



深度学习的概念源于人工神经网络的研究,含有多个隐藏层的多层感知器是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示,以表征数据的类别或特征。它能够发现数据的分布式特征表示。深度学习是机器学习的一种,而机器学习是实现人工智能的必经之路。
那么,各种深度学习的系统架构之间有哪些差别呢?
1. 全连接网络(FCN)
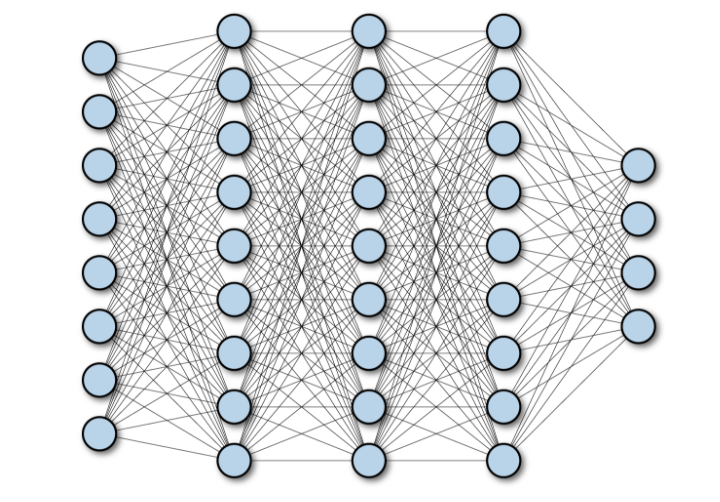
完全连接网络(FCN)由一系列完全连接的层组成,每个层中的每个神经元都连接到另一层中的每个神经元。其主要优点是“结构不可知”,即不需要对输入做出特殊的假设。虽然这种结构不可知使得完全连接网络非常广泛适用,但是这样的网络倾向于比专门针对问题空间结构调整的特殊网络表现更弱。
下图显示了一个多层深度的完全连接网络:
2. 卷积神经网络(CNN)
卷积神经网络(CNN)是一种多层神经网络架构,主要用于图像处理应用。CNN架构明确假定输入具有空间维度(以及可选的深度维度),例如图像,这允许将某些属性编码到模型架构中。Yann LeCun创建了第一个CNN,该架构最初用于识别手写字符。
2.1 CNN的架构特点
分解一下使用CNN的计算机视觉模型的技术细节:
- 模型的输入:CNN模型的输入通常是图像或文本。CNN也可用于文本,但通常不怎么使用。
图像在这里被表示为像素网格,就是由正整数组成的网格,每个数字都被分配一种颜色。
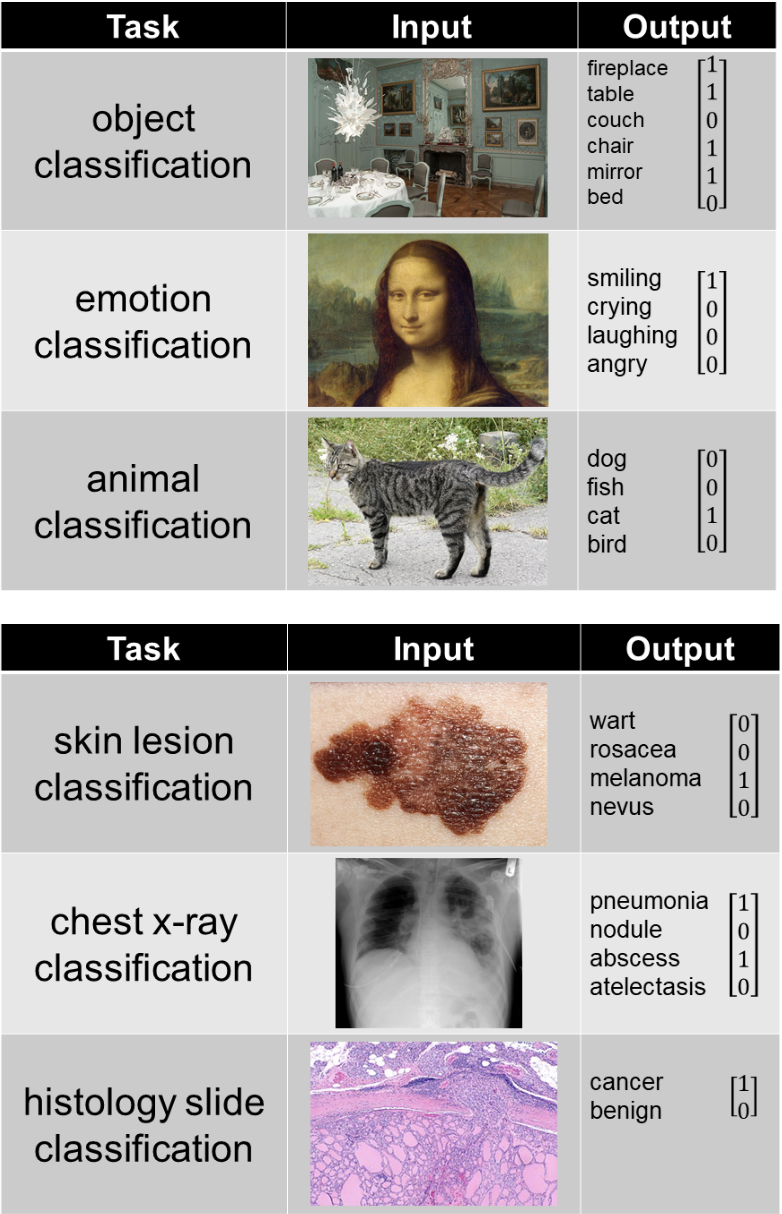
- 模型的输出:模型的输出取决于它试图预测什么,下面的示例表示一些常见的任务:
-

一个简单的卷积神经网络由一系列层构成,每一层通过可微分函数将一个激活的体积块转换为另一个表达。卷积神经网络的架构主要使用三种类型的层:卷积层、池化层和全连接层。下图展示了卷积神经网络层的不同部分:
- 卷积: 卷积过滤器扫描图像,使用加法和乘法操作。CNN试图学习卷积过滤器中的值以预测所需的输出。
- 非线性: 这是应用于卷积过滤器的方程,它允许CNN学习输入和输出图像之间的复杂关系。
- 池化: 也称为“最大池化”,它只选择一系列数字中的最大数字。这有助于减小表达的大小并减少CNN必须进行的计算量,用于提升效率。
这三种操作的结合组成了完全卷积网络。
2.2 CNN的用例
CNN(卷积神经网络)是一种常用于解决与空间数据相关的问题的神经网络,通常用于图像(2D CNN)和音频(1D CNN)等领域。CNN的广泛应用包括人脸识别、医学分析和分类等。通过CNN,可以在图像或音频数据中捕捉到更加细致的特征,从而实现更加精准的识别和分析。此外,CNN也可以应用于其他领域,如自然语言处理和时间序列数据等。总之,CNN是可以帮助我们更好地理解和分析各种类型的数据。
2.3 CNN对比FCN的优势
参数共享/计算可行性:
由于CNN使用参数共享,所以CNN与FCN架构的权重数量通常相差几个数量级。
对于全连接神经网络,有一个形状为(Hin×Win×Cin)的输入和一个形状为(Hout×Wout×Cout)的输出。这意味着输出特征的每个像素颜色都与输入特征的每个像素颜色连接。对于输入图像和输出图像的每个像素,都有一个独立的可学习参数。因此,参数数量为(Hin×Hout×Win×Wout×Cin×Cout)。
在卷积层中,输入是形状为(Hin,Win,Cin)的图像,权重考虑给定像素的邻域大小为K×K。输出是给定像素及其邻域的加权和。输入通道和输出通道的每个对(Cin,Cout)都有一个单独的内核,但内核的权重形状为(K,K,Cin,Cout)的张量与位置无关。实际上,该层可以接受任何分辨率的图像,而全连接层只能使用固定分辨率。最后,该层参数为(K,K,Cin,Cout),对于内核大小K远小于输入分辨率的情况,变量数量会显著减少。
自从AlexNet赢得ImageNet比赛以来,每个赢得比赛的神经网络都使用了CNN组件,这一事实证明CNN对于图像数据更有效。很可能找不到任何有意义的比较,因为仅使用FC层处理图像数据是不可行的,而CNN可以处理这些数据。为什么呢?
