



内存维度
控制key的长度
key的一般都是采用字符串,而字符串的底层数据结构为SDS,SDS 结构中会包含字符串长度、分配空间大小等元数据信息,当key字符串的长度增加时,SDS中的元数据也会占用更多内存空间,为了减少key的占用空间,我们可用根据业务名来使用相应的英文缩写来表示。例如user用u表示,message 用m来表示。
避免存储bigkey
我们既要注意key的长度,同时也需要关注value的大小,Redis是使用单线程读写数据,bigkey 的读写操作会阻塞线程,降低Redis的处理效率。
如何查询bigkey
我们可以通过--bigkey的命令来查看Redis中所占用的bigkey的信息,具体的命令如下:
redis-cli -h 127.0.0.1 -p 6379 -a 'xxx' --bigkeys
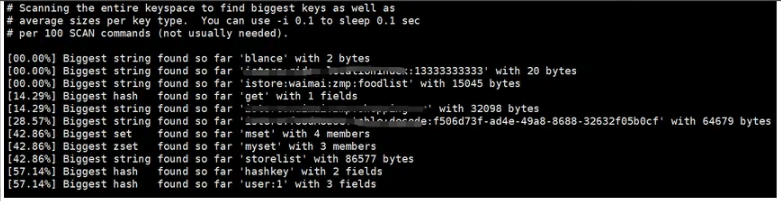
从上述图所示,我们可以查看到Redis中的key占用了32098个bytes,需要进行相关优化的。
建议:
如果key为string类型,建议value的存放值的大小为10KB左右。
如果key为List/Hash/Set/ZSet类型,建议存放元素的的数量控制在1万以下。
选择合适的数据类型
Redis针对所存储的数据类型进行了优化,同时也对内存进行了相应的优化。关乎数据结果的相关知识,可以参考之前的文章。
例如:String和set在存储int数据时,会采用整数编码存储。Hash、ZSet在元素数量比较少时,会采用压缩列表(ziplist)存储,在存储比较多的数据时,才会转换为哈希表和跳表。
采用高效的序列化和压缩方法
Redis中的字符串都是使用二进制安全的字节数组来保存的,所以我们可以把业务的序列化成二进制写入Redis,但是采用不同的序列化,所占用的空间大少不一样。Protostuff的序列化比Java内置的序列化更有效率,且占用的空间更少。为了减少空间占用,我们可以对JSON和XML数据格式进行压缩存储,可选的压缩算法包括Gzip和Snappy。
设置Redis最大内存和淘汰策略
我们根据业务的数据量提前预估内存大小,从而避免Redis的内存持续膨胀,导致占用过多资源。
关于如何设置淘汰策略,需要集合实际的业务特性来选择:
volatile-lru / allkeys-lru:优先保留最近访问过的数据
volatile-lfu / allkeys-lfu:优先保留访问次数最频繁的数据
volatile-ttl :优先淘汰即将过期的数据
volatile-random / allkeys-random:随机淘汰数据
控制Redis实例的大小
Redis单实例的内存大小建议设置在2~6GB之间。由于RDB快照和主从集群数据同步都能快速完成,不会阻塞正常请求的处理。
定时清除内存碎片
频繁的新增修改会导致内存碎片的增多,因此需要及时清理内存碎片。
Redis提供了Info memory命令可以查看内存使用信息,具体如下:
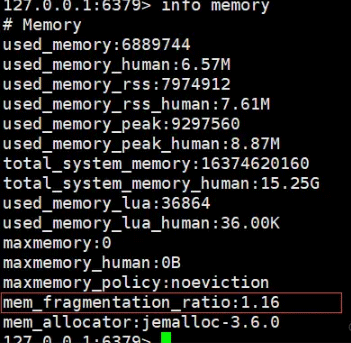
说明:
used_memory_rss是操作系统实际分配给 Redis的物理内存空间。
used_memory 是 Redis 为了保存数据实际申请使用的空间。
mem_fragmentation_ratio=used_memory_rss/ used_memory
mem_fragmentation_ratio 大于1但小于1.5。这种情况是合理的。
如果mem_fragmentation_ratio大于1.5,意味着内存碎片率已经达到50%以上。在这种情况下,通常需要采取一些措施来减少内存碎片率。具体的内存清理措施,将在后续的文章中进行讲解。
