



Redis使用中不规范的现象
Redis 存储的key命名不规范,比较随意;
Redis 被当成存储库使用,存在数据丢失风险,且无重新加载方案;
Redis 缓存key,未设置过期时间, 缓存低频数据占用大量内存, 进而导致服务崩溃;
Redis 缓存大量big key, 应用获取时会占用大量网络带宽,删除也容易造成阻塞;
Redis 客户端使用不当,导致其它客户端连接timeout, 原因可能客户端密码错误,且没有使用连接池,大量连接重试导致系统端口资源耗光;
Redis 客户端命令使用不当,导致大量的慢查询,影响其它应用业务,比如在业务高峰期时使用 keys* 或flushall 这样的命令;
Redis 使用业务场景推荐与建议
高并发场景:热点数据缓存, 可提升系统整体响应速度,降低数据库IO压力 ;
限时场景:利用Redis expire命令设置session过期和续期、手机验证码等;
使用Redis的列表和有序集合数据结构可以实现多种复杂的排行榜应用
数据集合操作:利用Redis list、set、sorted set, 方便进行数据计算, 如交集、并集、差集等;
连续签到:可以利用redis的bitmap数据结构实现签到相关的业务;
计数器:利用Redis incr、incrby命令实现api调用次数统计, api限流等场景;
分布式锁:利用 Redis 的 setnx 功能来编写分布式的锁, 典型开源组件比如redisson;
如何设计出优雅的key
可以这么说,线上关于redis的性能优化这个问题上,不合理的key的设计经常是引发问题的根因,究其本质,就个人看到的情况来说,大多数同学在对redis使用过程中,对于key的设计几乎是没有什么概念的,因为大多数同学使用的场景就是 key/val ,对应的数据结构就是 字符串key/字符串val;
稍微对redis有更深入的了解的同学,在进行存储时,可能会知道 key的设计尽量短一点,中间最好有层次感,最好以 : 进行分割 ......
那么如何才能设计出比较优雅的key呢?下面结合小编实际使用中的经验以及踩过的坑,来具体谈谈;
一、遵循如下几个最佳实践约定
遵循基本格式:[业务名称]:[数据名]:[id];
key的长度不超过44字节;
不要包含特殊字符;
关于上面几条建议,这样做有如下几点好处:
可读性强,比如当我们设计这样的key结构, order:user:10,一眼看过去就知道这是关于用户订单相关的key;
方便维护管理,不同的应用,或者不同的业务采用不同的前缀,在可视化客户端工具或者命令行中很方便进行key的查找定位;
避免key冲突,避免在使用过程中多个人都用userId这样的值作为key引发的缓存key冲突;
使用string类型作为key,底层编码包含int、embstr和raw三种,可以有效降低内存占用。使用embstr可在内存占用更小的情况下,处理小于44字节的字符串,因为它采用了连续内存空间
推荐值:
单个key的value小于10KB;
对于集合类型的key,建议元素数量小于1000;
二、尽量避免bigkey
1、什么是bigkey呢
BigKey通常以Key的大小和Key中成员的数量来综合判定,例如:
Key本身的数据量过大:一个String类型的Key,它的值为5 MB;
Key中的成员数过多:一个ZSET类型的Key,它的成员数量为10,000个;
Key中成员的数据量过大:一个Hash类型的Key,它的成员数量虽然只有1,000个但这些成员的Value(值)总大小为100 MB;
2、BigKey的危害
网络阻塞
对BigKey执行读请求时,少量的QPS就可能导致带宽使用率被占满,导致Redis实例,乃至所在物理机变慢;
数据倾斜
BigKey所在的Redis实例内存使用率远超其他实例,无法使数据分片的内存资源达到均衡;
Redis阻塞
对元素较多的hash、list、zset等做运算会耗时较旧,使主线程被阻塞;
CPU压力
对BigKey的数据序列化和反序列化会导致CPU的使用率飙升,影响Redis实例和本机其它应用;
3、如何发现BigKey
在安装的机器上执行 redis-cli --bigkeys命令
利用redis-cli提供的--bigkeys参数,可以遍历分析所有key,并返回Key的整体统计信息与每个数据的Top1的big key;
通过scan扫描
编写程序,利用scan扫描Redis中的所有key,利用strlen、hlen等命令判断key的长度(此处不建议使用MEMORY USAGE);
使用第三方工具
利用第三方工具,如 Redis-Rdb-Tools 分析RDB快照文件,全面分析内存使用情况;
使用网络监控
自定义工具,监控进出Redis的网络数据,超出预警值时主动告警;
三、使用恰当的数据类型
正如上面所说,很多初次使用redis的同学,对于很多业务场景,都是一个key/val的简单的结构搞定,而不会深入思考这样做是否合理,或者说这样做以后会不会引发相关的性能方面的问题;
对于这个问题,从根本上来说,需要深入了解并掌握redis的常用的数据类型,在这个基础上,才能针对不同的业务场景,设计出高效的存储存储结构数据;
让我们思考一下,如何缓存用户对象列表这样的数据呢?
方案1:key为usrId,value为对象的序列化字符串,数据结构类似下面这样;