FC层中有1000个神经元的权重数量对于图像而言大约为1.5亿。 这仅仅是一个层的权重数量。 而现代的CNN体系结构具有50-100层,同时具有总共几十万个参数(例如,ResNet50具有23M个参数,Inception V3具有21M个参数)。
从数学角度来看,比较CNN和FCN(具有100个隐藏单元)之间的权重数量,输入图像为500×500×3的话:
- FC layer 的 Wx = 100×(500×500×3)=100×750000=75M
- CNN layer =
<code>((shape of width of the filter * shape of height of the filter * number of filters in the previous layer+1)*number of filters)( +1 是为了偏置) = (Fw×Fh×D+1)×F=(5×5×3+1)∗2=152</code>
平移不变性
不变性指的是一个对象即使位置发生了改变,仍然能够被正确地识别。这通常是一个积极的特性,因为它维护了对象的身份(或类别)。这里的“平移”是指在几何学中的特定含义。下图显示了相同的对象在不同的位置上,由于平移不变性,CNN能够正确地识别它们都是猫。
3. 循环神经网络(RNN)
RNN是构建其他深度学习架构的基础网络体系结构之一。一个关键的不同之处在于,与正常的前馈网络不同,RNN可以具有反馈到其先前或同一层的连接。从某种意义上说,RNN在先前的计算中具有“记忆”,并将这些信息用于当前处理。
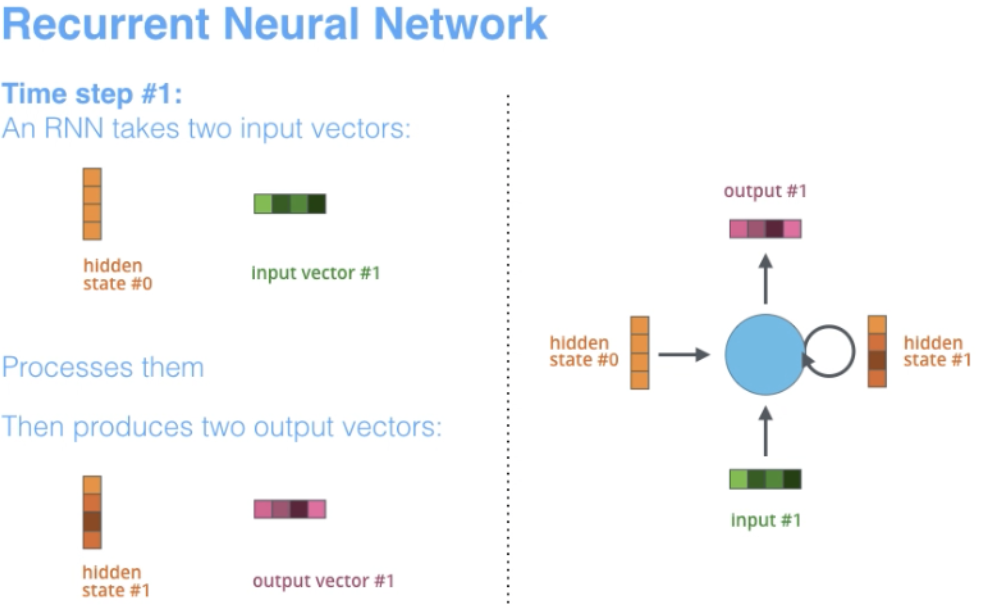
3.1 RNN 的架构特点
“Recurrent”这个术语适用于网络在每个序列实例上执行相同的任务,因此输出取决于先前的计算和结果。
RNN自然适用于许多NLP任务,如语言建模。它们能够捕捉“狗”和“热狗”之间的含义差异,因此RNN是为建模语言和类似序列建模任务中的这种上下文依赖而量身定制的,这成为在这些领域使用RNN而不是CNN的主要原因。RNN的另一个优点是模型大小不随输入大小而增加,因此有可能处理任意长度的输入。
此外,与CNN不同的是,RNN具有灵活的计算步骤,提供更好的建模能力,并创造了捕捉无限上下文的可能性,因为它考虑了历史信息,并且其权重在时间上是共享的。然而,循环神经网络会面临梯度消失问题。梯度变得很小,因此使得反向传播的更新权重非常小。由于每个标记需要顺序处理以及存在梯度消失/爆炸,RNN训练速度慢并且有时很难收敛。
下图斯坦福大学是RNN架构示例。
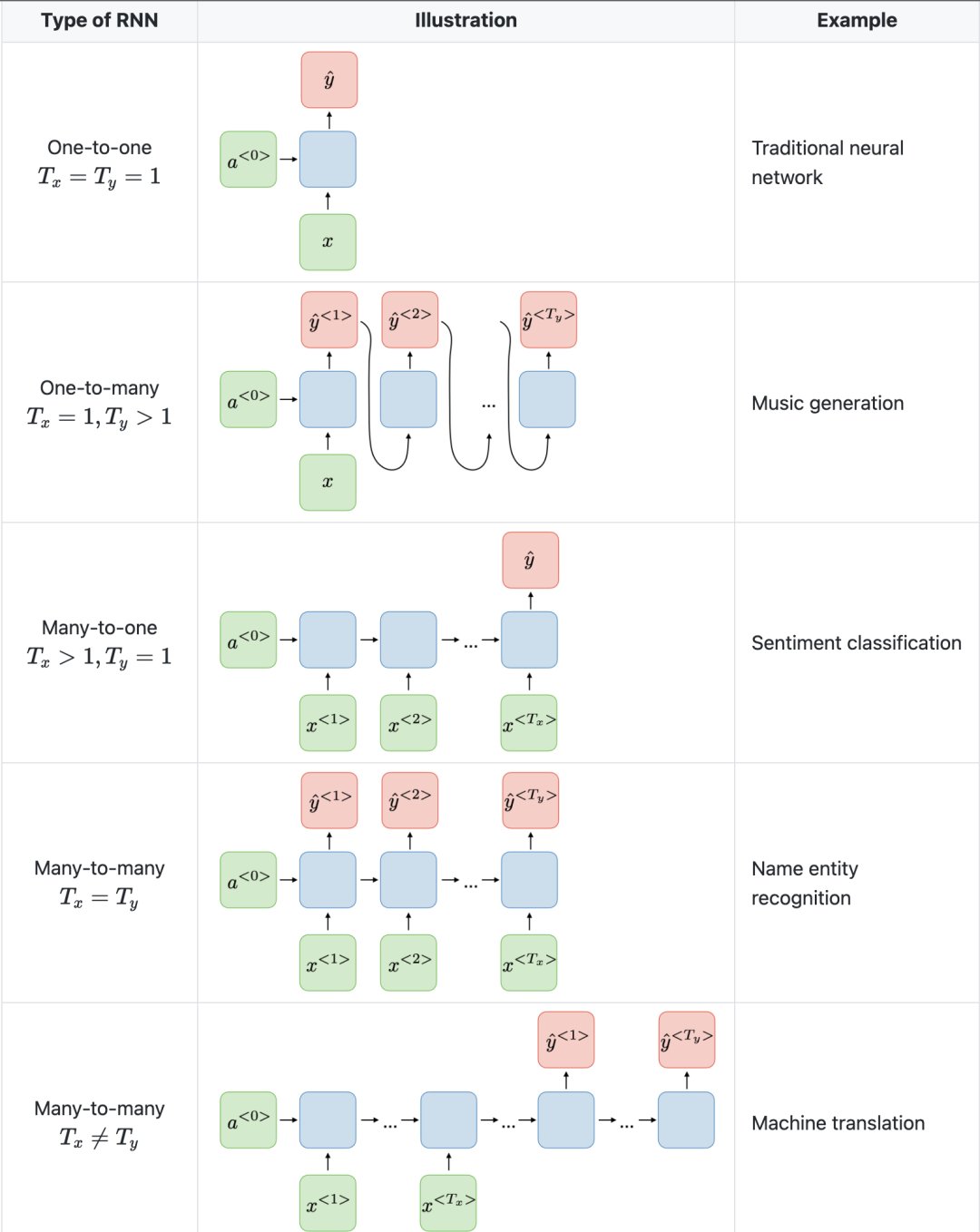
另一个需要注意的是,CNN与RNN具有不同的架构。CNN是一种前馈神经网络,它使用过滤器和池化层,而RNN则通过自回归的方式将结果反馈到网络中。
3.2 RNN的典型用例
RNN是一种专门用于分析时间序列数据的神经网络。其中,时间序列数据是指按时间顺序排列的数据,例如文本或视频。RNN在文本翻译、自然语言处理、情感分析和语音分析等方面具有广泛的应用。例如,它可以用于分析音频记录,以便识别说话人的语音并将其转换为文本。另外,RNN还可以用于文本生成,例如为电子邮件或社交媒体发布创建文本。
3.3 RNN 与CNN 的对比优势
在CNN中,输入和输出的大小是固定的。这意味着CNN接收固定大小的图像,并将其输出到适当的级别,同时伴随其预测的置信度。然而,在RNN中,输入和输出的大小可能会有所变化。这个特性适用于需要可变大小输入和输出的应用,例如生成文本。