性能维度
禁止使用KEYS、FLUSHALL、FLUSHDB命令
KEYS 按照key内容进行匹配,返回符合匹配条件的键值对,该命令需要对Redis的全局哈希表进行全表扫描,严重阻塞 Redis主线程。
FLUSHALL 删除Redis实例上的所有数据,如果数据量很大,会严重阻塞Redis主线程。
FLUSHDB,删除当前数据库中的数据,如果数据量很大,会阻塞Redis主线程。
优化建议
我们需要在线上要禁用这些命令。具体的做法是,管理员采用rename-command命令在配置文件中对这些命令进行重命名,让客户端无法使用这些命令。
慎用全量操作的命令
对于集合类型的来说,在未清楚集合数据大小的情况下,慎用查询集合中的全量数据,例如Hash的HetALL、Set的SMEMBERS命令、LRANGE key 0 -1 或者ZRANGE key 0 -1等命令,因为这些命令会对Hash或者Set类型的底层数据进行全量扫描,当集合数据量比较大时,会阻塞Redis的主线程。
优化建议:
当元素数据量较多时,可以用SSCAN、HSCAN 命令分批返回集合中的数据,减少对主线程的阻塞。
慎用复杂度过高命令
Redis执行复杂度过高的命令,会消耗更多的 CPU 资源,导致主线程中的其它请求只能等待。常见的复杂命令如下:SORT、SINTER、SINTERSTORE、ZUNIONSTORE、ZINTERSTORE 等聚合类命令。
优化建议:
当需要执行排序、交集、并集操作时,可以在客户端完成,避免让Redis进行过多计算,从而影响Redis性能。
设置合适的过期时间
Redis通常用于保存热数据。热数据一般都有使用的时效性。因此,在数据存储的过程中,应根据业务对数据的使用时间合理地设置数据的过期时间。否则写入Redis的数据会一直占用内存,如果数据持续增增长,会达到机器的内存上限,造成内存溢出,导致服务崩溃。
采用批量命令代替个命令
当我们需要一次性操作多个key时,可以使用批量命令来处理,批量命令可以减少客户端与服务端的来回网络IO次数。
String或者Hash类型可以使用 MGET/MSET替代 GET/SET,HMGET/HMSET替代HGET/HSET
其它数据类型使用Pipeline命令,一次性打包发送多个命令到服务端执行。
Pipeline具体使用:
redisTemplate.executePipelined(new RedisCallback<String>() {
@Override
public String doInRedis(RedisConnection connection) throws DataAccessException {
for (int i = 0; i < 5; i++)
{
connection.set(("test:" + i).getBytes(), "test".getBytes());
}
return null;
}
});高可用维度
按照业务部署不同的实例
不同的业务线来部署 Redis 实例,这样当其中一个实例发生故障时,不会影响到其它业务。
避免单点问题
业务上根据实际情况采用主从、哨兵、集群方案,避免单点故障,影响业务的正常使用。
合理的设置相关参数
针对主从环境,我们需要合理设置相关参数,具体内容如下:
合理的设置repl-backlog参数:如果repl-backlog设置过小,当写流量比较大的场景下,主从复制中断可能会引发全量复制数据的风险。
合理设置slave client-output-buffer-limit:当从库复制发生问题时,过小的 buffer会导致从库缓冲区溢出,从而导致复制中断。
以上是Redis优化实例分析的详细内容。更多信息请关注PHP中文网其他相关文章!