优点:存取方便,简单粗暴,存取时只需要做下json和对象的互转即可;
缺点:数据耦合,不够灵活,一旦对象新增了字段或删减了字段,缓存重建的成本非常大;
方案2:使用一个list结构,缓存用户ID列表,数据结构如下;
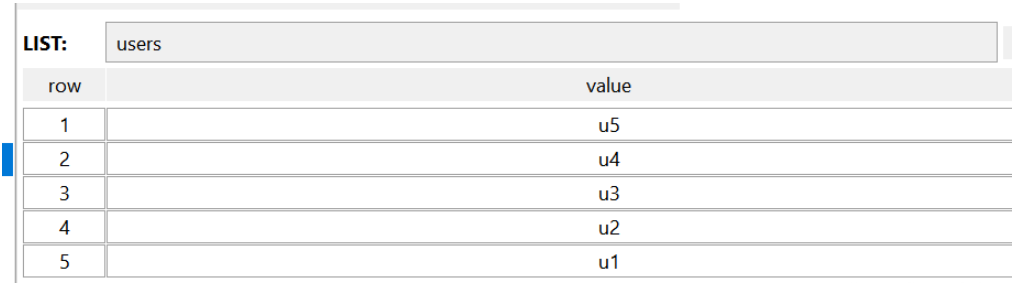
优点:对内存的占用小,操作高效;
缺点:获取到val之后,需要进一步查库才能得到完整的对象;
方案3:使用hash结构,缓存对象,数据如下所示;

优点:底层使用ziplist,空间占用小,可以灵活访问对象的任意字段;
缺点:编码上相对复杂;
Redis 缓存在实际应用中的使用建议
【推荐】对缓存进行预热。在访问数据前,应先对缓存进行预热,避免大量请求直接进入数据存储层;应根据业务情况划分合适的冷热数据,对热点数据进行预热。如许可授权信息, apikey等;
【推荐】配合使用本地缓存。在分布式架构中,虽然本地缓存可以提高数据访问的稳定性和速度,但需要谨慎使用以避免引入带状态的服务器节点。避免本地缓存过度占用应用服务器资源,导致应用节点崩溃
【推荐】缓存变更策略,应先更新数据库,再更新缓存;
【推荐】一次业务调用需要访问多次redis服务端,可采用pipleline或其它批量操作方式;
【推荐】大List,Set,Hash,存储的数量巨大。当获取大量元素时会产生较大的延迟,从而阻塞其他命令的执行。建议将其拆分成多个小的列表、集合或哈希表
使用业务规范
不管是redis,还是其他开发中使用到的中间件,具体到开发使用时,最好都应该提前制定出一套合理的规范,这个规范应该是大多数开发人员认可并在实践中得到检验,且能有效规避一些问题的,一旦指定为规范,应该成为指导内部开发人员日常的规则,这里提如下几点:
Redis 应该定位为缓存数据, 不可用于存储大规模数据(不可替代数据库);
Redis 适合读多写少场景,如存在高频写入,低频查询场景,则不推荐使用;
在不确定key的存活时间时,最好设置过期时间,控制 key 的生命周期;
应该考虑冷热数据分离,对于查询, 高频次业务查询走Redis,低频查询考虑走数据库;
程序处理数据时,应该考虑Redis存在数据丢失的风险,因此需要实现从数据库自动加载并缓存丢失的数据到Redis
谨慎使用O(N)命令, 如list, set, hash 数据结构操作时, hgetall、lrange、smembers、zrange等并非不能使用,优先考虑使用 hscan、sscan、zscan 代替。
以上是Redis键值设计使用的方法是什么的详细内容。更多信息请关注PHP中文网其他相关文章!

