



场景设定
1、我们需要将POJO存储到缓存中,该类定义如下
public class TestPOJO implements Serializable {
private String testStatus;
private String userPin;
private String investor;
private Date testQueryTime;
private Date createTime;
private String bizInfo;
private Date otherTime;
private BigDecimal userAmount;
private BigDecimal userRate;
private BigDecimal applyAmount;
private String type;
private String checkTime;
private String preTestStatus;
public Object[] toValueArray(){
Object[] array = {testStatus, userPin, investor, testQueryTime,
createTime, bizInfo, otherTime, userAmount,
userRate, applyAmount, type, checkTime, preTestStatus};
return array;
}
public CreditRecord fromValueArray(Object[] valueArray){
//具体的数据类型会丢失,需要做处理
}
}2、用下面的实例作为测试数据
TestPOJO pojo = new TestPOJO();
pojo.setApplyAmount(new BigDecimal("200.11"));
pojo.setBizInfo("XX");
pojo.setUserAmount(new BigDecimal("1000.00"));
pojo.setTestStatus("SUCCESS");
pojo.setCheckTime("2023-02-02");
pojo.setInvestor("ABCD");
pojo.setUserRate(new BigDecimal("0.002"));
pojo.setTestQueryTime(new Date());
pojo.setOtherTime(new Date());
pojo.setPreTestStatus("PROCESSING");
pojo.setUserPin("ABCDEFGHIJ");
pojo.setType("Y");常规做法
System.out.println(JSON.toJSONString(pojo).length());
使用JSON直接序列化、打印 length=284**,**这种方式是最简单的方式,也是最常用的方式,具体数据如下:
{"applyAmount":200.11,"bizInfo":"XX","checkTime":"2023-02-02","investor":"ABCD","otherTime":"2023-04-10 17:45:17.717","preCheckStatus":"PROCESSING","testQueryTime":"2023-04-10 17:45:17.717","testStatus":"SUCCESS","type":"Y","userAmount":1000.00,"userPin":"ABCDEFGHIJ","userRate":0.002}
我们发现,以上包含了大量无用的数据,其中属性名是没有必要存储的。
改进1-去掉属性名
System.out.println(JSON.toJSONString(pojo.toValueArray()).length());
通过选择数组结构代替对象结构,去掉了属性名,打印 length=144,将数据大小降低了50%,具体数据如下:
["SUCCESS","ABCDEFGHIJ","ABCD","2023-04-10 17:45:17.717",null,"XX","2023-04-10 17:45:17.717",1000.00,0.002,200.11,"Y","2023-02-02","PROCESSING"]
我们发现,null是没有必要存储的,时间的格式被序列化为字符串,不合理的序列化结果,导致了数据的膨胀,所以我们应该选用更好的序列化工具。
改进2-使用更好的序列化工具
//我们仍然选取JSON格式,但使用了第三方序列化工具 System.out.println(new ObjectMapper(new MessagePackFactory()).writeValueAsBytes(pojo.toValueArray()).length);
选取更好的序列化工具,实现字段的压缩和合理的数据格式,打印 **length=92,**空间比上一步又降低了40%。
这是一份二进制数据,需要以二进制操作Redis,将二进制转为字符串后,打印如下:
��SUCCESS�ABCDEFGHIJ�ABCD��j�6���XX��j�6����?`bM����@i��Q�Y�2023-02-02�PROCESSING
顺着这个思路再深挖,我们发现,可以通过手动选择数据类型,实现更极致的优化效果,选择使用更小的数据类型,会获得进一步的提升。
改进3-优化数据类型
在以上用例中,testStatus、preCheckStatus、investor这3个字段,实际上是枚举字符串类型,如果能够使用更简单数据类型(比如byte或者int等)替代string,还可以进一步节省空间。可以使用Long类型代替字符串来表示checkTime,这样序列化工具输出的字节数会更少。
public Object[] toValueArray(){
Object[] array = {toInt(testStatus), userPin, toInt(investor), testQueryTime,
createTime, bizInfo, otherTime, userAmount,
userRate, applyAmount, type, toLong(checkTime), toInt(preTestStatus)};
return array;
}在手动调整后,使用了更小的数据类型替代了String类型,打印 length=69
改进4-考虑ZIP压缩
除了以上的几点之外,还可以考虑使用ZIP压缩方式获取更小的体积,在内容较大或重复性较多的情况下,ZIP压缩的效果明显,如果存储的内容是TestPOJO的数组,可能适合使用ZIP压缩。
对于小于30个字节的文件,ZIP压缩可能增加文件大小,不一定能减少文件体积。在重复性内容较少的情况下,无法获得明显提升。并且存在CPU开销。
在经过以上优化之后,ZIP压缩不再是必选项,需要根据实际数据做测试才能分辨到ZIP的压缩效果。
最终落地
上面的几个改进步骤体现了优化的思路,但是反序列化的过程会导致类型的丢失,处理起来比较繁琐,所以我们还需要考虑反序列化的问题。
在缓存对象被预定义的情况下,我们完全可以手动处理每个字段,所以在实战中,推荐使用手动序列化达到上述目的,实现精细化的控制,达到最好的压缩效果和最小的性能开销。
可以参考以下msgpack的实现代码,以下为测试代码,请自行封装更好的Packer和UnPacker等工具:
<dependency>
