


Redis是一种基于键值对(Key-Value)的NoSQL数据库,Redis的Value可以由String,hash,list,set,zset,Bitmaps,HyperLogLog等多种数据结构和算法组成。Redis具备多项功能,如键过期、发布订阅、事务、Lua脚本、哨兵、Cluster等。
根据官方提供的性能数据,Redis能够以非常快的速度执行命令,其QPS可以达到10万以上。那么本文主要介绍到底Redis快在哪里,主要有以下几点:
一、开发语言
现在我们都用高级语言来编程,比如Java、python等。也许你会觉得C语言很古老,但是它真的很有用,毕竟unix系统就是用C实现的,所以C语言是非常贴近操作系统的语言。Redis就是用C语言开发的,所以执行会比较快。
再补充一点,学生们应该专注于学习C语言,因为它有助于更好地理解计算机操作系统。别觉得学了高级语言就可以不用关注底层,欠的债总归要还的。此处推荐一本比较难啃的书《深入理解计算系统》。
二、纯内存访问
Redis使用内存存储所有数据,因此在正常运行过程中不需要从磁盘读取数据来进行非数据同步,因此IO次数为0。内存响应时间大约为100纳秒,这是Redis速度快的重要基础。先看看CPU的速度:
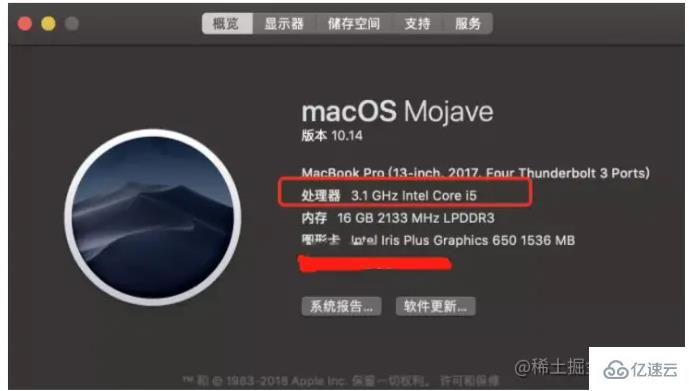
以我的电脑为例,它的主频是3.1G,意味着它可以每秒执行31亿条指令。CPU的世界观处理速度非常缓慢,相比之下,内存较其慢100倍,磁盘更慢1000000倍,你认为这算快吗?
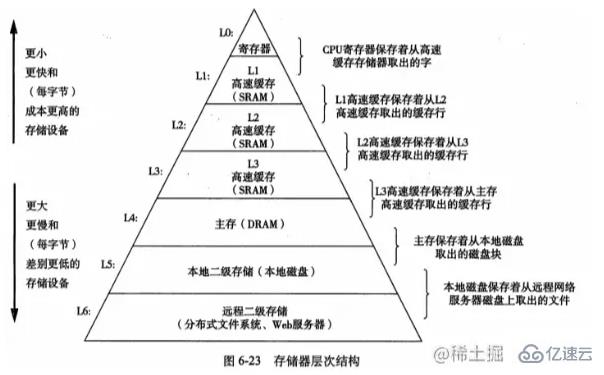
借了一张《深入理解计算机系统》的图,展示了一个典型的存储器层次结构,在L0层,CPU可以在一个时钟周期访问到,基于SRAM的高速缓存春续期,可以在几个CPU时钟周期访问到,然后是基于DRAM的主存,可以在几十到几百个时钟周期访问到他们。
三、单线程
单线程可以简化算法的实现,但是实现并发的数据结构不仅困难而且测试也很麻烦。在服务端开发中,锁和线程切换通常是性能杀手,使用单线程可以避免它们带来的消耗。当然了,单线程也会有它的缺点,也是Redis的噩梦:阻塞。如果执行一个命令过长,那么会造成其他命令的阻塞,对于Redis是十分致命的,所以Redis是面向快速执行场景的数据库。
