



一、问题引入
例如当前存在一张表test_user,然后往这个表里面插入3百万的数据:
CREATE TABLE `test_user` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键id', `user_id` varchar(36) NOT NULL COMMENT '用户id', `user_name` varchar(30) NOT NULL COMMENT '用户名称', `phone` varchar(20) NOT NULL COMMENT '手机号码', `lan_id` int(9) NOT NULL COMMENT '本地网', `region_id` int(9) NOT NULL COMMENT '区域', `create_time` datetime NOT NULL COMMENT '创建时间', PRIMARY KEY (`id`), KEY `idx_user_id` (`user_id`) ) ENGINE=InnoDB AUTO_INCREMENT;
在数据库开发过程中我们经常会使用分页,核心技术是使用用 limit start, count 分页语句进行数据的读取。
我们分别看下从0、10000、100000、500000、1000000、1800000开始分页的执行时长(每页取100条)。
SELECT * FROM test_user LIMIT 0,100; # 0.031 SELECT * FROM test_user LIMIT 10000,100; # 0.047 SELECT * FROM test_user LIMIT 100000,100; # 0.109 SELECT * FROM test_user LIMIT 500000,100; # 0.219 SELECT * FROM test_user LIMIT 1000000,100; # 0.547s SELECT * FROM test_user LIMIT 1800000,100; # 1.625s
我们已经看出随着起始记录的增加,时间也随着增大。改变起始记录为290万后,我们可以看到分页语句中的limit和起始页码之间存在很大的关联
SELECT * FROM test_user LIMIT 2900000,100; # 3.062s
我们惊讶的发现MySQL在数据量大的情况下分页起点越大,查询速度越慢!
那么为什么会出现上述这种情况呢?
答案: 因为 limit 2900000,100 的语法实际上是mysql扫描到前2900100条数据,之后丢弃前面的3000000行,这个步骤其实是浪费掉的。
从中我们也能总结出以下两件事情:
limit语句的查询时间与起始记录的位置成正比。
mysql的limit语句是很方便,但是对记录很多的表并不适合直接使用。
二、MySQL中的limit用法
limit子句可以被用于强制select语句返回指定的记录数,其语法格式如下:
SELECT * FROM 表名 limit m,n; SELECT * FROM table LIMIT [offset,] rows;
limit接受一个或两个数字参数,参数必须是一个整数常量,如果给定两个参数:
第一个参数指定第一个返回记录行的偏移量
第二个参数指定返回记录行的最大数目
2.1 m代表从m+1条记录行开始检索,n代表取出n条数据。(m可设为0)
SELECT * FROM 表名 limit 6,5;
上述SQL表示从第7条记录行开始算,取出5条数据
2.2 值得注意的是,n可以被设置为-1,当n为-1时,表示从m+1行开始检索,直到取出最后一条数据
SELECT * FROM 表名 limit 6,-1;
上述SQL表示取出第6条记录行以后的所有数据
2.3 若只给出m,则表示从第1条记录行开始算一共取出m条
SELECT * FROM 表名 limit 6;
2.4 以年龄倒序后取出前3行
select * from student order by age desc limit 3;
2.5 跳过前3行后再2取行
select * from student order by age desc limit 3,2;
三、深度分页优化策略
方法一:用主键id或者唯一索引优化
即先找到上次分页的最大id,然后利用id上的索引来查询:
SELECT * FROM test_user WHERE id>1000000 LIMIT 100; # 0.047秒
使用此优化SQL相比于前面的查询速度已经快了11倍。除了使用主键ID,还可以运用唯一索引来快速定位特定数据,从而避免全表扫描。以下是相应的SQL优化代码,读取唯一键(pk)在1000至1019范围内的数据:
SELECT * FROM 表名称 WHERE pk>=1000 ORDER BY pk ASC LIMIT 0,20
原因:索引扫描,速度会很快。
适用场景:如果数据查询出来是按照pk或者id进行排序,并且全部数据没有缺失的话则可以这样优化,否则分页操作会漏数据。
方法二:利用索引覆盖优化
我们都知道,利用了索引查询的语句中如果只包含了那个索引列(也就是索引覆盖),那么这种情况会查询很快。
为什么索引覆盖查询会很快呢?