<groupId>org.msgpack</groupId>
<artifactId>msgpack-core</artifactId>
<version>0.9.3</version>
</dependency> public byte[] toByteArray() throws Exception {
MessageBufferPacker packer = MessagePack.newDefaultBufferPacker();
toByteArray(packer);
packer.close();
return packer.toByteArray();
}
public void toByteArray(MessageBufferPacker packer) throws Exception {
if (testStatus == null) {
packer.packNil();
}else{
packer.packString(testStatus);
}
if (userPin == null) {
packer.packNil();
}else{
packer.packString(userPin);
}
if (investor == null) {
packer.packNil();
}else{
packer.packString(investor);
}
if (testQueryTime == null) {
packer.packNil();
}else{
packer.packLong(testQueryTime.getTime());
}
if (createTime == null) {
packer.packNil();
}else{
packer.packLong(createTime.getTime());
}
if (bizInfo == null) {
packer.packNil();
}else{
packer.packString(bizInfo);
}
if (otherTime == null) {
packer.packNil();
}else{
packer.packLong(otherTime.getTime());
}
if (userAmount == null) {
packer.packNil();
}else{
packer.packString(userAmount.toString());
}
if (userRate == null) {
packer.packNil();
}else{
packer.packString(userRate.toString());
}
if (applyAmount == null) {
packer.packNil();
}else{
packer.packString(applyAmount.toString());
}
if (type == null) {
packer.packNil();
}else{
packer.packString(type);
}
if (checkTime == null) {
packer.packNil();
}else{
packer.packString(checkTime);
}
if (preTestStatus == null) {
packer.packNil();
}else{
packer.packString(preTestStatus);
}
}
public void fromByteArray(byte[] byteArray) throws Exception {
MessageUnpacker unpacker = MessagePack.newDefaultUnpacker(byteArray);
fromByteArray(unpacker);
unpacker.close();
}
public void fromByteArray(MessageUnpacker unpacker) throws Exception {
if (!unpacker.tryUnpackNil()){
this.setTestStatus(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setUserPin(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setInvestor(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setTestQueryTime(new Date(unpacker.unpackLong()));
}
if (!unpacker.tryUnpackNil()){
this.setCreateTime(new Date(unpacker.unpackLong()));
}
if (!unpacker.tryUnpackNil()){
this.setBizInfo(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setOtherTime(new Date(unpacker.unpackLong()));
}
if (!unpacker.tryUnpackNil()){
this.setUserAmount(new BigDecimal(unpacker.unpackString()));
}
if (!unpacker.tryUnpackNil()){
this.setUserRate(new BigDecimal(unpacker.unpackString()));
}
if (!unpacker.tryUnpackNil()){
this.setApplyAmount(new BigDecimal(unpacker.unpackString()));
}
if (!unpacker.tryUnpackNil()){
this.setType(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setCheckTime(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setPreTestStatus(unpacker.unpackString());
}
}场景延伸
假设,我们为2亿用户存储数据,每个用户包含40个字段,字段key的长度是6个字节,字段是分别管理的。
正常情况下,我们会想到hash结构,而hash结构存储了key的信息,会占用额外资源,字段key属于不必要数据,按照上述思路,可以使用list替代hash结构。
通过Redis官方工具测试,使用list结构需要144G的空间,而使用hash结构需要245G的空间**(当50%以上的属性为空时,需要进行测试,是否仍然适用)**
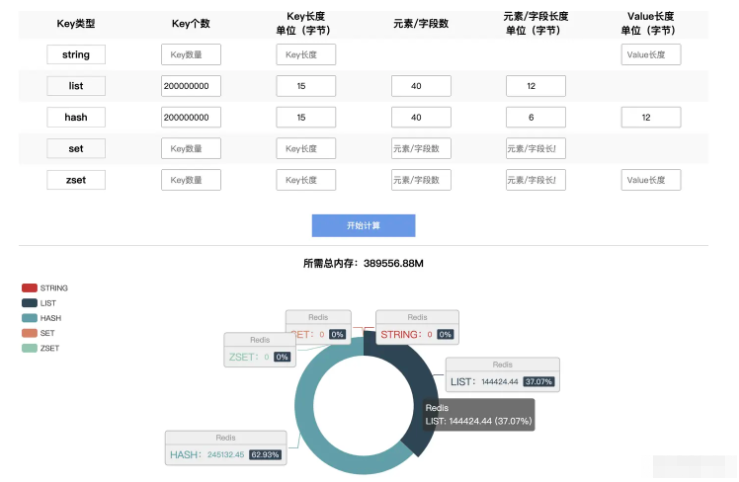
在以上案例中,我们采取了几个非常简单的措施,仅仅有几行简单的代码,可降低空间70%以上,在数据量较大以及性能要求较高的场景中,是非常值得推荐的。:
• 使用数组替代对象(如果大量字段为空,需配合序列化工具对null进行压缩)
• 使用更好的序列化工具
• 使用更小的数据类型
• 考虑使用ZIP压缩
• 使用list替代hash结构(如果大量字段为空,需要进行测试对比)
以上是Redis缓存空间怎么优化的详细内容。更多信息请关注PHP中文网其他相关文章!