门控循环单元(GRU)和长短时记忆单元(LSTM)都提供了解决循环神经网络(RNN)遇到的梯度消失问题的解决方案。
4. 长短记忆神经网络(LSTM)
长短记忆神经网络(LSTM)是一种特殊的RNN。它通过学习长期依赖关系,使RNN更容易在许多时间戳上保留信息。下图是LSTM架构的可视化表示。
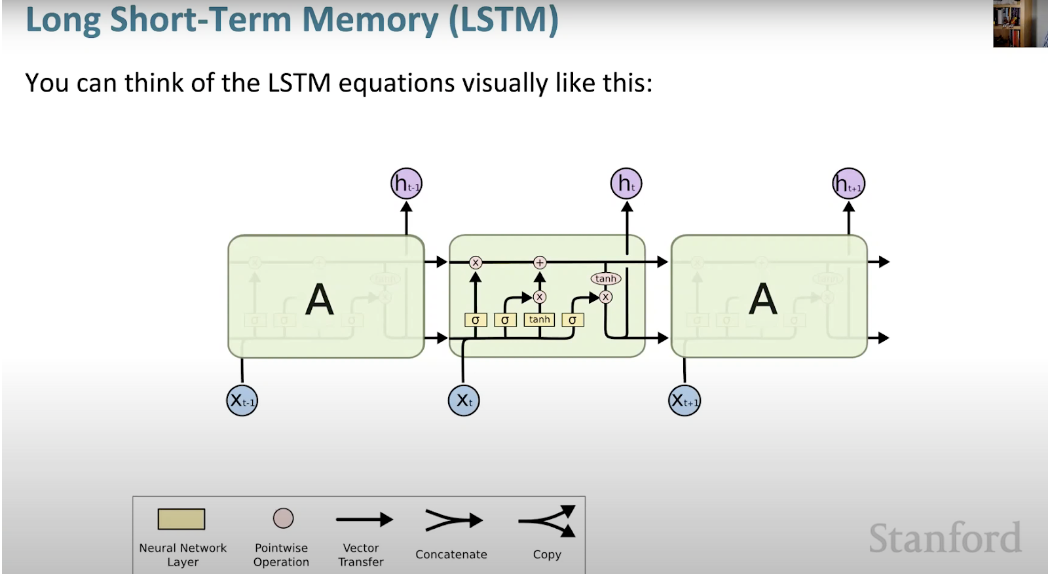
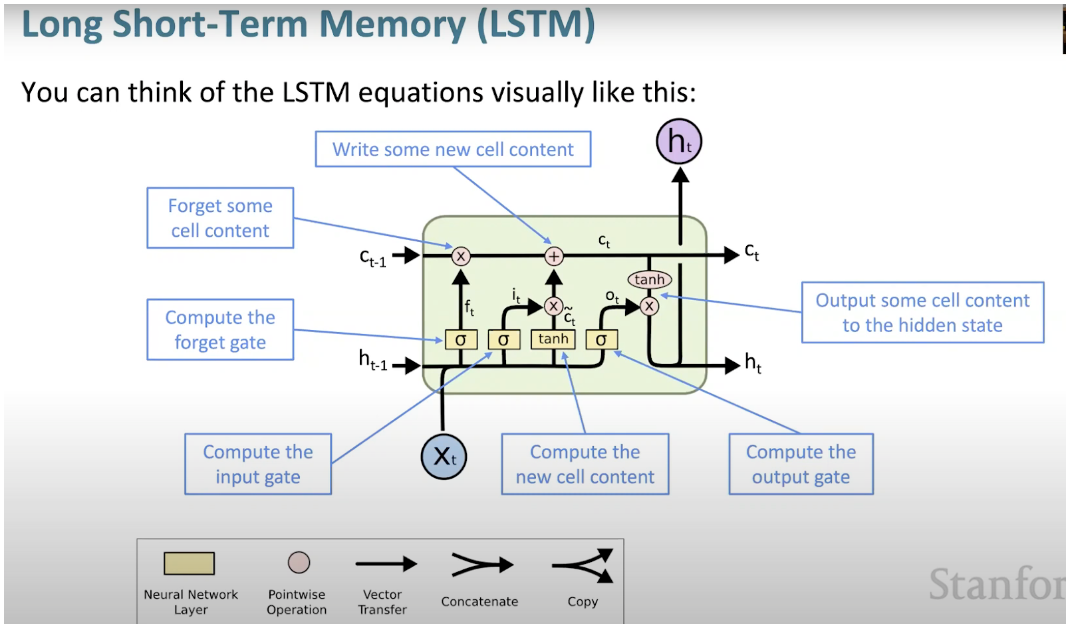
LSTM无处不在,可以在许多应用程序或产品中找到,例如智能手机。其强大之处在于它摆脱了典型的基于神经元的架构,而是采用了记忆单元的概念。这个记忆单元根据其输入的函数保留其值,可以短时间或长时间保持其值。这允许单元记住重要的内容,而不仅仅是最后计算的值。
LSTM 记忆单元包含三个门,控制其单元内的信息流入或流出。
- 输入门:控制何时可以将信息流入内存。
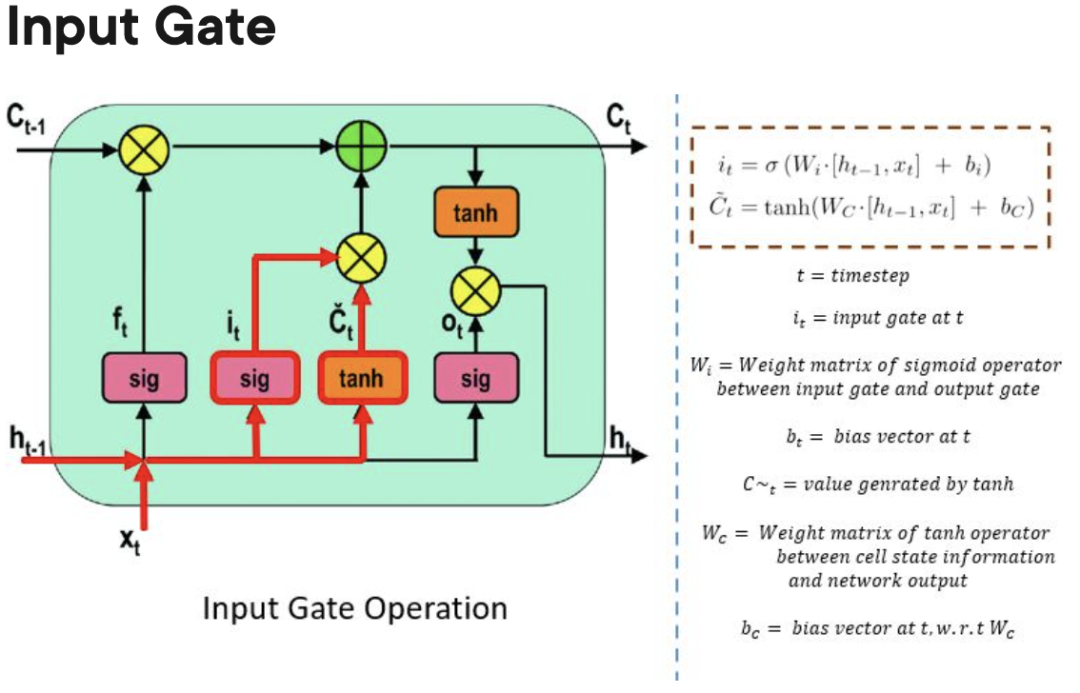
遗忘门:负责跟踪哪些信息可以“遗忘”,为处理单元腾出空间记住新数据。
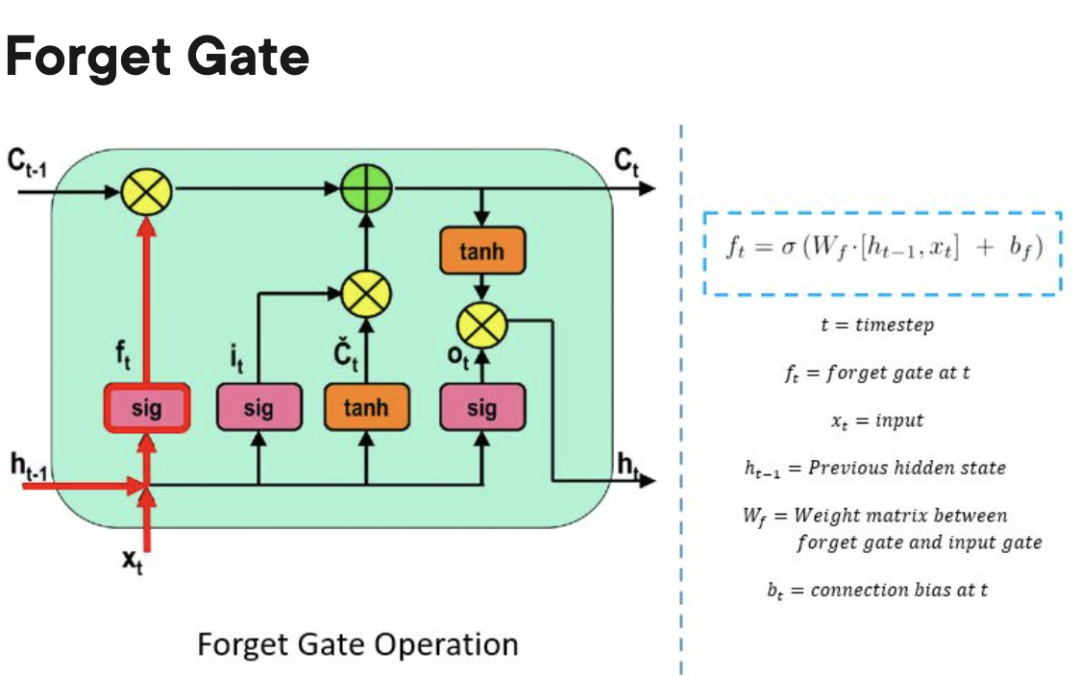
输出门:决定处理单元内存储的信息何时可以用作细胞的输出。
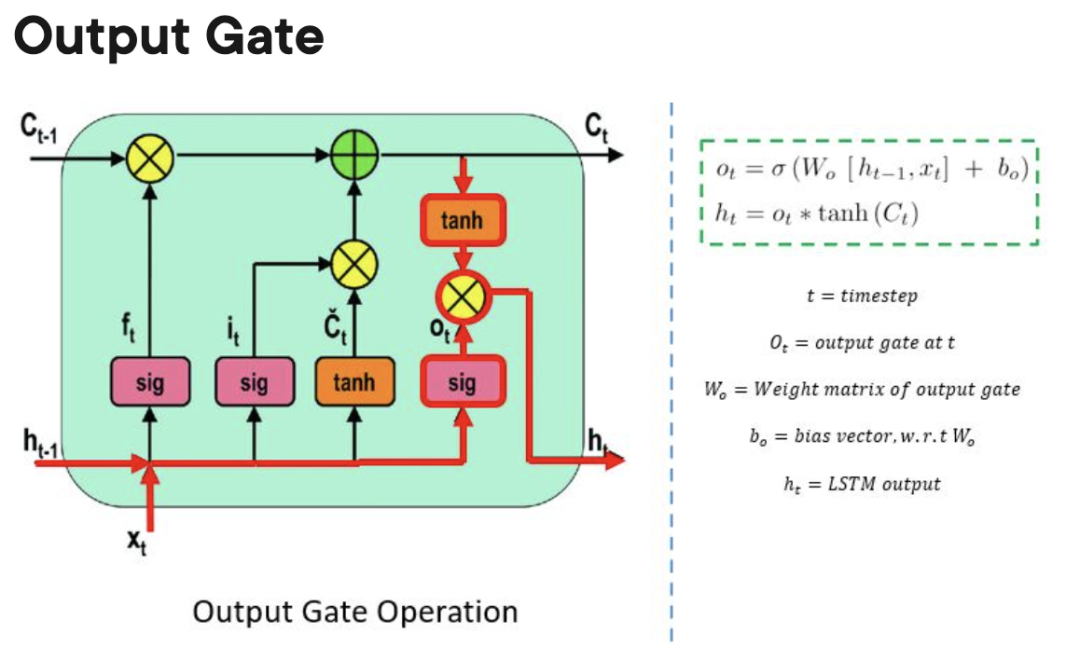
LSTM对比于GRU和RNN的优缺点
相较于GRU和尤其是RNN,LSTM可以学习更长期的依赖关系。由于有三个门(GRU中为两个,RNN中为零),因此与RNN和GRU相比,LSTM具有更多的参数。这些额外的参数允许LSTM模型更好地处理复杂的序列数据,如自然语言或时间序列数据。此外,LSTM还可以处理变长的输入序列,因为它们的门结构允许它们忽略不必要的输入。因此,LSTM在许多应用中都表现出色,包括语音识别、机器翻译和股票市场预测等。
5. 门控循环单元 (GRU)
GRU有两个门:更新门和重置门(本质上是两个向量),以决定应该传递什么信息到输出。
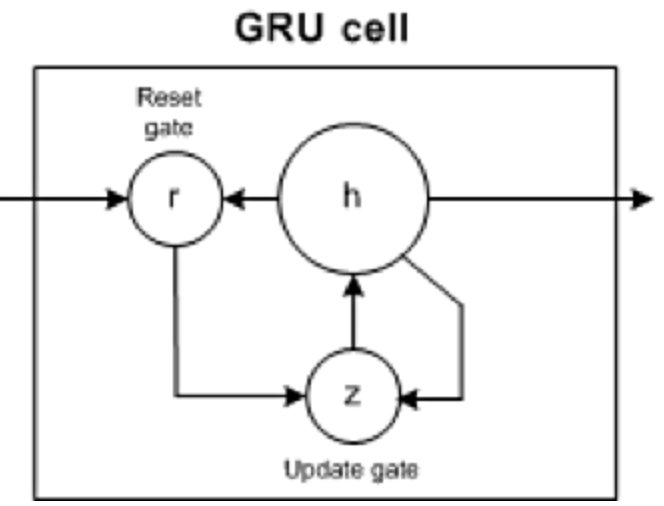
- 重置门(Reset gate): 帮助模型决定可以忘记多少过去的信息。
- 更新门(Update gate): 帮助模型确定过去信息(之前的时间步骤)中有多少需要传递到未来。
GRU对比 LSTM 和RNN的优缺点
与RNN类似,GRU也是一种递归神经网络,它可以有效地长时间保留信息并捕捉比RNN更长的依赖关系。然而,GRU相比较于LSTM更为简单,训练速度更快。
尽管GRU在实现上比RNN更为复杂,但由于其仅包含两个门控机制,因此其参数数量较少,通常不能像LSTM那样捕捉更长范围的依赖关系。因此,GRU在某些情况下可能需要更多的训练数据以达到与LSTM相同的性能水平。
此外,由于GRU相对较为简单,其计算成本也较低,因此在资源有限的环境下,如移动设备或嵌入式系统,使用GRU可能更为合适。另一方面,如果模型的准确性对应用至关重要,则LSTM可能是更好的选择。
6.Transformer
有关 Transformers 的论文 “Attention is All You Need” 几乎是 Arxiv 上有史以来排名第一的论文。变形金刚是一种大型编码器-解码器模型,能够使用复杂的注意力机制处理整个序列。