答案:因为利用索引查找有优化算法,且数据就在查询索引上面,不用再去找相关的数据地址了,这样节省了很多时间。当并发量较高时,Mysql还提供了与索引相关联的缓存,充分利用此缓存可以获得更佳的效果。
由于在我们的测试表test_user中,id字段是主键,因此默认包含了主键索引。现在让我们看看利用覆盖索引的查询效果如何。
这次我们查询第1000001到1000100行的数据(利用覆盖索引,只包含id列):
SELECT id FROM test_user LIMIT 1000000,100; # 0.843秒
从这个结果中发现查询速度比全表扫描速度还要慢(当然在重复执行这条SQL,多次查询之后速度还是变快了很多,几乎省了一半时间,这是由于缓存的原因), 接着使用explain命令来查看该SQL的执行计划,发现该SQL执行采用的普通索引 idx_user_id:
EXPLAIN SELECT id FROM test_user LIMIT 1000000,100;
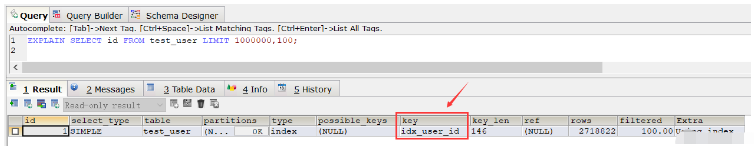
如果我们删除普通索引,则执行上述SQL时会使用主键索引。那如果不删除普通索引的话,针对这种情况,我们要让上述SQL走主键索引的话,则可以使用order by语句:
SELECT id FROM test_user ORDER BY id ASC LIMIT 1000000,100; # 0.250秒
那么如果我们也要查询所有列,有两种方法,一种是id>=的形式,另一种就是利用join。
第一种写法:
SELECT * FROM test_user WHERE ID >= (SELECT id FROM test_user ORDER BY id ASC LIMIT 1000000,1) LIMIT 100;
上述SQL查询时间为0.281秒
第二种写法:
SELECT * FROM (SELECT id FROM test_user ORDER BY id ASC LIMIT 1000000,100) a LEFT JOIN test_user b ON a.id = b.id;
上述SQL查询时间为0.252秒
方法三:基于索引再排序
其中pageNum表示页码,其取值从0开始;pageSize表示指的是每页多少条数据。
SELECT * FROM 表名称 WHERE id_pk > (pageNum*pageSize) ORDER BY id_pk ASC LIMIT pageSize;
适应场景:
适用于数据量多的情况
最好ORDER BY后的列对象是主键或唯一索引
id数据没有缺失,可以作为序号使用
使用ORDER BY操作能利用索引被消除,但结果集是稳定的
原因:
索引扫描,速度会很快
但MySQL的排序操作,只有ASC没有DESC。在MySQL中,索引的存储顺序是升序ASC,没有降序DESC的索引。这就是为什么默认情况下,order by 是按照升序排序的原因
方法四:基于索引使用prepare
PREPARE预编译一个SQL语句,并为其分配一个名称 stmt_name,以便以后引用该语句,预编译好的语句用EXECUTE执行。
PREPARE stmt_name FROM 'SELECT * FROM test_user WHERE id > ? ORDER BY id ASC LIMIT ?'; SET @a = 1000000; SET @b = 100; EXECUTE stmt_name USING @a, @b;;

上述SQL查询时间为0.047秒。
对于定义好的PREPARE预编译语句,我们可以使用下述命令来释放该预编译语句:
DEALLOCATE PREPARE stmt_name;
原因:
索引扫描,速度会很快.
prepare语句又比一般的查询语句快一点。
方法五:利用"子查询+索引"快速定位数据
其中page表示页码,其取值从0开始;pagesize表示指的是每页多少条数据。
SELECT * FROM your_table WHERE id <= (SELECT id FROM your_table ORDER BY id DESC LIMIT ($page-1)*$pagesize ORDER BY id DESC LIMIT $pagesize);
方法六:利用复合索引进行优化
假设数据表 collect ( id, title ,info ,vtype) 就这4个字段,其中id是主键自增,title用定长,info用text, vtype是tinyint,vtype是一个普通索引。
现在往里面填充数据,填充10万条记录,数据库表占用硬1.6G。
select id,title from collect limit 1000,10;
执行上述SQL速度很快,基本上0.01秒就OK。
select id,title from collect limit 90000,10;
然后再执行上述SQL,就发现非常慢,基本上平均8~9秒完成。
这个时候如果我们执行下述,我们会发现速度又变的很快,0.04秒就OK。
select id from collect order by id limit 90000,10;
那么这个现象的原因是什么?
答案:因为用了id主键做索引, 这里实现了索引覆盖,当然快。
所以如果想一起查询其它列的话,可以按照索引覆盖进行优化,具体如下:
select id,title from collect where id >= (select id from collect order by id limit 90000,1) limit 10;
再看下面的语句,带上where 条件:
select id from collect where vtype=1 order by id limit 90000,10;
可以发现这个速度上也是很慢的,用了8~9秒!
这里有一个疑惑:vtype 做了索引了啊?怎么会慢呢?
vtype做了索引是不错,如果直接对vtype进行过滤:
select id from collect where vtype=1 limit 1000,10;
可以看到速度还是很快的,基本上0.05秒,如果从9万开始,那就是0.05*90=4.5秒的速度了。
其实加了 order by id 就不走索引,这样做还是全表扫描,解决的办法是:复合索引!
