



准备
当你在浏览器中输入网址(例如www.coder.com)并且敲了回车以后, 浏览器首先要做的事情就是获得coder.com的IP地址,具体的做法就是发送一个UDP的包给DNS服务器,DNS服务器会返回coder.com的IP, 这时候浏览器通常会把IP地址给缓存起来,这样下次访问就会加快。
比如Chrome, 你可以通过chrome://net-internals/#dns来查看。
有了服务器的IP, 浏览器就要可以发起HTTP请求了,但是HTTP Request/Response必须在TCP这个“虚拟的连接”上来发送和接收。
想要建立“虚拟的”TCP连接,TCP邮差需要知道4个东西:(本机IP, 本机端口,服务器IP, 服务器端口),现在只知道了本机IP,服务器IP, 两个端口怎么办?
本机端口很简单,操作系统可以给浏览器随机分配一个, 服务器端口更简单,用的是一个“众所周知”的端口,HTTP服务就是80, 我们直接告诉TCP邮差就行。
经过三次握手以后,客户端和服务器端的TCP连接就建立起来了! 终于可以发送HTTP请求了。

之所以把TCP连接画成虚线,是因为这个连接是虚拟的
Web服务器
一个HTTP GET请求经过千山万水,历经多个路由器的转发,终于到达服务器端(HTTP数据包可能被下层进行分片传输,略去不表)。
Web服务器需要着手处理了,它有三种方式来处理:
(1) 可以用一个线程来处理所有请求,同一时刻只能处理一个,这种结构易于实现,但是这样会造成严重的性能问题。
(2) 可以为每个请求分配一个进程/线程,但是当连接太多的时候,服务器端的进程/线程会耗费大量内存资源,进程/线程的切换也会让CPU不堪重负。
(3) 复用I/O的方式,很多Web服务器都采用了复用结构,例如通过epoll的方式监视所有的连接,当连接的状态发生变化(如有数据可读), 才用一个进程/线程对那个连接进行处理,处理完以后继续监视,等待下次状态变化。 用这种方式可以用少量的进程/线程应对成千上万的连接请求。
我们使用Nginx这个非常流行的Web服务器来继续下面的故事。
对于HTTP GET请求,Nginx利用epoll的方式给读取了出来, Nginx接下来要判断,这是个静态的请求还是个动态的请求啊?
如果是静态的请求(HTML文件,JavaScript文件,CSS文件,图片等),也许自己就能搞定了(当然依赖于Nginx配置,可能转发到别的缓存服务器去),读取本机硬盘上的相关文件,直接返回。
如果是动态的请求,需要后端服务器(如Tomcat)处理以后才能返回,那就需要向Tomcat转发,如果后端的Tomcat还不止一个,那就需要按照某种策略选取一个。
例如Ngnix支持这么几种:
轮询:按照次序挨个向后端服务器转发
权重:给每个后端服务器指定一个权重,相当于向后端服务器转发的几率。
ip_hash: 根据ip做一个hash操作,然后找个服务器转发,这样的话同一个客户端ip总是会转发到同一个后端服务器。
fair:根据后端服务器的响应时间来分配请求,响应时间段的优先分配。
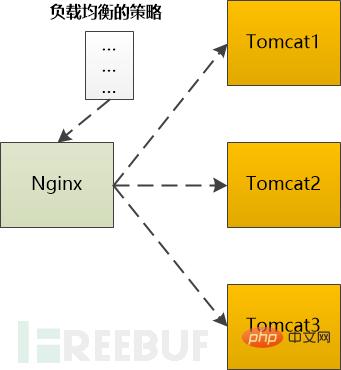
不管用哪种算法,某个后端服务器最终被选中,然后Nginx需要把HTTP Request转发给后端的Tomcat,并且把Tomcat输出的HttpResponse再转发给浏览器。
由此可见,Nginx在这种场景下,是一个代理人的角色。