除了Redis之外,Node.js也是单线程,Nginx也是单线程,但他们都是服务器高性能的典范。
四、非阻塞多路I/O复用机制
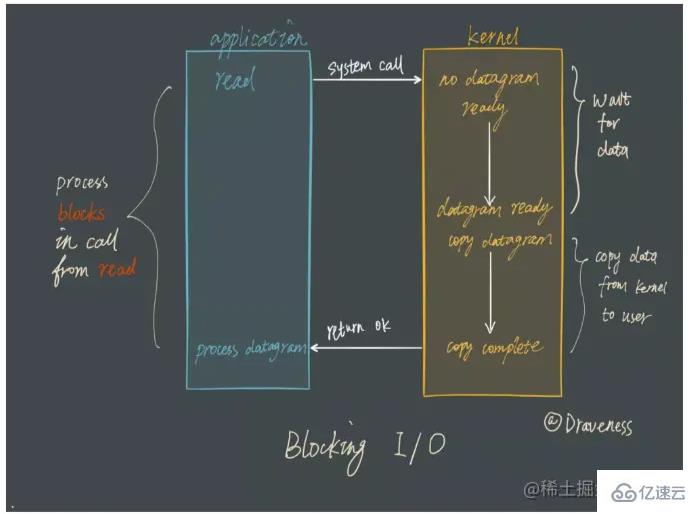
在这之前先要说一下传统的阻塞I/O是如何工作的:当使用read或者write对某一文件描述符(File Descriptor FD)进行读写的时候,如果数据没有收到,那么该线程会被挂起,直到收到数据。
阻塞模型虽然易于理解,但是在需要处理多个客户端任务的时候,不会使用阻塞模型。
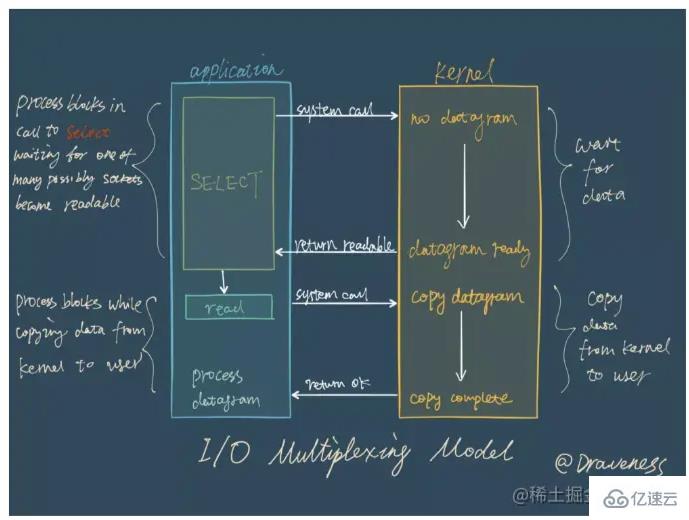
I/O多路复用实际上是指多个连接的管理可以在同一进程。多路是指网络连接,复用只是同一个线程。在网络服务中,I/O多路复用起的作用是一次性把多个连接的事件通知业务代码处理,处理的方式由业务代码来决定。
在I/O多路复用模型中,最重要的函数调用就是I/O 多路复用函数,该方法能同时监控多个文件描述符(fd)的读写情况,当其中的某些fd可读/写时,该方法就会返回可读/写的fd个数。
Redis使用epoll作为I/O多路复用技术的实现,再加上Redis自身的事件处理模型将epoll的read、write、close等都转换成事件,不在网络I/O上浪费过多的时间。实现对多个FD读写的监控,提高性能。
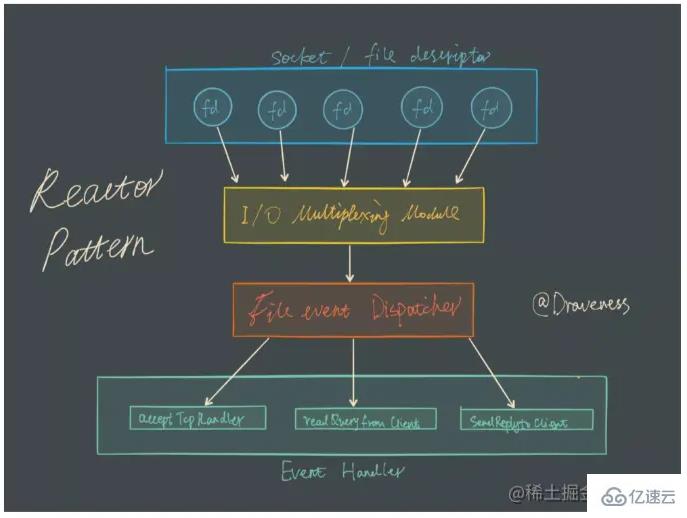
举个形象的例子吧。比如一个tcp服务器处理20个客户端socket。
A方案:顺序处理,如果第一个socket因为网卡读数据处理慢了,一阻塞后面都玩蛋去。
B方案:每个socket请求都创建一个分身子进程来处理,不说每个进程消耗大量系统资源,光是进程切换就够操作系统累的了。
C方案(I/O复用模型,epoll):将用户socket对应的fd注册进epoll(实际上服务器和操作系统之间传递的不是socket的fd而是fd_set的数据结构),然后epoll只告诉哪些需要读/写的socket,只需要处理那些活跃的、有变化的socket fd的就好了。
这样,整个过程只在调用epoll的时候才会阻塞,收发客户消息是不会阻塞的。
以上是Redis速度为什么快的详细内容。更多信息请关注PHP中文网其他相关文章!