 REDIS:它如何充当数据存储和服务Apr 24, 2025 am 12:08 AM
REDIS:它如何充当数据存储和服务Apr 24, 2025 am 12:08 AMREDISACTSASBOTHADATASTOREANDASERVICE.1)ASADATASTORE,ITUSESIN-MEMORYSTOOGATOFORFOFFASTESITION,支持VariousDatharptructuresLikeKey-valuepairsandsortedsetsetsetsetsetsetsets.2)asaservice,ItprovidespunctionslikeItionitionslikepunikeLikePublikePublikePlikePlikePlikeAndluikeAndluAascriptingiationsmpleplepleclexplectiations
 REDIS与其他数据库:比较分析Apr 23, 2025 am 12:16 AM
REDIS与其他数据库:比较分析Apr 23, 2025 am 12:16 AMRedis与其他数据库相比,具有以下独特优势:1)速度极快,读写操作通常在微秒级别;2)支持丰富的数据结构和操作;3)灵活的使用场景,如缓存、计数器和发布订阅。选择Redis还是其他数据库需根据具体需求和场景,Redis在高性能、低延迟应用中表现出色。
 REDIS的角色:探索数据存储和管理功能Apr 22, 2025 am 12:10 AM
REDIS的角色:探索数据存储和管理功能Apr 22, 2025 am 12:10 AMRedis在数据存储和管理中扮演着关键角色,通过其多种数据结构和持久化机制成为现代应用的核心。1)Redis支持字符串、列表、集合、有序集合和哈希表等数据结构,适用于缓存和复杂业务逻辑。2)通过RDB和AOF两种持久化方式,Redis确保数据的可靠存储和快速恢复。
 REDIS:了解NOSQL概念Apr 21, 2025 am 12:04 AM
REDIS:了解NOSQL概念Apr 21, 2025 am 12:04 AMRedis是一种NoSQL数据库,适用于大规模数据的高效存储和访问。1.Redis是开源的内存数据结构存储系统,支持多种数据结构。2.它提供极快的读写速度,适合缓存、会话管理等。3.Redis支持持久化,通过RDB和AOF方式确保数据安全。4.使用示例包括基本的键值对操作和高级的集合去重功能。5.常见错误包括连接问题、数据类型不匹配和内存溢出,需注意调试。6.性能优化建议包括选择合适的数据结构和设置内存淘汰策略。
 REDIS:现实世界的用例和示例Apr 20, 2025 am 12:06 AM
REDIS:现实世界的用例和示例Apr 20, 2025 am 12:06 AMRedis在现实世界中的应用包括:1.作为缓存系统加速数据库查询,2.存储Web应用的会话数据,3.实现实时排行榜,4.作为消息队列简化消息传递。Redis的多功能性和高性能使其在这些场景中大放异彩。
 REDIS:探索其功能和功能Apr 19, 2025 am 12:04 AM
REDIS:探索其功能和功能Apr 19, 2025 am 12:04 AMRedis脱颖而出是因为其高速、多功能性和丰富的数据结构。1)Redis支持字符串、列表、集合、散列和有序集合等数据结构。2)它通过内存存储数据,支持RDB和AOF持久化。3)从Redis6.0开始引入多线程处理I/O操作,提升了高并发场景下的性能。
 Redis是SQL还是NOSQL数据库?答案解释了Apr 18, 2025 am 12:11 AM
Redis是SQL还是NOSQL数据库?答案解释了Apr 18, 2025 am 12:11 AMRedisisclassifiedasaNoSQLdatabasebecauseitusesakey-valuedatamodelinsteadofthetraditionalrelationaldatabasemodel.Itoffersspeedandflexibility,makingitidealforreal-timeapplicationsandcaching,butitmaynotbesuitableforscenariosrequiringstrictdataintegrityo
 REDIS:提高应用程序性能和可扩展性Apr 17, 2025 am 12:16 AM
REDIS:提高应用程序性能和可扩展性Apr 17, 2025 am 12:16 AMRedis通过缓存数据、实现分布式锁和数据持久化来提升应用性能和可扩展性。1)缓存数据:使用Redis缓存频繁访问的数据,提高数据访问速度。2)分布式锁:利用Redis实现分布式锁,确保在分布式环境中操作的安全性。3)数据持久化:通过RDB和AOF机制保证数据安全性,防止数据丢失。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

禅工作室 13.0.1
功能强大的PHP集成开发环境