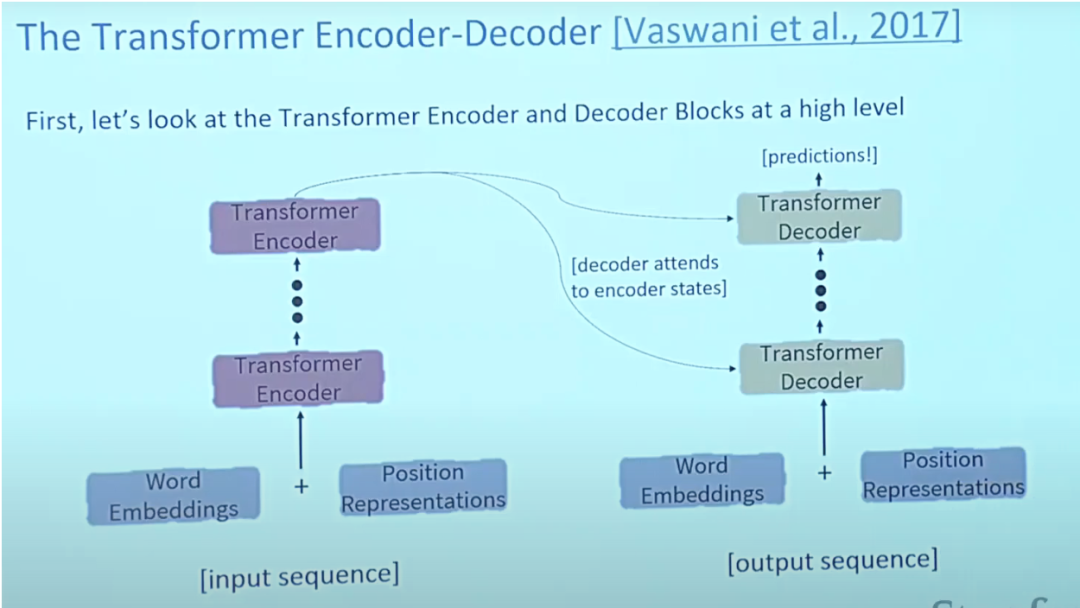
通常,在自然语言处理应用中,首先使用嵌入算法将每个输入单词转换为向量。嵌入只在最底层的编码器中发生。所有编码器共享的抽象是,它们接收一个大小为512的向量列表,这将是词嵌入,但在其他编码器中,它将是直接位于下面的编码器输出中。
注意力提供了解决瓶颈问题的方法。对于这些类型的模型,上下文向量成为了一个瓶颈,这使得模型难以处理长句子。注意力允许模型根据需要集中关注输入序列的相关部分,并将每个单词的表示视为一个查询,以访问和合并一组值中的信息。
6.1 Transformer的架构特点
通常,在Transformer架构中,编码器能够将所有隐藏状态传递给解码器。但是,在生成输出之前,解码器使用注意力进行了额外的步骤。解码器通过其softmax得分乘以每个隐藏状态,从而放大得分更高的隐藏状态并淹没其他隐藏状态。这使得模型能够集中关注与输出相关的输入部分。
自我注意力位于编码器中,第一步是从每个编码器输入向量(每个单词的嵌入)创建3个向量:Key、Query和Value向量,这些向量是通过将嵌入乘以在训练过程中训练的3个矩阵来创建的。K、V、Q维度为64,而嵌入和编码器输入/输出向量的维度为512。下图来自Jay Alammar的 Illustrated Transformer,这可能是网上最好的可视化解读。
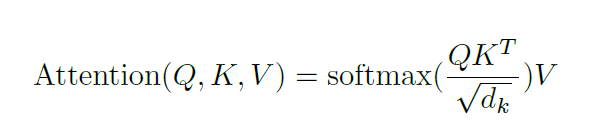
这个列表的大小是可以设置的超参数,基本上将是训练数据集中最长句子的长度。
- 注意力:
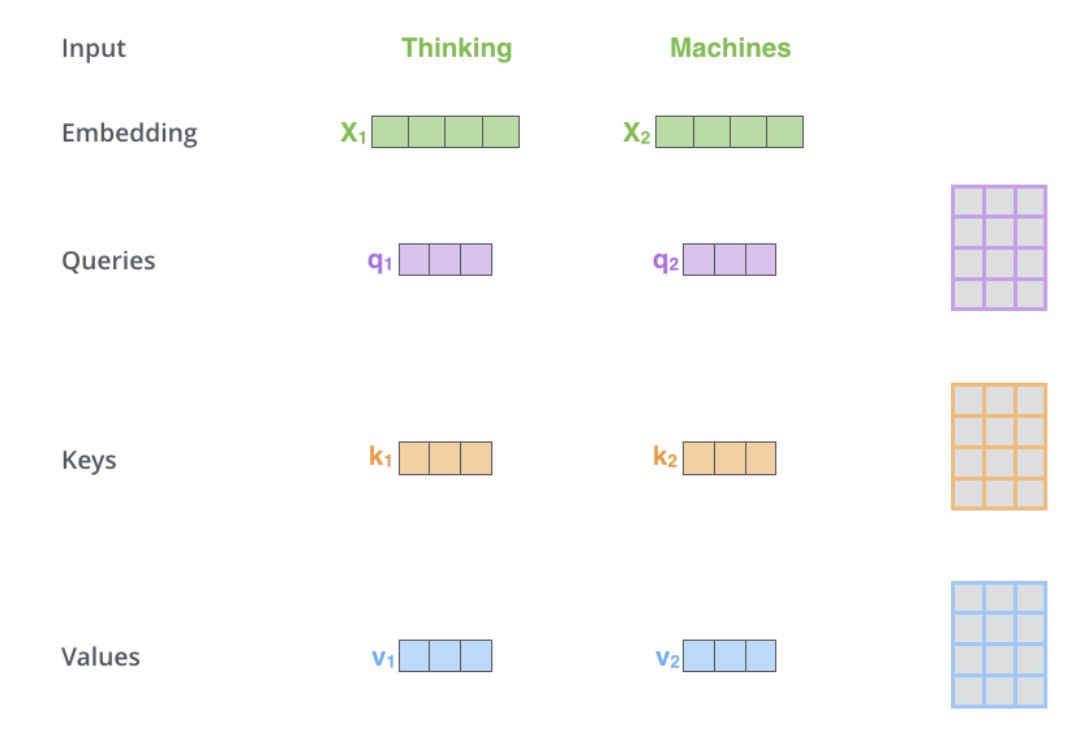
什么是query、key和value向量?它们是在计算和思考注意力时有用的抽象概念。在解码器中的交叉注意力除了输入之外,计算与自注意力的计算相同。交叉注意力不对称地组合了两个维度相同的独立嵌入序列,而自注意力的输入是一个单独的嵌入序列。
为了讨论Transformer,还必须讨论两个预训练模型,即BERT和GPT,因为它们导致了Transformer的成功。
GPT 的预训练解码器有12层,其中包括768维隐藏状态,3072维前馈隐藏层,采用40,000个合并的字节对编码。主要应用在自然语言的推理中,将句子对标记为蕴含、矛盾或中性。
BERT是预训练编码器,使用掩码语言建模,将输入中的一部分单词替换为特殊的[MASK]标记,然后尝试预测这些单词。因此,只需要在预测的掩码单词上计算损失。两种BERT模型大小都有大量的编码器层(该论文称为Transformer块)-Base版本有12个,Large版本有24个。这些也具有比初始论文中Transformer参考实现中的默认配置(6个编码器层,512个隐藏单元和8个注意头)更大的前馈网络(分别为768和1024个隐藏单元)和更多的注意头(分别为12和16)。BERT模型很容易进行微调,通常可以在单个GPU上完成。BERT可以用在NLP中进行翻译,特别是低资源语言翻译。
Transformer的一个性能缺点是,它们在自我关注方面的计算时间是二次的,而RNN只是线性增长。
6.2 Transformer的用例
6.2.1 语言领域
在传统的语言模型中,相邻的单词会首先被分组在一起,而Transformer则能够并行处理,使得输入数据中的每个元素都能够连接或关注到每个其他元素。这被称为“自我注意力”。这意味着Transformer一开始训练时就可以看到整个数据集的内容。