因此针对下述SQL深度分页优化时可以加一个search_index(vtype,id)复合索引:
select id from collect where vtype=1 order by id limit 90000,10;
综上:
在进行SQL查询深度分页优化时,如果对于有where条件,又想走索引用limit的,必须设计一个索引,将where放第一位,limit用到的主键放第二位,而且只能select 主键。
最后根据查询出的主键走一级索引找到对应的数据。
按这样的逻辑,百万级的limit 在0.0x秒就可以分完,完美解决了分页问题。
以上是MySQL调优之SQL查询深度分页问题怎么解决的详细内容。更多信息请关注PHP中文网其他相关文章!

 MySQL索引基数如何影响查询性能?Apr 14, 2025 am 12:18 AM
MySQL索引基数如何影响查询性能?Apr 14, 2025 am 12:18 AMMySQL索引基数对查询性能有显着影响:1.高基数索引能更有效地缩小数据范围,提高查询效率;2.低基数索引可能导致全表扫描,降低查询性能;3.在联合索引中,应将高基数列放在前面以优化查询。
 MySQL:新用户的资源和教程Apr 14, 2025 am 12:16 AM
MySQL:新用户的资源和教程Apr 14, 2025 am 12:16 AMMySQL学习路径包括基础知识、核心概念、使用示例和优化技巧。1)了解表、行、列、SQL查询等基础概念。2)学习MySQL的定义、工作原理和优势。3)掌握基本CRUD操作和高级用法,如索引和存储过程。4)熟悉常见错误调试和性能优化建议,如合理使用索引和优化查询。通过这些步骤,你将全面掌握MySQL的使用和优化。
 现实世界Mysql:示例和用例Apr 14, 2025 am 12:15 AM
现实世界Mysql:示例和用例Apr 14, 2025 am 12:15 AMMySQL在现实世界的应用包括基础数据库设计和复杂查询优化。1)基本用法:用于存储和管理用户数据,如插入、查询、更新和删除用户信息。2)高级用法:处理复杂业务逻辑,如电子商务平台的订单和库存管理。3)性能优化:通过合理使用索引、分区表和查询缓存来提升性能。
 MySQL中的SQL命令:实践示例Apr 14, 2025 am 12:09 AM
MySQL中的SQL命令:实践示例Apr 14, 2025 am 12:09 AMMySQL中的SQL命令可以分为DDL、DML、DQL、DCL等类别,用于创建、修改、删除数据库和表,插入、更新、删除数据,以及执行复杂的查询操作。1.基本用法包括CREATETABLE创建表、INSERTINTO插入数据和SELECT查询数据。2.高级用法涉及JOIN进行表联接、子查询和GROUPBY进行数据聚合。3.常见错误如语法错误、数据类型不匹配和权限问题可以通过语法检查、数据类型转换和权限管理来调试。4.性能优化建议包括使用索引、避免全表扫描、优化JOIN操作和使用事务来保证数据一致性
 InnoDB如何处理酸合规性?Apr 14, 2025 am 12:03 AM
InnoDB如何处理酸合规性?Apr 14, 2025 am 12:03 AMInnoDB通过undolog实现原子性,通过锁机制和MVCC实现一致性和隔离性,通过redolog实现持久性。1)原子性:使用undolog记录原始数据,确保事务可回滚。2)一致性:通过行级锁和MVCC确保数据一致。3)隔离性:支持多种隔离级别,默认使用REPEATABLEREAD。4)持久性:使用redolog记录修改,确保数据持久保存。
 MySQL的位置:数据库和编程Apr 13, 2025 am 12:18 AM
MySQL的位置:数据库和编程Apr 13, 2025 am 12:18 AMMySQL在数据库和编程中的地位非常重要,它是一个开源的关系型数据库管理系统,广泛应用于各种应用场景。1)MySQL提供高效的数据存储、组织和检索功能,支持Web、移动和企业级系统。2)它使用客户端-服务器架构,支持多种存储引擎和索引优化。3)基本用法包括创建表和插入数据,高级用法涉及多表JOIN和复杂查询。4)常见问题如SQL语法错误和性能问题可以通过EXPLAIN命令和慢查询日志调试。5)性能优化方法包括合理使用索引、优化查询和使用缓存,最佳实践包括使用事务和PreparedStatemen
 MySQL:从小型企业到大型企业Apr 13, 2025 am 12:17 AM
MySQL:从小型企业到大型企业Apr 13, 2025 am 12:17 AMMySQL适合小型和大型企业。1)小型企业可使用MySQL进行基本数据管理,如存储客户信息。2)大型企业可利用MySQL处理海量数据和复杂业务逻辑,优化查询性能和事务处理。
 幻影是什么读取的,InnoDB如何阻止它们(下一个键锁定)?Apr 13, 2025 am 12:16 AM
幻影是什么读取的,InnoDB如何阻止它们(下一个键锁定)?Apr 13, 2025 am 12:16 AMInnoDB通过Next-KeyLocking机制有效防止幻读。1)Next-KeyLocking结合行锁和间隙锁,锁定记录及其间隙,防止新记录插入。2)在实际应用中,通过优化查询和调整隔离级别,可以减少锁竞争,提高并发性能。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

