


科学家们不仅在寻找治疗帕金森氏症的方法,他们还在忙于寻找更好的方法,来及早发现并遏制其发展。

上图:神经网络建立在加权节点层上。
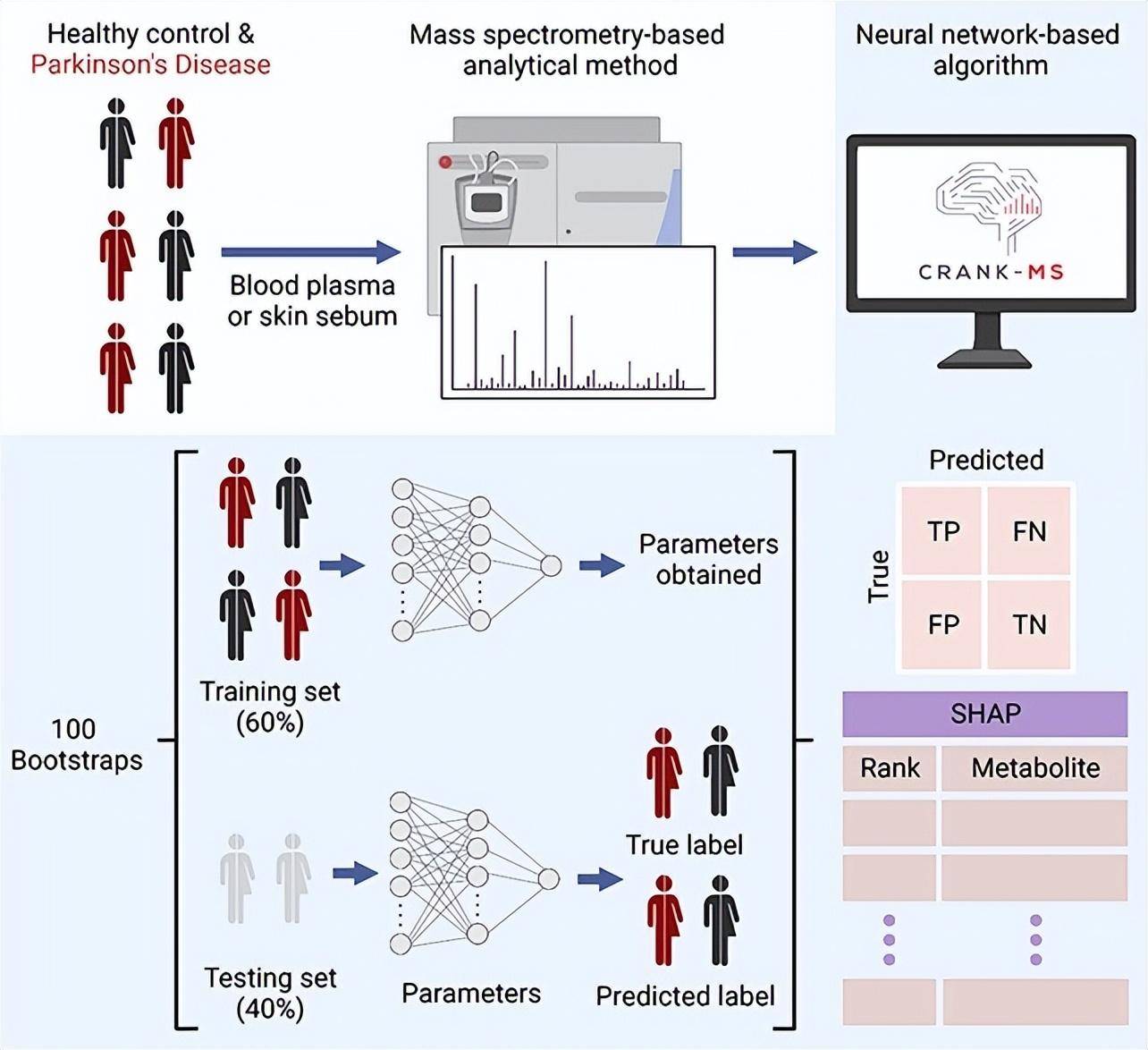
现在,一种可以在标准笔记本电脑上快速运行的新工具利用人工智能,在震颤和行动迟缓等症状出现前几年,就能检测到这种疾病的潜在迹象。它被称为“CRANK-MS”:使用神经网络的分类和排序分析从质谱学中产生知识。
该工具使用模拟人脑的训练有素的节点层,在血液中寻找特定的化合物(代谢物),找出可能预测疾病存在或预防疾病的模式。
澳大利亚新南威尔士大学的化学家戴安娜·张(Diana Zhang)说:“为了弄清楚与对照组相比,哪些代谢物对这种疾病更重要,研究人员通常会研究涉及特定分子的相关性。但在这里,我们考虑到代谢物可能与其他代谢物有关联 —— 这就是机器学习的用之道。对于成百上千的代谢物,我们使用了计算能力来了解发生了什么。”
研究小组使用的血浆样本是西班牙欧洲营养与癌症前瞻性研究的一部分。研究小组关注了39名在参与研究后15年内患上帕金森病的患者,并将代谢物混合物与39名没有患上帕金森病的对照组患者进行了比较。确定了几个被认为具有潜在重要意义的模式。
这些代谢物是在人体分解食物、药物或化学物质时产生的。例如,研究小组注意到,患有帕金森症的人血液中的三萜含量往往较低,三萜在细胞水平上处理身体的压力,存在于苹果、橄榄和西红柿等食物中。
研究人员还注意到,后来患上帕金森症的人体内存在多氟烷基物质(PFAS)。这可能与工业化学品的高暴露有关,但需要涉及更多患者的更大规模研究才能确定。