在Transformer出现之前,AI语言任务的进展在很大程度上落后于其他领域的发展。实际上,在过去的10年左右的深度学习革命中,自然语言处理是后来者,而NLP在某种程度上落后于计算机视觉。然而,随着Transformers的出现,NLP领域得到了极大的推动,并且推出了一系列在各种NLP任务中取得佳绩的模型。
例如,为了理解基于传统语言模型(基于递归架构,如RNN、LSTM或GRU)与Transformer之间的区别,我们可以举个例子:“The owl spied a squirrel. It tried to grab it with its talons but only got the end of its tail.”第二个句子的结构很令人困惑:那个“it”是指什么?仅关注“it”周围单词的传统语言模型会遇到困难,但是将每个单词与每个其他单词相连的Transformer可以分辨出猫头鹰抓住了松鼠,而松鼠失去了部分尾巴。
6.2.2 视觉领域
在CNN中,我们从局部开始,逐渐获得全局视角。CNN通过从局部到全局的方式构建特征,逐像素识别图像,以识别例如角落或线条等特征。然而,在transformer中,通过自我注意力,即使在信息处理的第一层上,也会建立远程图像位置之间的连接(就像语言一样)。如果CNN的方法就像从单个像素开始缩放,那么transformer会逐渐将整个模糊的图像聚焦。

CNN通过反复应用输入数据的局部补丁上的滤镜,生成局部特征表示,并逐步增加它们的感受视野并构建全局特征表示。正是因为卷积,照片应用程序才能将梨与云彩区分开来。在transformer架构之前,CNN被认为是视觉任务不可或缺的。
Vision Transformer模型的架构与2017年提出的第一个transformer几乎相同,只有一些微小的变化使其能够分析图像而不是单词。由于语言往往是离散的,因此需要将输入图像离散化,以使transformer能够处理视觉输入。在每个像素上完全模仿语言方法并执行自我关注将计算时间变得极为昂贵。因此,ViT将更大的图像分成方形单元或补丁(类似于NLP中的令牌)。大小是任意的,因为根据原始图像的分辨率,token可以变大或变小(默认为16x16像素)。但是通过处理组中的像素并对每个像素应用自我注意力,ViT可以快速处理巨大的训练数据集,输出越来越准确的分类。
6.2.3 多模态任务
与 Transformer 相比,其他深度学习架构只会一种技巧,而多模态学习需要在一个流畅的架构中处理具有不同模式的模态,并具有相当高的关系归纳偏差,才能达到人类智能的水平。换句话说,需要一个单一多用途的架构,可以无缝地在阅读/观看、说话和听取等感官之间转换。
对于多模态任务,需要同时处理多种类型的数据,如原始图像、视频和语言等,而 Transformer 提供了通用架构的潜力。
由于早期架构中采用的分立方法,每种类型的数据都有自己特定的模型,因此这是一项难以完成的任务。然而,Transformer 提供了一种简单的方法来组合多个输入来源。例如,多模态网络可以为系统提供动力,读取人的嘴唇动作并同时使用语言和图像信息的丰富表示来监听他们的声音。通过交叉注意力,Transformer 能够从不同来源派生查询、键和值向量,成为多模态学习的有力工具。
因此,Transformer 是实现神经网络架构“融合”的一大步,从而可以帮助实现对多种模态数据的通用处理。
6.3 Transformer对比RNN/GRU/LSTM的优缺点