应用服务器
Http Request终于来到了Tomcat,这是一个由Java写的、可以处理Servlet/JSP的容器,我们的代码就运行在这个容器之中。
如同Web服务器一样, Tomcat也可能为每个请求分配一个线程去处理,即通常所说的BIO模式(Blocking I/O 模式)。
也可能使用I/O多路复用技术,仅仅使用若干线程来处理所有请求,即NIO模式。
不管用哪种方式,Http Request 都会被交给某个Servlet处理,这个Servlet又会把Http Request做转换,变成框架所使用的参数格式,然后分发给某个Controller(如果你是在用Spring)或者Action(如果你是在Struts)。
剩下的故事就比较简单了(不,对码农来说,其实是最复杂的部分),就是执行码农经常写的增删改查逻辑,在这个过程中很有可能和缓存、数据库等后端组件打交道,最终返回HTTP Response,由于细节依赖业务逻辑,略去不表。
根据我们的例子,这个HTTP Response应该是一个HTML页面。
归途
Tomcat很高兴地把Http Response发给了Ngnix 。
Ngnix也很高兴地把Http Response 发给了浏览器。

发完以后TCP连接能关闭吗?
如果使用的是HTTP1.1, 这个连接默认是keep-alive,也就是说不能关闭;
如果是HTTP1.0,要看看之前的HTTP Request Header中有没有Connetion:keep-alive,如果有,那也不能关闭。
浏览器再次工作
浏览器收到了Http Response,从其中读取了HTML页面,开始准备显示这个页面。
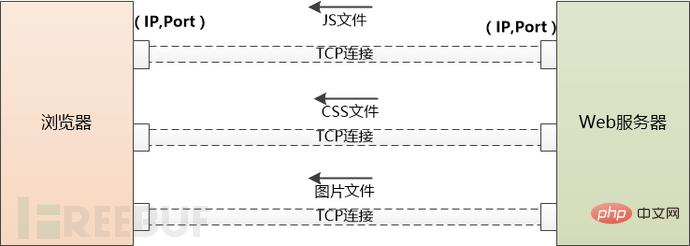
但是这个HTML页面中可能引用了大量其他资源,例如js文件,CSS文件,图片等,这些资源也位于服务器端,并且可能位于另外一个域名下面,例如static.coder.com。
浏览器没有办法,只好一个个地下载,从使用DNS获取IP开始,之前做过的事情还要再来一遍。不同之处在于不会再有应用服务器如Tomcat的介入了。
如果需要下载的外部资源太多,浏览器会创建多个TCP连接,并行地去下载。
但是同一时间对同一域名下的请求数量也不能太多,要不然服务器访问量太大,受不了。所以浏览器要限制一下, 例如Chrome在Http1.1下只能并行地下载6个资源。
当服务器给浏览器发送JS,CSS这些文件时,会告诉浏览器这些文件什么时候过期(使用Cache-Control或者Expire),浏览器可以把文件缓存到本地,当第二次请求同样的文件时,如果不过期,直接从本地取就可以了。
如果过期了,浏览器就可以询问服务器端,文件有没有修改过?(依据是上一次服务器发送的Last-Modified和ETag),如果没有修改过(304 Not Modified),还可以使用缓存。否则的话服务器就会被最新的文件发回到浏览器。
当然如果你按了Ctrl+F5,会强制地发出GET请求,完全无视缓存。
注:在Chrome下,可以通过 chrome://view-http-cache/ 命令来查看缓存。
现在浏览器得到了三个重要的东西:
1.HTML ,浏览器把它变成DOM Tree
2. CSS, 浏览器把它变成CSS Rule Tree
3. JavaScript, 它可以修改DOM Tree
浏览器会通过DOM Tree和CSS Rule Tree生成所谓“Render Tree”,计算每个元素的位置/大小,进行布局,然后调用操作系统的API进行绘制,这是一个非常复杂的过程,略去不表。
到目前为止,我们终于在浏览器中看到了www.coder.com的内容。
以上是从输入网址到最后浏览器呈现页面内容的流程分析的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

WebStorm Mac版
好用的JavaScript开发工具

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

Atom编辑器mac版下载
最流行的的开源编辑器

