了多少节点 | 如score1指向score5,则span值为4,这是排名的实现原理 |
最小分值的backward固定null,对于每一个新插入的节点,会调用一个随机算法,来给它分配一个合理的层数
level1的概率为1-0.25=0.75,实际为100%,因为跳跃列表的最小层数为1
level2的概率为0.75*0.25=0.1875level3的概率为0.1875*0.25=0.0468 ......
leveln的概率为(1-0.25)*Math.pow(0.25,n-1)
总结
Redis作为单线程内存服务,在响应、数据结构上作出了很多的优化,值得我们学习
| 对象类型 | 编码类型 |
|---|---|
| string | int、raw、embstr |
| list | quicklist |
| hash | dict、ziplist |
| set | intset、dict |
| zset | ziplist、skiplist+dict |
HyperLogLog
HyperLogLog的原理为伯努利试验,即丢硬币,根据连续出现反面的次数X,推算出一共丢了2的X次方次硬币,当X很大时,推算出来的总数与实际总数误差就很接近了。具体可查询其他文章。
pfadd
element经过hash算法之后是一个64位的固定值
低14位为桶
查找高50位第一个为1的位数,如果大于当前桶的位数,就将其设置为当前桶的位数
假设hash值是 :{此处省略45位}01100 00000000000101
低14位的二进制转为10进制,值为5(regnum),即我们把数据放在第5个桶
高50位第一个1的位置是3,即count值为3
registers[5]取出历史值oldcount
如果count > oldcount,则更新 registers[5] = count
如果count <= oldcount,则不做任何处理
HyperLogLog用了16384个桶,每个桶占用6bit,因此说一个HyperLogLog所占用内存是12K。
调和平均数:
假设我的工资为10_000,马云的工资为1_000_000,那我和马云的平均工资为505_000,我肯定是不认同的。。。
如果使用调和平均数,则为2/(1/10_000+1/1_000_000)=19_801
同理,桶位数的平均数为:n/(1/桶1位数+1/桶2位数+...+1/桶n位数)
桶的平均个数为:Math.pow(2,桶位数的平均数)
总数量:const*桶总数n*桶的平均个数,其中constant为不定值,与桶个数有关,假设m为桶个数,取对数
pfcount
p=log2m
switch (p) {
case 4:
constant = 0.673 * m * m;
case 5:
constant = 0.697 * m * m;
case 6:
constant = 0.709 * m * m;
default:
constant = (0.7213 / (1 + 1.079 / m)) * m * m;
}以上是Redis数据结构类型实例代码分析的详细内容。更多信息请关注PHP中文网其他相关文章!

 REDIS与其他数据库:比较分析Apr 23, 2025 am 12:16 AM
REDIS与其他数据库:比较分析Apr 23, 2025 am 12:16 AMRedis与其他数据库相比,具有以下独特优势:1)速度极快,读写操作通常在微秒级别;2)支持丰富的数据结构和操作;3)灵活的使用场景,如缓存、计数器和发布订阅。选择Redis还是其他数据库需根据具体需求和场景,Redis在高性能、低延迟应用中表现出色。
 REDIS的角色:探索数据存储和管理功能Apr 22, 2025 am 12:10 AM
REDIS的角色:探索数据存储和管理功能Apr 22, 2025 am 12:10 AMRedis在数据存储和管理中扮演着关键角色,通过其多种数据结构和持久化机制成为现代应用的核心。1)Redis支持字符串、列表、集合、有序集合和哈希表等数据结构,适用于缓存和复杂业务逻辑。2)通过RDB和AOF两种持久化方式,Redis确保数据的可靠存储和快速恢复。
 REDIS:了解NOSQL概念Apr 21, 2025 am 12:04 AM
REDIS:了解NOSQL概念Apr 21, 2025 am 12:04 AMRedis是一种NoSQL数据库,适用于大规模数据的高效存储和访问。1.Redis是开源的内存数据结构存储系统,支持多种数据结构。2.它提供极快的读写速度,适合缓存、会话管理等。3.Redis支持持久化,通过RDB和AOF方式确保数据安全。4.使用示例包括基本的键值对操作和高级的集合去重功能。5.常见错误包括连接问题、数据类型不匹配和内存溢出,需注意调试。6.性能优化建议包括选择合适的数据结构和设置内存淘汰策略。
 REDIS:现实世界的用例和示例Apr 20, 2025 am 12:06 AM
REDIS:现实世界的用例和示例Apr 20, 2025 am 12:06 AMRedis在现实世界中的应用包括:1.作为缓存系统加速数据库查询,2.存储Web应用的会话数据,3.实现实时排行榜,4.作为消息队列简化消息传递。Redis的多功能性和高性能使其在这些场景中大放异彩。
 REDIS:探索其功能和功能Apr 19, 2025 am 12:04 AM
REDIS:探索其功能和功能Apr 19, 2025 am 12:04 AMRedis脱颖而出是因为其高速、多功能性和丰富的数据结构。1)Redis支持字符串、列表、集合、散列和有序集合等数据结构。2)它通过内存存储数据,支持RDB和AOF持久化。3)从Redis6.0开始引入多线程处理I/O操作,提升了高并发场景下的性能。
 Redis是SQL还是NOSQL数据库?答案解释了Apr 18, 2025 am 12:11 AM
Redis是SQL还是NOSQL数据库?答案解释了Apr 18, 2025 am 12:11 AMRedisisclassifiedasaNoSQLdatabasebecauseitusesakey-valuedatamodelinsteadofthetraditionalrelationaldatabasemodel.Itoffersspeedandflexibility,makingitidealforreal-timeapplicationsandcaching,butitmaynotbesuitableforscenariosrequiringstrictdataintegrityo
 REDIS:提高应用程序性能和可扩展性Apr 17, 2025 am 12:16 AM
REDIS:提高应用程序性能和可扩展性Apr 17, 2025 am 12:16 AMRedis通过缓存数据、实现分布式锁和数据持久化来提升应用性能和可扩展性。1)缓存数据:使用Redis缓存频繁访问的数据,提高数据访问速度。2)分布式锁:利用Redis实现分布式锁,确保在分布式环境中操作的安全性。3)数据持久化:通过RDB和AOF机制保证数据安全性,防止数据丢失。
 REDIS:探索其数据模型和结构Apr 16, 2025 am 12:09 AM
REDIS:探索其数据模型和结构Apr 16, 2025 am 12:09 AMRedis的数据模型和结构包括五种主要类型:1.字符串(String):用于存储文本或二进制数据,支持原子操作。2.列表(List):有序元素集合,适合队列和堆栈。3.集合(Set):无序唯一元素集合,支持集合运算。4.有序集合(SortedSet):带分数的唯一元素集合,适用于排行榜。5.哈希表(Hash):键值对集合,适合存储对象。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

SublimeText3汉化版
中文版,非常好用

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