与RNN/GRU/LSTM相比,Transformer可以学习比RNN和其变体(如GRU和LSTM)更长的依赖关系。
然而,最大的好处来自于Transformer如何适用于并行化。与在每个时间步骤处理一个单词的RNN不同,Transformer的一个关键属性是每个位置上的单词都通过自己的路径流经编码器。在自我注意力层中,由于自我注意层计算每个输入序列中的其他单词对该单词的重要性,这些路径之间存在依赖关系。但是,一旦生成了自我注意力输出,前馈层就没有这些依赖关系,因此各个路径可以在通过前馈层时并行执行。这在Transformer编码器的情况下是一个特别有用的特性,它可以在自我注意力层后与其他单词并行处理每个输入单词。然而,这个特性对于解码器并不是非常重要,因为它一次只生成一个单词,不使用并行单词路径。
Transformer架构的运行时间与输入序列的长度呈二次方关系,这意味着当处理长文档或将字符作为输入时,处理速度可能会很慢。换句话说,在进行自我注意力形成期间,需要计算所有交互对,这意味着计算随着序列长度呈二次增长,即O(T^2 d),其中T序列长度,D是维度。例如,对应一个简单的句子d=1000,T≤30⇒T^2≤900⇒T^2d≈900K。而对于循环神经,它仅以线性方式增长。
如果Transformer不需要在句子中的每一对单词之间计算成对的交互作用,那岂不是很好?有研究表明可以在不计算所有单词对之间的交互作用(例如通过近似成对关注)的情况下实现相当高的性能水平。
与CNN相比,Transformer的数据需求极高。CNN仍然具有样本效率,这使它们成为低资源任务的绝佳选择。这对于图像/视频生成任务尤其如此,即使对于CNN架构,需要大量数据(因此暗示Transformer架构需要极高的数据需求)。例如,Radford等人最近提出的CLIP架构是使用基于CNN的ResNets作为视觉骨干进行训练的(而不是类似ViT的Transformer架构)。虽然Transformer在满足其数据需求后提供了准确性提升,但CNN则提供了一种在可用数据量不是异常高的任务中提供良好准确性表现的方式。因此,两种架构都有其用途。
由于Transformer 架构的运行时间与输入序列的长度呈二次方关系。也就是说,在所有单词对上计算注意力需要图中边的数量随节点数呈二次方增长,即在一个 n 个单词的句子中,Transformer 需要计算 n^2 个单词对。这意味着参数数量巨大(即内存占用高),从而导致计算复杂度高。高计算要求对电源和电池寿命都会产生负面影响,特别是对于可移动设备而言。总体而言,为了提供更好的性能(例如准确性),Transformer需要更高的计算能力、更多的数据、电源/电池寿命和内存占用。
7. 推理偏差
实践中使用的每个机器学习算法,从最近邻到梯度提升,都带有自己关于哪些分类更容易学习的归纳偏差。几乎所有学习算法都有一个偏差,即学习那些相似的项(在某些特征空间中“接近”彼此)更可能属于同一类。线性模型,例如逻辑回归,还假设类别可以通过线性边界分离,这是一个“硬”偏差,因为模型无法学习其他内容。即便对于正则化回归,这几乎是机器学习中经常使用的类型,也还存在一种偏差,即倾向于学习涉及少数特征,具有低特征权重的边界,这是“软”偏差,因为模型可以学习涉及许多具有高权重功能的类别边界,但这更困难/需要更多数据。
即使是深度学习模型也同样具有推理偏差,例如,LSTM神经网络对自然语言处理任务非常有效,因为它偏向于在长序列上保留上下文信息。