虽然,这项研究相对较小,但 CRANK-MS 能够检测帕金森病的风险,准确率高达96%。这在一定程度上是因为,从一开始就输入系统的数据的数量和广度,而不需要手动简化或过滤。
上图:血液分析可以用来评估帕金森氏症的风险。
新南威尔士大学的化学家威廉·唐纳德(William Donald)说:“在这里,我们把所有的信息都输入到 CRANK-MS 中,一开始没有任何数据缩减。由此,我们可以得到模型预测,并确定哪些代谢物最能推动预测,所有这些都是一步完成的。这意味着,如果有传统方法可能遗漏的代谢物,我们现在可以提取这些代谢物。”
其他科学家也可以使用 CRANK-MS 。这意味着可以通过血液样本检测出更多的疾病。
研究人员现在希望,看到他们的系统在世界更多地区更大的队列中进行测试,看看人工智能分析是否适用于帕金森氏症 —— 但就血液中代谢物的分析而言,早期的结果是很有希望的。
化学家威廉·唐纳德表示:“首先,在临床诊断之前预测帕金森病的准确性非常高。其次,这种机器学习方法使我们能够识别化学标志物,这些化学标志物在准确预测未来谁会患上帕金森氏症方面是最重要的。第三,一些最能准确预测帕金森病的化学标记物,在之前的基于细胞的分析中,被其他人认为与帕金森病有关,但在人类中却没有。”
这项研究发表在ACS中央科学杂志上。
如果朋友们喜欢,敬请关注“知新了了”!
以上是经过训练,人工智能可以在症状出现前几年检测出帕金森病的详细内容。更多信息请关注PHP中文网其他相关文章!