 REDIS:超越SQL- NOSQL的观点May 08, 2025 am 12:25 AM
REDIS:超越SQL- NOSQL的观点May 08, 2025 am 12:25 AMRedis超越SQL数据库的原因在于其高性能和灵活性。1)Redis通过内存存储实现极快的读写速度。2)它支持多种数据结构,如列表和集合,适用于复杂数据处理。3)单线程模型简化开发,但高并发时可能成瓶颈。
 REDIS:与传统数据库服务器的比较May 07, 2025 am 12:09 AM
REDIS:与传统数据库服务器的比较May 07, 2025 am 12:09 AMRedis在高并发和低延迟场景下优于传统数据库,但不适合复杂查询和事务处理。1.Redis使用内存存储,读写速度快,适合高并发和低延迟需求。2.传统数据库基于磁盘,支持复杂查询和事务处理,数据一致性和持久性强。3.Redis适用于作为传统数据库的补充或替代,但需根据具体业务需求选择。
 REDIS:功能强大的内存数据存储的简介May 06, 2025 am 12:08 AM
REDIS:功能强大的内存数据存储的简介May 06, 2025 am 12:08 AMRedisisahigh-performancein-memorydatastructurestorethatexcelsinspeedandversatility.1)Itsupportsvariousdatastructureslikestrings,lists,andsets.2)Redisisanin-memorydatabasewithpersistenceoptions,ensuringfastperformanceanddatasafety.3)Itoffersatomicoper
 Redis主要是数据库吗?May 05, 2025 am 12:07 AM
Redis主要是数据库吗?May 05, 2025 am 12:07 AMRedis主要是一个数据库,但它不仅仅是数据库。1.作为数据库,Redis支持持久化,适合高性能需求。2.作为缓存,Redis提升应用响应速度。3.作为消息代理,Redis支持发布-订阅模式,适用于实时通信。
 REDIS:数据库,服务器还是其他?May 04, 2025 am 12:08 AM
REDIS:数据库,服务器还是其他?May 04, 2025 am 12:08 AMredisisamultifaceTedToolThatServesAsAdatabase,server和more.itfunctionsasanin-memorydatastrustore,supportsvariousDataStructures,and CanbeusedAsacache,MessageBroker,sessionStorage,sessionStorage,sessionstorage,andford forderibedibedlocking。
 REDIS:揭示其目的和关键应用程序May 03, 2025 am 12:11 AM
REDIS:揭示其目的和关键应用程序May 03, 2025 am 12:11 AMRedisisanopen-Source,内存内部的库雷斯塔氏菌,卡赫和梅斯吉级,excellingInsPeedAndVersatory.itiswidelysusedforcaching,Real-Timeanalytics,Session Management,Session Managements,and sessighterboarderboarderboardobboardotoitsssupportfortfortfortfortfortfortfortfortorvortfortfortfortfortfortforvortfortforvortforvortforvortfortforvortforvortforvortforvortdatastherctuct anddatataCcessandcessanddataaCces
 REDIS:键值数据存储的指南May 02, 2025 am 12:10 AM
REDIS:键值数据存储的指南May 02, 2025 am 12:10 AMRedis是一个开源的内存数据结构存储,用作数据库、缓存和消息代理,适合需要快速响应和高并发的场景。1.Redis使用内存存储数据,提供微秒级的读写速度。2.它支持多种数据结构,如字符串、列表、集合等。3.Redis通过RDB和AOF机制实现数据持久化。4.使用单线程模型和多路复用技术高效处理请求。5.性能优化策略包括LRU算法和集群模式。
 REDIS:缓存,会话管理等May 01, 2025 am 12:03 AM
REDIS:缓存,会话管理等May 01, 2025 am 12:03 AMRedis的功能主要包括缓存、会话管理和其他功能:1)缓存功能通过内存存储数据,提高读取速度,适用于电商网站等高频访问场景;2)会话管理功能在分布式系统中共享会话数据,并通过过期时间机制自动清理;3)其他功能如发布-订阅模式、分布式锁和计数器,适用于实时消息推送和多线程系统等场景。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

SublimeText3 Linux新版
SublimeText3 Linux最新版

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