了解领域知识和问题难度可以帮助我们选择适当的算法应用。例如,从临床记录中提取相关术语以确定患者是否被诊断为癌症的问题。在这种情况下,逻辑回归表现良好,因为有很多独立有信息量的术语。对于其他问题,例如从复杂的PDF报告中提取遗传测试的结果,使用LSTM可以更好地处理每个单词的长程上下文,从而获得更好的性能。一旦选择了基础算法,了解其偏差也可以帮助我们执行特征工程,即选择要输入到学习算法中的信息的过程。
每个模型结构都有一种内在的推理偏差,帮助理解数据中的模式,从而实现学习。例如,CNN表现出空间参数共享、平移/空间不变性,而RNN表现出时间参数共享。
8. 小结
老码农尝试对比分析了深度学习架构中的Transformer、CNN、RNN/GRU/LSTM,理解到Transformer可以学习更长的依赖关系,但需要更高的数据需求和计算能力;Transformer适用于多模态任务,可以无缝地在阅读/观看、说话和听取等感官之间转换;每个模型结构都有一种内在的推理偏差,帮助理解数据中的模式,从而实现学习。
【参考资料】
- CNN vs fully connected network for image recognition?,https://stats.stackexchange.com/questions/341863/cnn-vs-fully-connected-network-for-image-recognition
- https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1184/lectures/lecture12.pdf
- Introduction to LSTM Units in RNN,https://www.pluralsight.com/guides/introduction-to-lstm-units-in-rnn
- Learning Transferable Visual Models From Natural Language Supervision,https://arxiv.org/abs/2103.00020
- Linformer: Self-Attention with Linear Complexity,https://arxiv.org/abs/2006.04768
- Rethinking Attention with Performers,https://arxiv.org/abs/2009.14794
- Big Bird: Transformers for Longer Sequences,https://arxiv.org/abs/2007.14062
- Synthesizer: Rethinking Self-Attention in Transformer Models,https://arxiv.org/abs/2005.00743
- Do Vision Transformers See Like Convolutional Neural Networks?,https://arxiv.org/abs/2108.08810
- Illustrated Transformer,https://jalammar.github.io/illustrated-transformer/
以上是深度学习架构的对比分析的详细内容。更多信息请关注PHP中文网其他相关文章!