 REDIS:探索其功能和功能Apr 19, 2025 am 12:04 AM
REDIS:探索其功能和功能Apr 19, 2025 am 12:04 AMRedis脱颖而出是因为其高速、多功能性和丰富的数据结构。1)Redis支持字符串、列表、集合、散列和有序集合等数据结构。2)它通过内存存储数据,支持RDB和AOF持久化。3)从Redis6.0开始引入多线程处理I/O操作,提升了高并发场景下的性能。
 Redis是SQL还是NOSQL数据库?答案解释了Apr 18, 2025 am 12:11 AM
Redis是SQL还是NOSQL数据库?答案解释了Apr 18, 2025 am 12:11 AMRedisisclassifiedasaNoSQLdatabasebecauseitusesakey-valuedatamodelinsteadofthetraditionalrelationaldatabasemodel.Itoffersspeedandflexibility,makingitidealforreal-timeapplicationsandcaching,butitmaynotbesuitableforscenariosrequiringstrictdataintegrityo
 REDIS:提高应用程序性能和可扩展性Apr 17, 2025 am 12:16 AM
REDIS:提高应用程序性能和可扩展性Apr 17, 2025 am 12:16 AMRedis通过缓存数据、实现分布式锁和数据持久化来提升应用性能和可扩展性。1)缓存数据:使用Redis缓存频繁访问的数据,提高数据访问速度。2)分布式锁:利用Redis实现分布式锁,确保在分布式环境中操作的安全性。3)数据持久化:通过RDB和AOF机制保证数据安全性,防止数据丢失。
 REDIS:探索其数据模型和结构Apr 16, 2025 am 12:09 AM
REDIS:探索其数据模型和结构Apr 16, 2025 am 12:09 AMRedis的数据模型和结构包括五种主要类型:1.字符串(String):用于存储文本或二进制数据,支持原子操作。2.列表(List):有序元素集合,适合队列和堆栈。3.集合(Set):无序唯一元素集合,支持集合运算。4.有序集合(SortedSet):带分数的唯一元素集合,适用于排行榜。5.哈希表(Hash):键值对集合,适合存储对象。
 REDIS:对其数据库方法进行分类Apr 15, 2025 am 12:06 AM
REDIS:对其数据库方法进行分类Apr 15, 2025 am 12:06 AMRedis的数据库方法包括内存数据库和键值存储。1)Redis将数据存储在内存中,读写速度快。2)它使用键值对存储数据,支持复杂数据结构,如列表、集合、哈希表和有序集合,适用于缓存和NoSQL数据库。
 为什么要使用redis?利益和优势Apr 14, 2025 am 12:07 AM
为什么要使用redis?利益和优势Apr 14, 2025 am 12:07 AMRedis是一个强大的数据库解决方案,因为它提供了极速性能、丰富的数据结构、高可用性和扩展性、持久化能力以及广泛的生态系统支持。1)极速性能:Redis的数据存储在内存中,读写速度极快,适合高并发和低延迟应用。2)丰富的数据结构:支持多种数据类型,如列表、集合等,适用于多种场景。3)高可用性和扩展性:支持主从复制和集群模式,实现高可用性和水平扩展。4)持久化和数据安全:通过RDB和AOF两种方式实现数据持久化,确保数据的完整性和可靠性。5)广泛的生态系统和社区支持:拥有庞大的生态系统和活跃社区,
 了解NOSQL:Redis的关键特征Apr 13, 2025 am 12:17 AM
了解NOSQL:Redis的关键特征Apr 13, 2025 am 12:17 AMRedis的关键特性包括速度、灵活性和丰富的数据结构支持。1)速度:Redis作为内存数据库,读写操作几乎瞬时,适用于缓存和会话管理。2)灵活性:支持多种数据结构,如字符串、列表、集合等,适用于复杂数据处理。3)数据结构支持:提供字符串、列表、集合、哈希表等,适合不同业务需求。
 REDIS:确定其主要功能Apr 12, 2025 am 12:01 AM
REDIS:确定其主要功能Apr 12, 2025 am 12:01 AMRedis的核心功能是高性能的内存数据存储和处理系统。1)高速数据访问:Redis将数据存储在内存中,提供微秒级别的读写速度。2)丰富的数据结构:支持字符串、列表、集合等,适应多种应用场景。3)持久化:通过RDB和AOF方式将数据持久化到磁盘。4)发布订阅:可用于消息队列或实时通信系统。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

SublimeText3汉化版
中文版,非常好用

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

Dreamweaver CS6
视觉化网页开发工具

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

禅工作室 13.0.1
功能强大的PHP集成开发环境