 REDIS:对其数据库方法进行分类Apr 15, 2025 am 12:06 AM
REDIS:对其数据库方法进行分类Apr 15, 2025 am 12:06 AMRedis的数据库方法包括内存数据库和键值存储。1)Redis将数据存储在内存中,读写速度快。2)它使用键值对存储数据,支持复杂数据结构,如列表、集合、哈希表和有序集合,适用于缓存和NoSQL数据库。
 为什么要使用redis?利益和优势Apr 14, 2025 am 12:07 AM
为什么要使用redis?利益和优势Apr 14, 2025 am 12:07 AMRedis是一个强大的数据库解决方案,因为它提供了极速性能、丰富的数据结构、高可用性和扩展性、持久化能力以及广泛的生态系统支持。1)极速性能:Redis的数据存储在内存中,读写速度极快,适合高并发和低延迟应用。2)丰富的数据结构:支持多种数据类型,如列表、集合等,适用于多种场景。3)高可用性和扩展性:支持主从复制和集群模式,实现高可用性和水平扩展。4)持久化和数据安全:通过RDB和AOF两种方式实现数据持久化,确保数据的完整性和可靠性。5)广泛的生态系统和社区支持:拥有庞大的生态系统和活跃社区,
 了解NOSQL:Redis的关键特征Apr 13, 2025 am 12:17 AM
了解NOSQL:Redis的关键特征Apr 13, 2025 am 12:17 AMRedis的关键特性包括速度、灵活性和丰富的数据结构支持。1)速度:Redis作为内存数据库,读写操作几乎瞬时,适用于缓存和会话管理。2)灵活性:支持多种数据结构,如字符串、列表、集合等,适用于复杂数据处理。3)数据结构支持:提供字符串、列表、集合、哈希表等,适合不同业务需求。
 REDIS:确定其主要功能Apr 12, 2025 am 12:01 AM
REDIS:确定其主要功能Apr 12, 2025 am 12:01 AMRedis的核心功能是高性能的内存数据存储和处理系统。1)高速数据访问:Redis将数据存储在内存中,提供微秒级别的读写速度。2)丰富的数据结构:支持字符串、列表、集合等,适应多种应用场景。3)持久化:通过RDB和AOF方式将数据持久化到磁盘。4)发布订阅:可用于消息队列或实时通信系统。
 REDIS:流行数据结构指南Apr 11, 2025 am 12:04 AM
REDIS:流行数据结构指南Apr 11, 2025 am 12:04 AMRedis支持多种数据结构,具体包括:1.字符串(String),适合存储单一值数据;2.列表(List),适用于队列和栈;3.集合(Set),用于存储不重复数据;4.有序集合(SortedSet),适用于排行榜和优先级队列;5.哈希表(Hash),适合存储对象或结构化数据。
 redis计数器怎么实现Apr 10, 2025 pm 10:21 PM
redis计数器怎么实现Apr 10, 2025 pm 10:21 PMRedis计数器是一种使用Redis键值对存储来实现计数操作的机制,包含以下步骤:创建计数器键、增加计数、减少计数、重置计数和获取计数。Redis计数器的优势包括速度快、高并发、持久性和简单易用。它可用于用户访问计数、实时指标跟踪、游戏分数和排名以及订单处理计数等场景。
 redis命令行怎么用Apr 10, 2025 pm 10:18 PM
redis命令行怎么用Apr 10, 2025 pm 10:18 PM使用 Redis 命令行工具 (redis-cli) 可通过以下步骤管理和操作 Redis:连接到服务器,指定地址和端口。使用命令名称和参数向服务器发送命令。使用 HELP 命令查看特定命令的帮助信息。使用 QUIT 命令退出命令行工具。
 redis集群模式怎么搭建Apr 10, 2025 pm 10:15 PM
redis集群模式怎么搭建Apr 10, 2025 pm 10:15 PMRedis集群模式通过分片将Redis实例部署到多个服务器,提高可扩展性和可用性。搭建步骤如下:创建奇数个Redis实例,端口不同;创建3个sentinel实例,监控Redis实例并进行故障转移;配置sentinel配置文件,添加监控Redis实例信息和故障转移设置;配置Redis实例配置文件,启用集群模式并指定集群信息文件路径;创建nodes.conf文件,包含各Redis实例的信息;启动集群,执行create命令创建集群并指定副本数量;登录集群执行CLUSTER INFO命令验证集群状态;使


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

Atom编辑器mac版下载
最流行的的开源编辑器

Dreamweaver CS6
视觉化网页开发工具

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