![无法使用chatgpt!解释可以立即测试的原因和解决方案[最新2025]](https://img.php.cn/upload/article/001/242/473/174717025174979.jpg?x-oss-process=image/resize,p_40) 无法使用chatgpt!解释可以立即测试的原因和解决方案[最新2025]May 14, 2025 am 05:04 AM
无法使用chatgpt!解释可以立即测试的原因和解决方案[最新2025]May 14, 2025 am 05:04 AMChatGPT无法访问?本文提供多种实用解决方案!许多用户在日常使用ChatGPT时,可能会遇到无法访问或响应缓慢等问题。本文将根据不同情况,逐步指导您解决这些问题。 ChatGPT无法访问的原因及初步排查 首先,我们需要确定问题是出在OpenAI服务器端,还是用户自身网络或设备问题。 请按照以下步骤进行排查: 步骤1:检查OpenAI官方状态 访问OpenAI Status页面 (status.openai.com),查看ChatGPT服务是否正常运行。如果显示红色或黄色警报,则表示Open
 计算ASI的风险始于人类的思想May 14, 2025 am 05:02 AM
计算ASI的风险始于人类的思想May 14, 2025 am 05:02 AM2025年5月10日,麻省理工学院物理学家Max Tegmark告诉《卫报》,AI实验室应在释放人工超级智能之前模仿Oppenheimer的三位一体测试演算。 “我的评估是'康普顿常数',这是一场比赛的可能性
 易于理解的解释如何编写和撰写歌词和推荐工具May 14, 2025 am 05:01 AM
易于理解的解释如何编写和撰写歌词和推荐工具May 14, 2025 am 05:01 AMAI音乐创作技术日新月异,本文将以ChatGPT等AI模型为例,详细讲解如何利用AI辅助音乐创作,并辅以实际案例进行说明。我们将分别介绍如何通过SunoAI、Hugging Face上的AI jukebox以及Python的Music21库进行音乐创作。 通过这些技术,每个人都能轻松创作原创音乐。但需注意,AI生成内容的版权问题不容忽视,使用时务必谨慎。 让我们一起探索AI在音乐领域的无限可能! OpenAI最新AI代理“OpenAI Deep Research”介绍: [ChatGPT]Ope
 什么是chatgpt-4?对您可以做什么,定价以及与GPT-3.5的差异的详尽解释!May 14, 2025 am 05:00 AM
什么是chatgpt-4?对您可以做什么,定价以及与GPT-3.5的差异的详尽解释!May 14, 2025 am 05:00 AMChatGPT-4的出现,极大地拓展了AI应用的可能性。相较于GPT-3.5,ChatGPT-4有了显着提升,它具备强大的语境理解能力,还能识别和生成图像,堪称万能的AI助手。在提高商业效率、辅助创作等诸多领域,它都展现出巨大的潜力。然而,与此同时,我们也必须注意其使用上的注意事项。 本文将详细解读ChatGPT-4的特性,并介绍针对不同场景的有效使用方法。文中包含充分利用最新AI技术的技巧,敬请参考。 OpenAI发布的最新AI代理,“OpenAI Deep Research”详情请点击下方链
 解释如何使用chatgpt应用程序!日本支持和语音对话功能May 14, 2025 am 04:59 AM
解释如何使用chatgpt应用程序!日本支持和语音对话功能May 14, 2025 am 04:59 AMCHATGPT应用程序:与AI助手释放您的创造力!初学者指南 ChatGpt应用程序是一位创新的AI助手,可处理各种任务,包括写作,翻译和答案。它是一种具有无限可能性的工具,可用于创意活动和信息收集。 在本文中,我们将以一种易于理解的方式解释初学者,从如何安装chatgpt智能手机应用程序到语音输入功能和插件等应用程序所独有的功能,以及在使用该应用时要牢记的要点。我们还将仔细研究插件限制和设备对设备配置同步
 如何使用中文版Chatgpt?注册程序和费用的说明May 14, 2025 am 04:56 AM
如何使用中文版Chatgpt?注册程序和费用的说明May 14, 2025 am 04:56 AMChatGPT中文版:解锁中文AI对话新体验 ChatGPT风靡全球,您知道它也提供中文版本吗?这款强大的AI工具不仅支持日常对话,还能处理专业内容,并兼容简体中文和繁体中文。无论是中国地区的使用者,还是正在学习中文的朋友,都能从中受益。 本文将详细介绍ChatGPT中文版的使用方法,包括账户设置、中文提示词输入、过滤器的使用、以及不同套餐的选择,并分析潜在风险及应对策略。此外,我们还将对比ChatGPT中文版和其他中文AI工具,帮助您更好地了解其优势和应用场景。 OpenAI最新发布的AI智能
 5 AI代理神话,您需要停止相信May 14, 2025 am 04:54 AM
5 AI代理神话,您需要停止相信May 14, 2025 am 04:54 AM这些可以将其视为生成AI领域的下一个飞跃,这为我们提供了Chatgpt和其他大型语言模型聊天机器人。他们可以代表我们采取行动,而不是简单地回答问题或产生信息
 易于理解使用Chatgpt创建和管理多个帐户的非法性的解释May 14, 2025 am 04:50 AM
易于理解使用Chatgpt创建和管理多个帐户的非法性的解释May 14, 2025 am 04:50 AM使用chatgpt有效的多个帐户管理技术|关于如何使用商业和私人生活的详尽解释! Chatgpt在各种情况下都使用,但是有些人可能担心管理多个帐户。本文将详细解释如何为ChatGpt创建多个帐户,使用时该怎么做以及如何安全有效地操作它。我们还介绍了重要的一点,例如业务和私人使用差异,并遵守OpenAI的使用条款,并提供指南,以帮助您安全地利用多个帐户。 Openai


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

禅工作室 13.0.1
功能强大的PHP集成开发环境

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