 再掀强化学习变革!DeepMind提出「算法蒸馏」:可探索的预训练强化学习TransformerApr 12, 2023 pm 06:58 PM
再掀强化学习变革!DeepMind提出「算法蒸馏」:可探索的预训练强化学习TransformerApr 12, 2023 pm 06:58 PM在当下的序列建模任务上,Transformer可谓是最强大的神经网络架构,并且经过预训练的Transformer模型可以将prompt作为条件或上下文学习(in-context learning)适应不同的下游任务。大型预训练Transformer模型的泛化能力已经在多个领域得到验证,如文本补全、语言理解、图像生成等等。从去年开始,已经有相关工作证明,通过将离线强化学习(offline RL)视为一个序列预测问题,那么模型就可以从离线数据中学习策略。但目前的方法要么是从不包含学习的数据中学习策略
 大模型训练成本降低近一半!新加坡国立大学最新优化器已投入使用Jul 17, 2023 pm 10:13 PM
大模型训练成本降低近一半!新加坡国立大学最新优化器已投入使用Jul 17, 2023 pm 10:13 PM优化器在大语言模型的训练中占据了大量内存资源。现在有一种新的优化方式,在性能保持不变的情况下将内存消耗降低了一半。该成果由新加坡国立大学打造,在ACL会议上获得了杰出论文奖,并已经投入了实际应用。图片随着大语言模型不断增加的参数量,训练时的内存消耗问题更为严峻。研究团队提出了CAME优化器,在减少内存消耗的同时,拥有与Adam相同的性能。图片CAME优化器在多个常用的大规模语言模型的预训练上取得了相同甚至超越Adam优化器的训练表现,并对大batch预训练场景显示出更强的鲁棒性。进一步地,通过C
 无需下游训练,Tip-Adapter大幅提升CLIP图像分类准确率Apr 12, 2023 pm 03:25 PM
无需下游训练,Tip-Adapter大幅提升CLIP图像分类准确率Apr 12, 2023 pm 03:25 PM论文链接:https://arxiv.org/pdf/2207.09519.pdf代码链接:https://github.com/gaopengcuhk/Tip-Adapter一.研究背景对比性图像语言预训练模型(CLIP)在近期展现出了强大的视觉领域迁移能力,可以在一个全新的下游数据集上进行 zero-shot 图像识别。为了进一步提升 CLIP 的迁移性能,现有方法使用了 few-shot 的设置,例如 CoOp 和 CLIP-Adapter,即提供了少量下游数据集的训练数据,使得 CLIP
 单机训练200亿参数大模型:Cerebras打破新纪录Apr 18, 2023 pm 12:37 PM
单机训练200亿参数大模型:Cerebras打破新纪录Apr 18, 2023 pm 12:37 PM本周,芯片创业公司Cerebras宣布了一个里程碑式的新进展:在单个计算设备中训练了超过百亿参数的NLP(自然语言处理)人工智能模型。由Cerebras训练的AI模型体量达到了前所未有的200亿参数,所有这些都无需横跨多个加速器扩展工作负载。这项工作足以满足目前网络上最火的文本到图像AI生成模型——OpenAI的120亿参数大模型DALL-E。Cerebras新工作中最重要的一点是对基础设施和软件复杂性的要求降低了。这家公司提供的芯片WaferScaleEngine-
 用少于256KB内存实现边缘训练,开销不到PyTorch千分之一Apr 08, 2023 pm 01:11 PM
用少于256KB内存实现边缘训练,开销不到PyTorch千分之一Apr 08, 2023 pm 01:11 PM说到神经网络训练,大家的第一印象都是 GPU + 服务器 + 云平台。传统的训练由于其巨大的内存开销,往往是云端进行训练而边缘平台仅负责推理。然而,这样的设计使得 AI 模型很难适应新的数据:毕竟现实世界是一个动态的,变化的,发展的场景,一次训练怎么能覆盖所有场景呢?为了使得模型能够不断的适应新数据,我们能否在边缘进行训练(on-device training),使设备不断的自我学习?在这项工作中,我们仅用了不到 256KB 内存就实现了设备上的训练,开销不到 PyTorch 的 1/1000,
 三维场景生成:无需任何神经网络训练,从单个样例生成多样结果Jun 09, 2023 pm 08:22 PM
三维场景生成:无需任何神经网络训练,从单个样例生成多样结果Jun 09, 2023 pm 08:22 PM多样高质的三维场景生成结果论文地址:https://arxiv.org/abs/2304.12670项目主页:http://weiyuli.xyz/Sin3DGen/引言使用人工智能辅助内容生成(AIGC)在图像生成领域涌现出大量的工作,从早期的变分自编码器(VAE),到生成对抗网络(GAN),再到最近大红大紫的扩散模型(DiffusionModel),模型的生成能力飞速提升。以StableDiffusion,Midjourney等为代表的模型在生成具有高真实感图像方面取得了前所未有的成果。同时
 图像质量堪忧干扰视觉识别,达摩院提出更鲁棒框架Apr 14, 2023 pm 04:31 PM
图像质量堪忧干扰视觉识别,达摩院提出更鲁棒框架Apr 14, 2023 pm 04:31 PM本文介绍被机器学习顶级国际会议AAAI2023接收的论文《ImprovingTrainingandInferenceofFaceRecognitionModelsviaRandomTemperatureScaling》。论文创新性地从概率视角出发,对分类损失函数中的温度调节参数和分类不确定度的内在关系进行分析,揭示了分类损失函数的温度调节因子是服从Gumbel分布的不确定度变量的尺度系数。从而提出一个新的被叫做RTS的训练框架对特征抽取的可靠性进行建模。基于RTS
 AI绘画侵权实锤!扩散模型可能记住你的照片,现有隐私保护方法全部失效Apr 12, 2023 pm 10:16 PM
AI绘画侵权实锤!扩散模型可能记住你的照片,现有隐私保护方法全部失效Apr 12, 2023 pm 10:16 PM本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。AI绘画侵权,实锤了!最新研究表明,扩散模型会牢牢记住训练集中的样本,并在生成时“依葫芦画瓢”。也就是说,像Stable Diffusion生成的AI画作里,每一笔背后都可能隐藏着一次侵权事件。不仅如此,经过研究对比,扩散模型从训练样本中“抄袭”的能力是GAN的2倍,且生成效果越好的扩散模型,记住训练样本的能力越强。这项研究来自Google、DeepMind和UC伯克利组成的团队。论文中还有另一个糟糕的消息,那就是针对这


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

禅工作室 13.0.1
功能强大的PHP集成开发环境

